 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022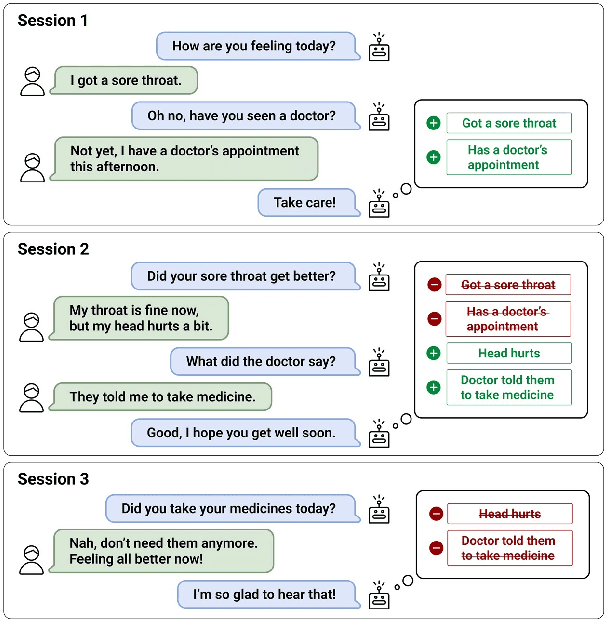
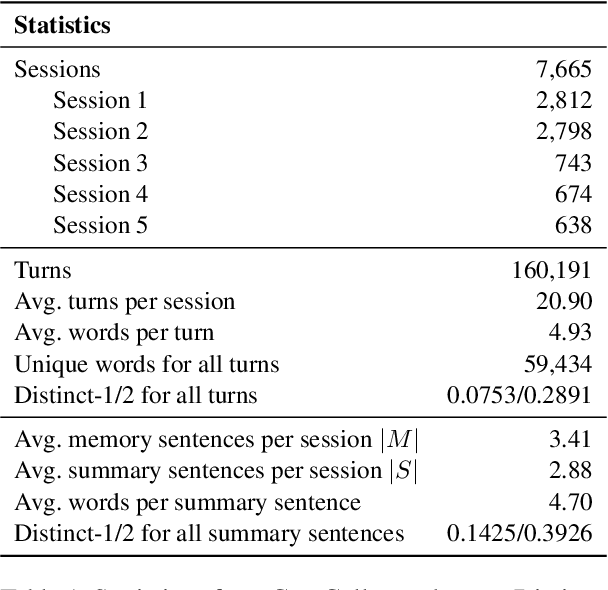
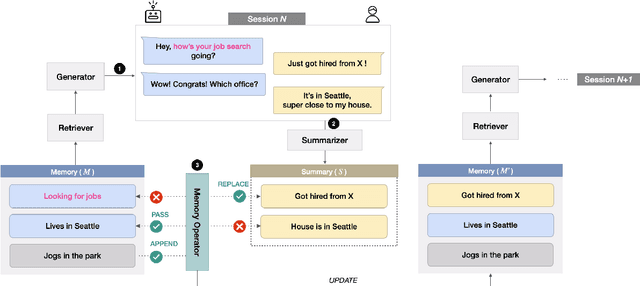
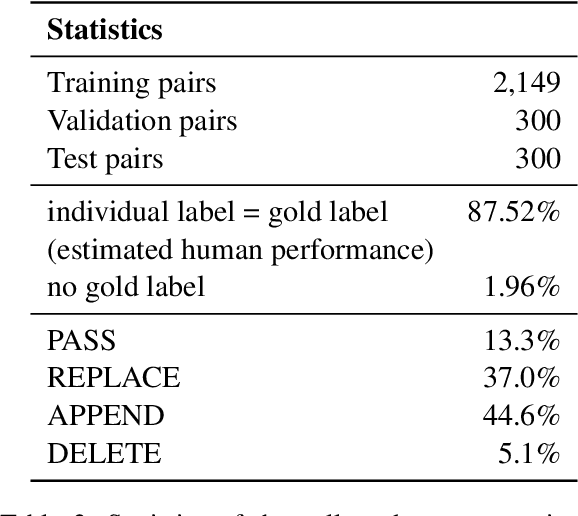
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022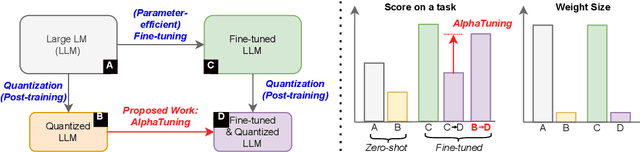

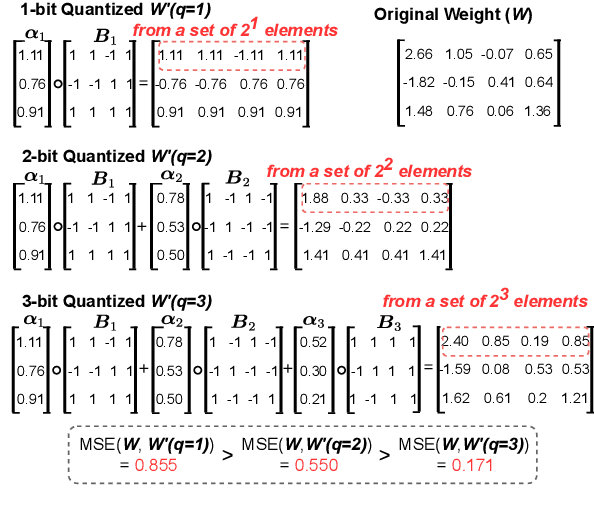
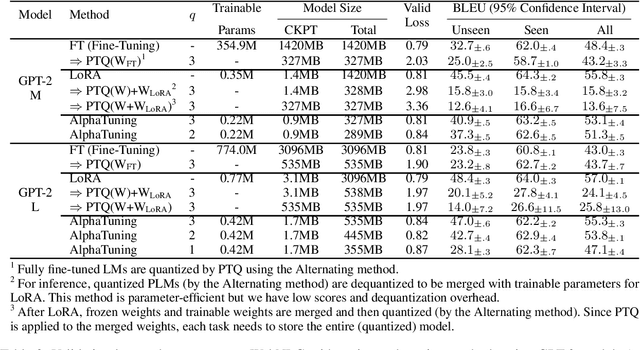
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
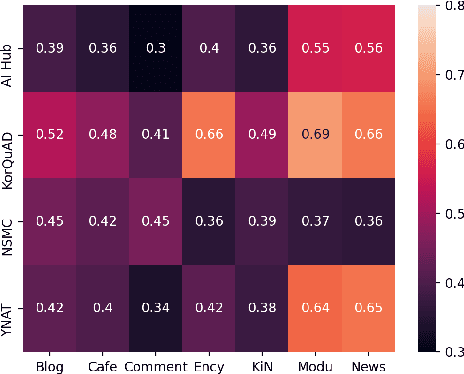
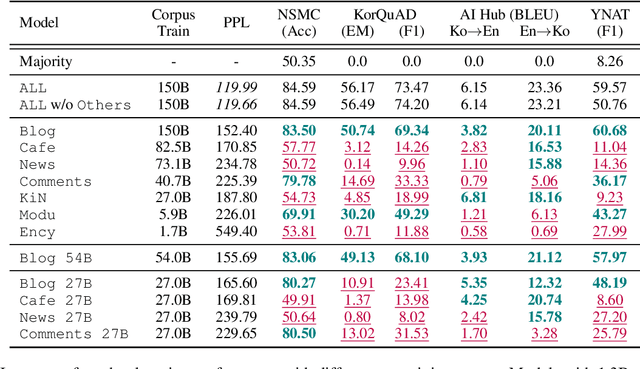
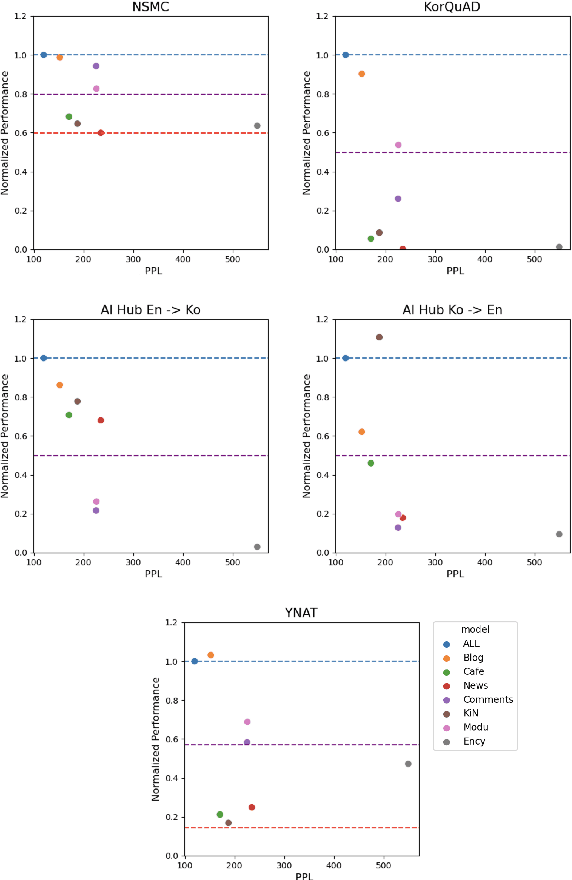
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

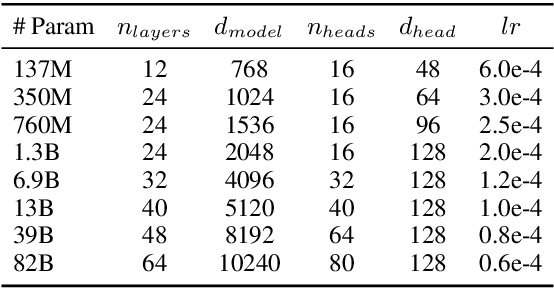
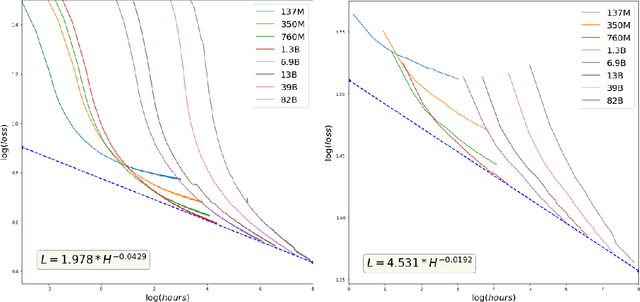
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
CareCall: a Call-Based Active Monitoring Dialog Agent for Managing COVID-19 Pandemic
Jul 06, 2020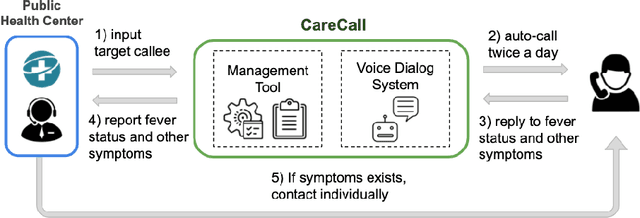
