 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Difficulty Filtering for Reasoning Oriented Reinforcement Learning
Apr 04, 2025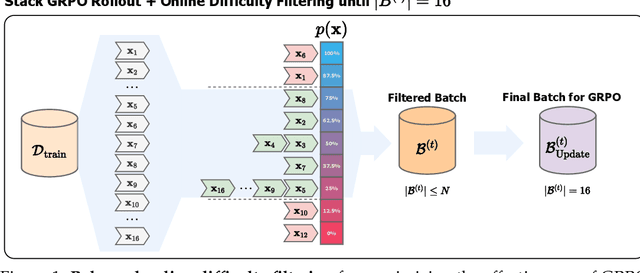
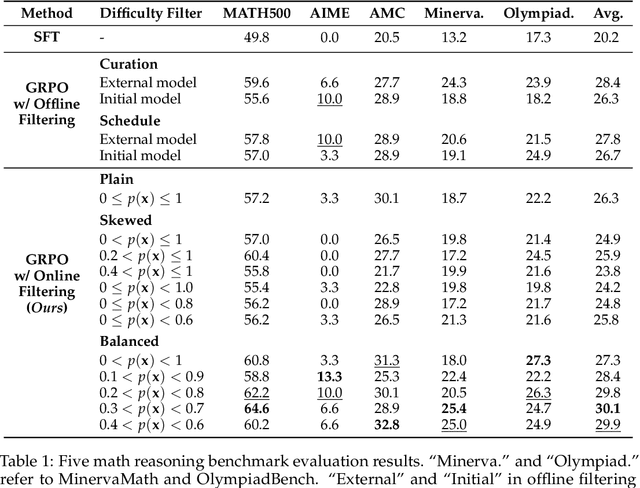
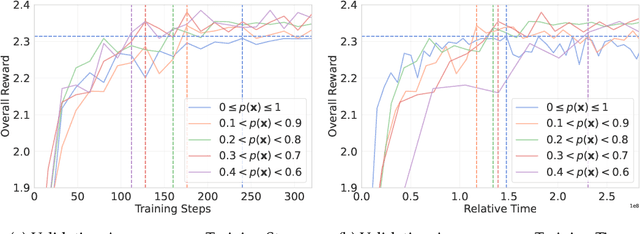
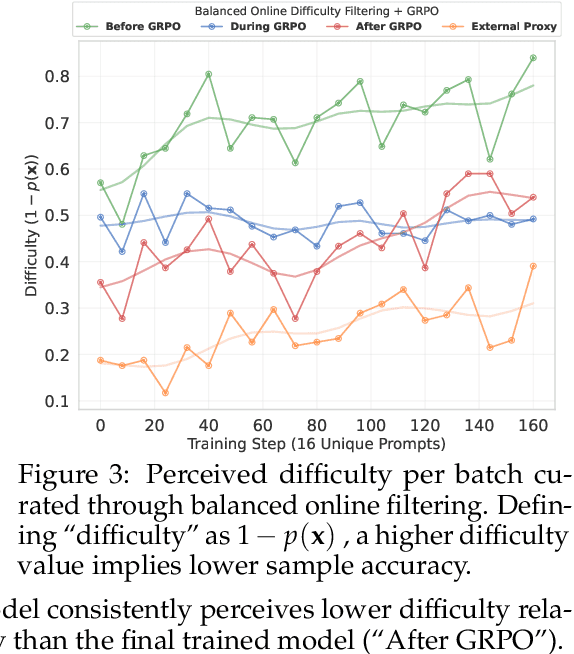
Reasoning-Oriented Reinforcement Learning (RORL) enhances the reasoning ability of Large Language Models (LLMs). However, due to the sparsity of rewards in RORL, effective training is highly dependent on the selection of problems of appropriate difficulty. Although curriculum learning attempts to address this by adjusting difficulty, it often relies on static schedules, and even recent online filtering methods lack theoretical grounding and a systematic understanding of their effectiveness. In this work, we theoretically and empirically show that curating the batch with the problems that the training model achieves intermediate accuracy on the fly can maximize the effectiveness of RORL training, namely balanced online difficulty filtering. We first derive that the lower bound of the KL divergence between the initial and the optimal policy can be expressed with the variance of the sampled accuracy. Building on those insights, we show that balanced filtering can maximize the lower bound, leading to better performance. Experimental