 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Long-Term Typhoon Trajectory Prediction: A Physics-Conditioned Approach Without Reanalysis Data
Jan 28, 2024In the face of escalating climate changes, typhoon intensities and their ensuing damage have surged. Accurate trajectory prediction is crucial for effective damage control. Traditional physics-based models, while comprehensive, are computationally intensive and rely heavily on the expertise of forecasters. Contemporary data-driven methods often rely on reanalysis data, which can be considered to be the closest to the true representation of weather conditions. However, reanalysis data is not produced in real-time and requires time for adjustment because prediction models are calibrated with observational data. This reanalysis data, such as ERA5, falls short in challenging real-world situations. Optimal preparedness necessitates predictions at least 72 hours in advance, beyond the capabilities of standard physics models. In response to these constraints, we present an approach that harnesses real-time Unified Model (UM) data, sidestepping the limitations of reanalysis data. Our model provides predictions at 6-hour intervals for up to 72 hours in advance and outperforms both state-of-the-art data-driven methods and numerical weather prediction models. In line with our efforts to mitigate adversities inflicted by \rthree{typhoons}, we release our preprocessed \textit{PHYSICS TRACK} dataset, which includes ERA5 reanalysis data, typhoon best-track, and UM forecast data.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022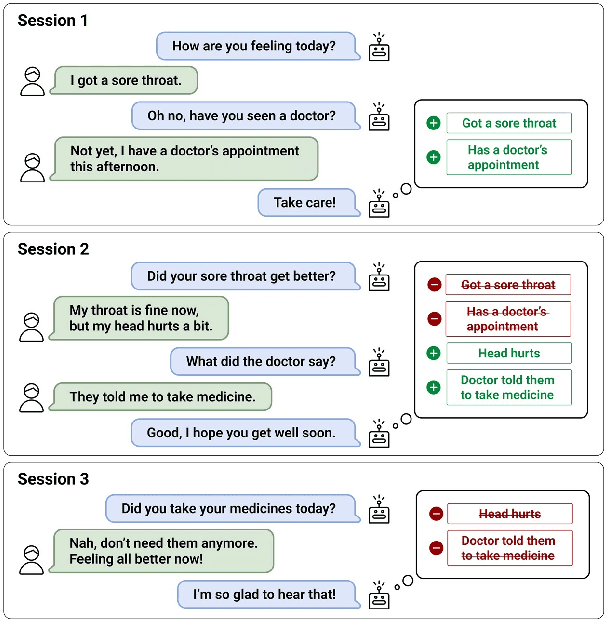
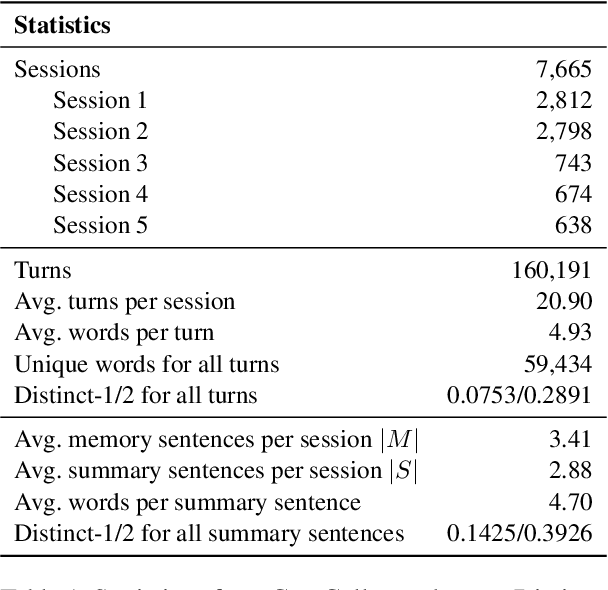
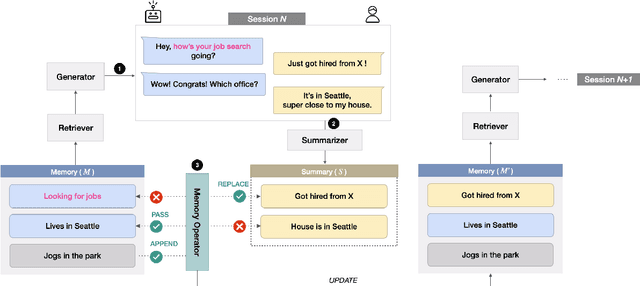
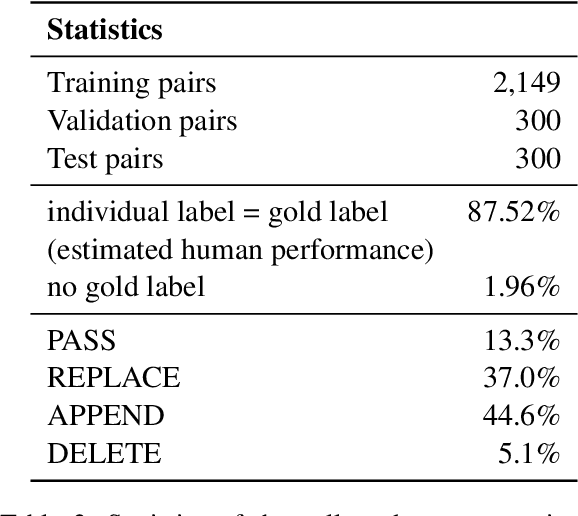
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.