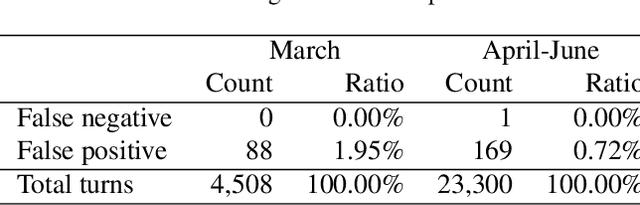
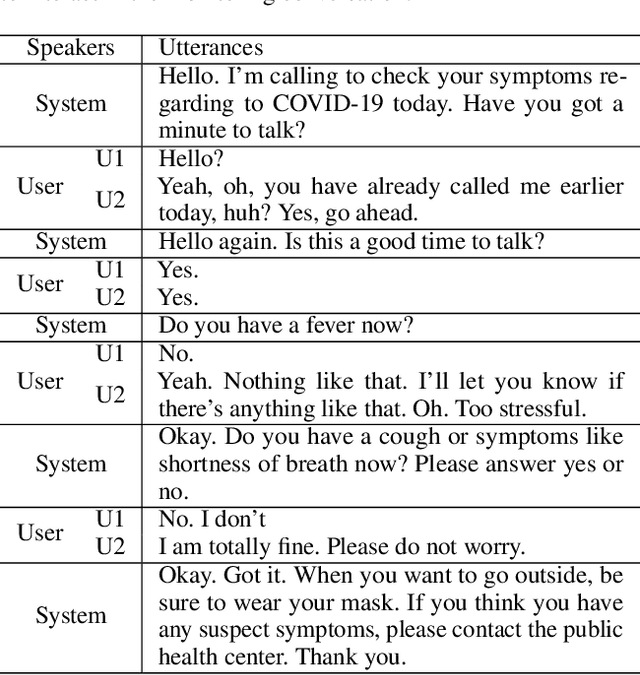
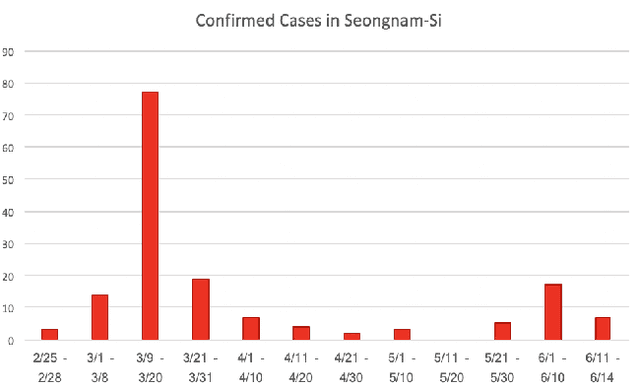
Tracking suspected cases of COVID-19 is crucial to suppressing the spread of COVID-19 pandemic. Active monitoring and proactive inspection are indispensable to mitigate COVID-19 spread, though these require considerable social and economic expense. To address this issue, we introduce CareCall, a call-based dialog agent which is deployed for active monitoring in Korea and Japan. We describe our system with a case study with statistics to show how the system works. Finally, we discuss a simple idea which uses CareCall to support proactive inspection.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
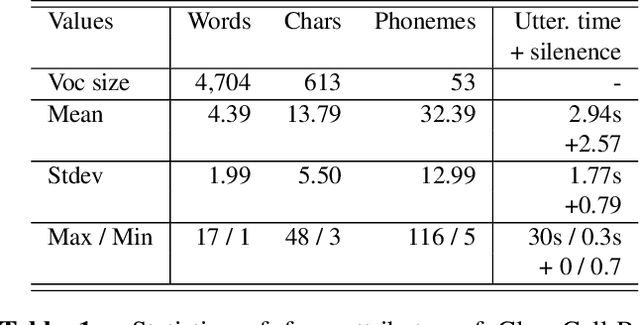
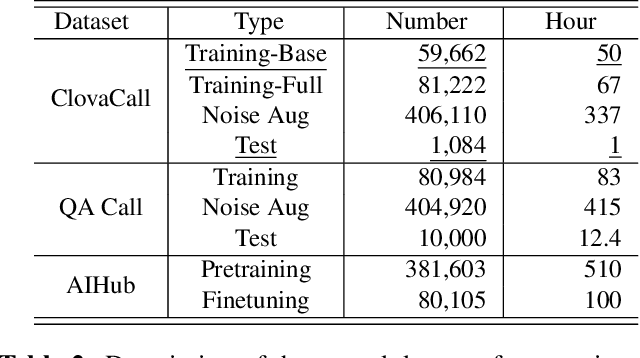
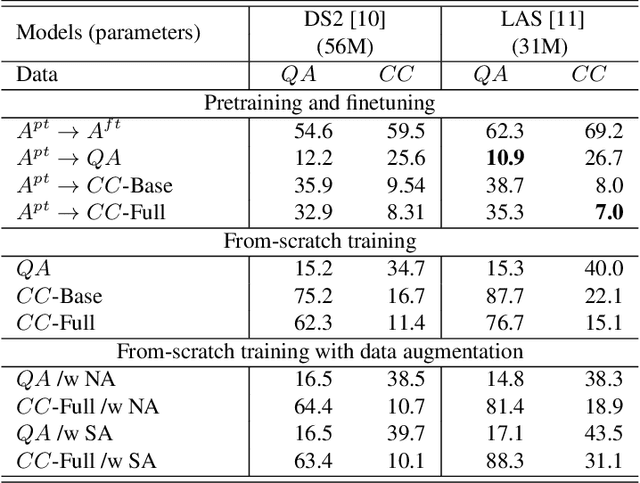