results across five challenging math reasoning benchmarks show that balanced online filtering yields an additional 10% in AIME and 4% improvements in average over plain GRPO. Moreover, further analysis shows the gains in sample efficiency and training time efficiency, exceeding the maximum reward of plain GRPO within 60% training time and the volume of the training set.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Building Multimodal AI Chatbots
Apr 21, 2023



This work aims to create a multimodal AI system that chats with humans and shares relevant photos. While earlier works were limited to dialogues about specific objects or scenes within images, recent works have incorporated images into open-domain dialogues. However, their response generators are unimodal, accepting text input but no image input, thus prone to generating responses contradictory to the images shared in the dialogue. Therefore, this work proposes a complete chatbot system using two multimodal deep learning models: an image retriever that understands texts and a response generator that understands images. The image retriever, implemented by ViT and BERT, selects the most relevant image given the dialogue history and a database of images. The response generator, implemented by ViT and GPT-2/DialoGPT, generates an appropriate response given the dialogue history and the most recently retrieved image. The two models are trained and evaluated on PhotoChat, an open-domain dialogue dataset in which a photo is shared in each session. In automatic evaluation, the proposed image retriever outperforms existing baselines VSE++ and SCAN with Recall@1/5/10 of 0.1/0.3/0.4 and MRR of 0.2 when ranking 1,000 images. The proposed response generator also surpasses the baseline Divter with PPL of 16.9, BLEU-1/2 of 0.13/0.03, and Distinct-1/2 of 0.97/0.86, showing a significant improvement in PPL by -42.8 and BLEU-1/2 by +0.07/0.02. In human evaluation with a Likert scale of 1-5, the complete multimodal chatbot system receives higher image-groundedness of 4.3 and engagingness of 4.3, along with competitive fluency of 4.1, coherence of 3.9, and humanness of 3.1, when compared to other chatbot variants. The source code is available at: https://github.com/minniie/multimodal_chat.git.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022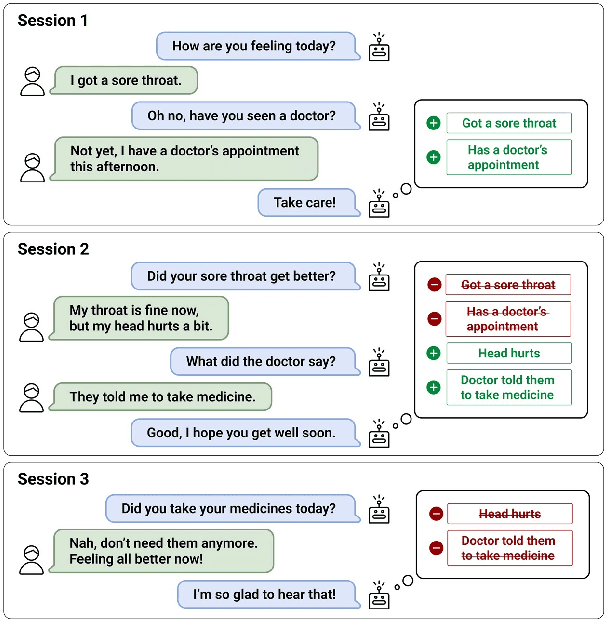
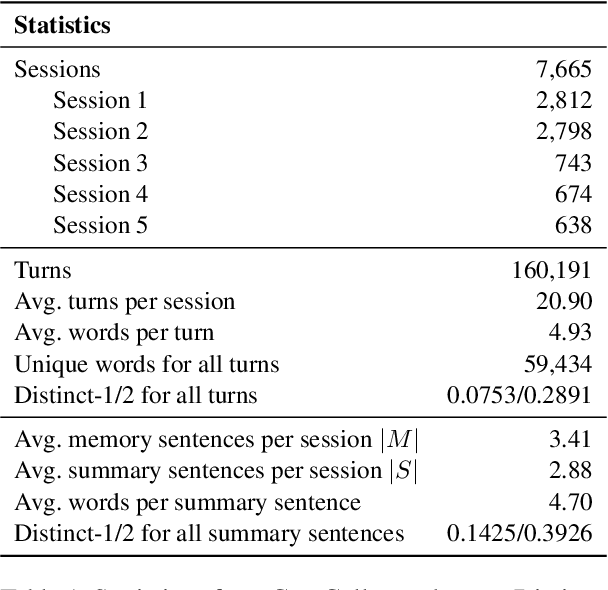
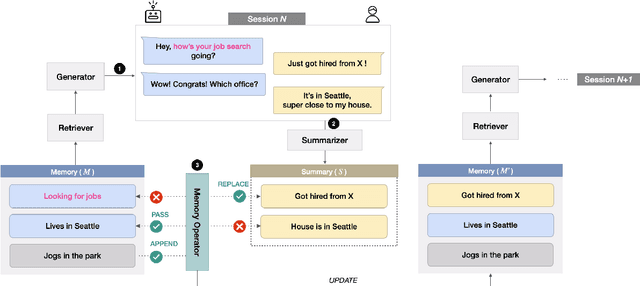
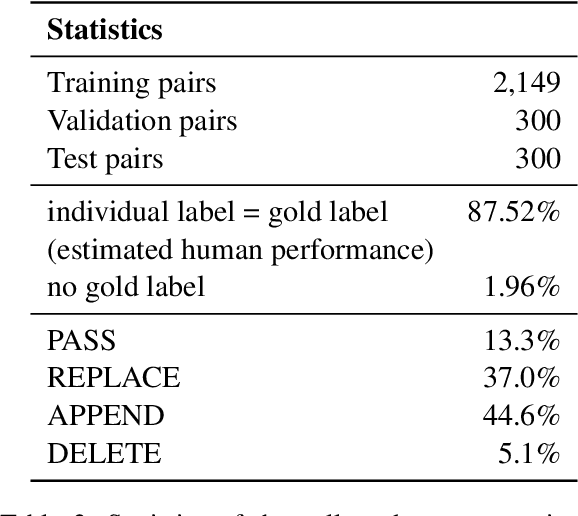
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

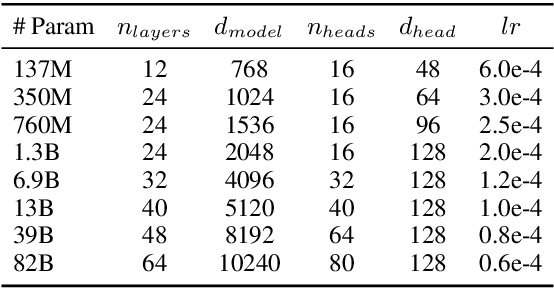
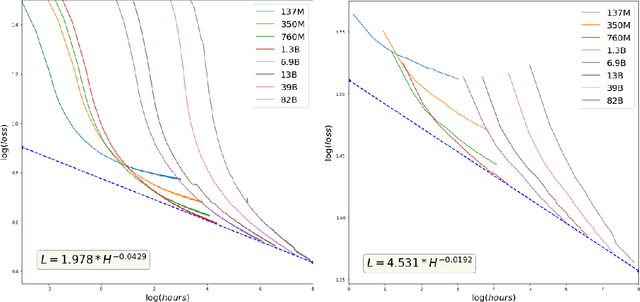
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.