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Tripartite Heterogeneous Graph Propagation for Large-scale Social Recommendation
Jul 24, 2019
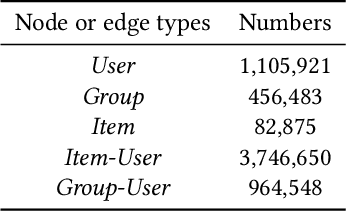
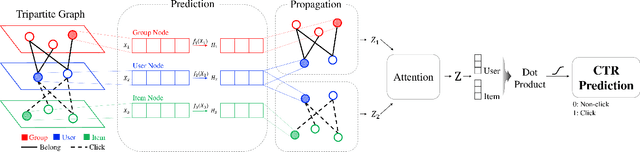

Graph Neural Networks (GNNs) have been emerging as a promising method for relational representation including recommender systems. However, various challenging issues of social graphs hinder the practical usage of GNNs for social recommendation, such as their complex noisy connections and high heterogeneity. The oversmoothing of GNNs is an obstacle of GNN-based social recommendation as well. Here we propose a new graph embedding method Heterogeneous Graph Propagation (HGP) to tackle these issues. HGP uses a group-user-item tripartite graph as input to reduce the number of edges and the complexity of paths in a social graph. To solve the oversmoothing issue, HGP embeds nodes under a personalized PageRank based propagation scheme, separately for group-user graph and user-item graph. Node embeddings from each graph are integrated using an attention mechanism. We evaluate our HGP on a large-scale real-world dataset consisting of 1,645,279 nodes and 4,711,208 edges. The experimental results show that HGP outperforms several baselines in terms of AUC and F1-score metrics.
CHOPT : Automated Hyperparameter Optimization Framework for Cloud-Based Machine Learning Platforms
Oct 16, 2018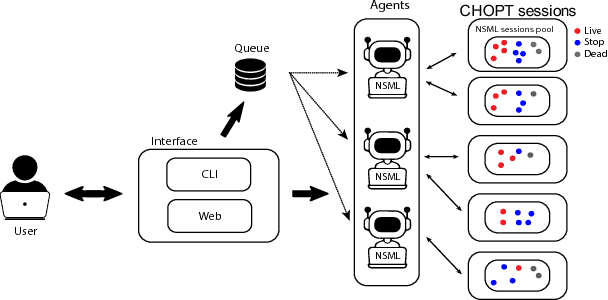
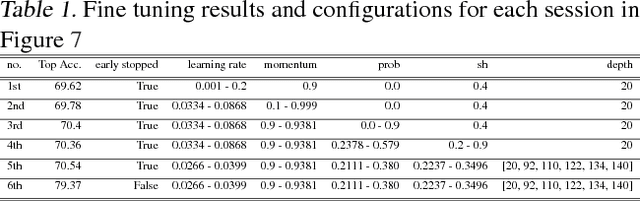
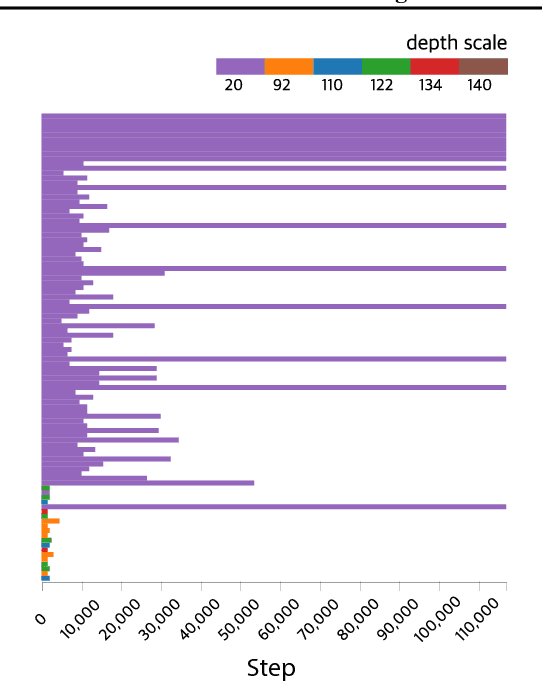

Many hyperparameter optimization (HyperOpt) methods assume restricted computing resources and mainly focus on enhancing performance. Here we propose a novel cloud-based HyperOpt (CHOPT) framework which can efficiently utilize shared computing resources while supporting various HyperOpt algorithms. We incorporate convenient web-based user interfaces, visualization, and analysis tools, enabling users to easily control optimization procedures and build up valuable insights with an iterative analysis procedure. Furthermore, our framework can be incorporated with any cloud platform, thus complementarily increasing the efficiency of conventional deep learning frameworks. We demonstrate applications of CHOPT with tasks such as image recognition and question-answering, showing that our framework can find hyperparameter configurations competitive with previous work. We also show CHOPT is capable of providing interesting observations through its analysing tools
NSML: Meet the MLaaS platform with a real-world case study
Oct 08, 2018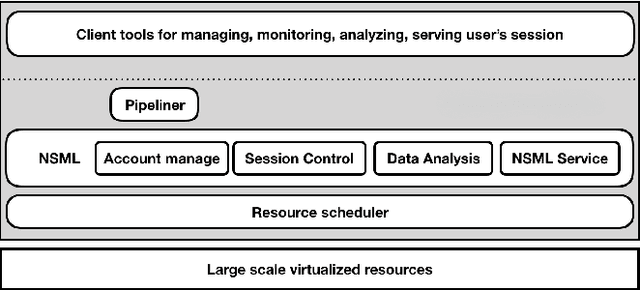
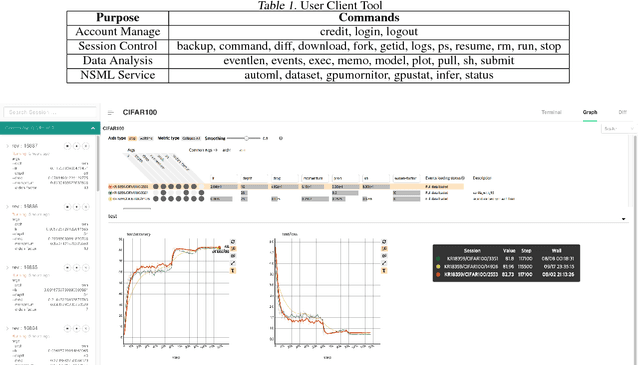
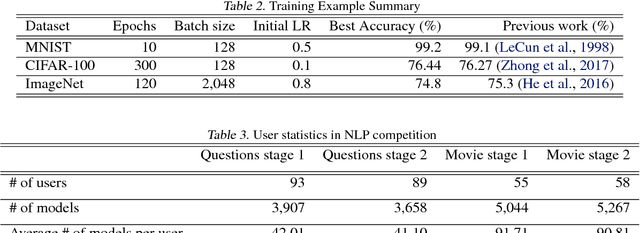
The boom of deep learning induced many industries and academies to introduce machine learning based approaches into their concern, competitively. However, existing machine learning frameworks are limited to sufficiently fulfill the collaboration and management for both data and models. We proposed NSML, a machine learning as a service (MLaaS) platform, to meet these demands. NSML helps machine learning work be easily launched on a NSML cluster and provides a collaborative environment which can afford development at enterprise scale. Finally, NSML users can deploy their own commercial services with NSML cluster. In addition, NSML furnishes convenient visualization tools which assist the users in analyzing their work. To verify the usefulness and accessibility of NSML, we performed some experiments with common examples. Furthermore, we examined the collaborative advantages of NSML through three competitions with real-world use cases.