 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-based Product Collections for E-commerce using Pretrained Language Models
Oct 15, 2021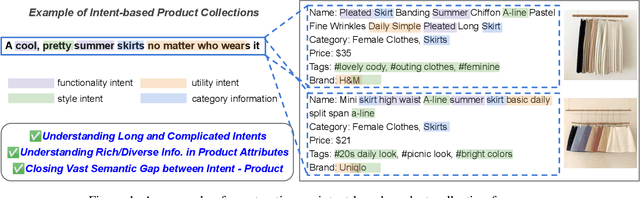
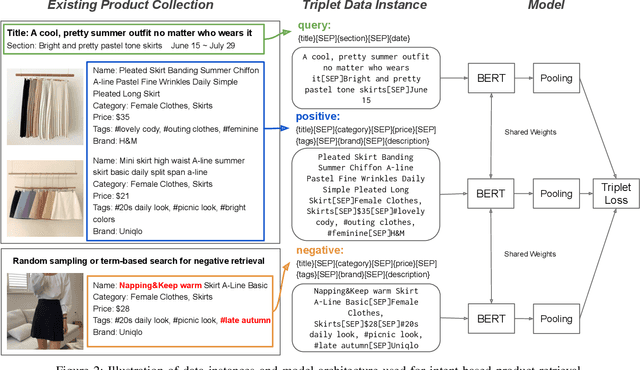
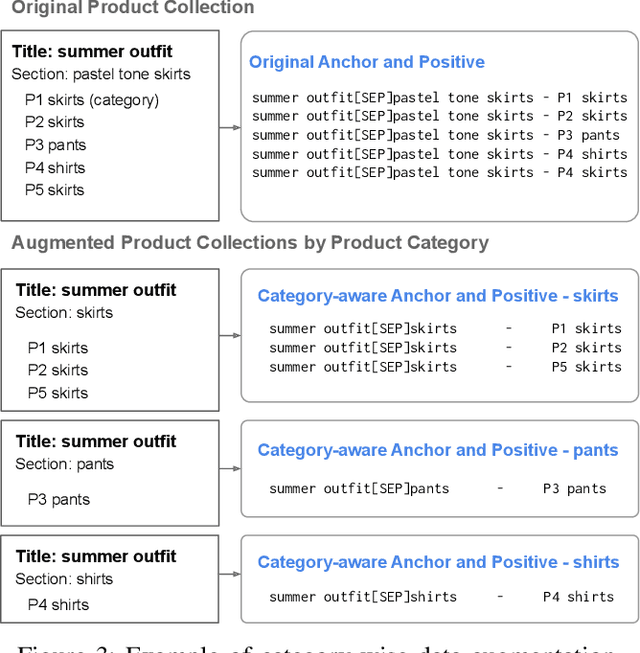
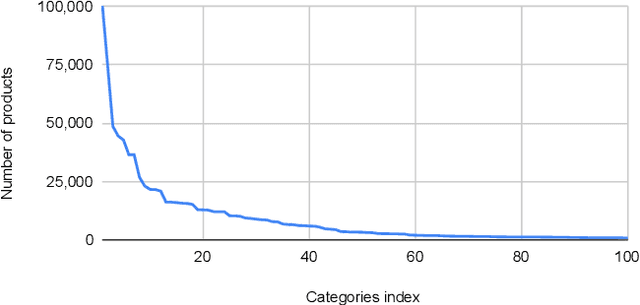
Building a shopping product collection has been primarily a human job. With the manual efforts of craftsmanship, experts collect related but diverse products with common shopping intent that are effective when displayed together, e.g., backpacks, laptop bags, and messenger bags for freshman bag gifts. Automatically constructing a collection requires an ML system to learn a complex relationship between the customer's intent and the product's attributes. However, there have been challenging points, such as 1) long and complicated intent sentences, 2) rich and diverse product attributes, and 3) a huge semantic gap between them, making the problem difficult. In this paper, we use a pretrained language model (PLM) that leverages textual attributes of web-scale products to make intent-based product collections. Specifically, we train a BERT with triplet loss by setting an intent sentence to an anchor and corresponding products to positive examples. Also, we improve the performance of the model by search-based negative sampling and category-wise positive pair augmentation. Our model significantly outperforms the search-based baseline model for intent-based product matching in offline evaluations. Furthermore, online experimental results on our e-commerce platform show that the PLM-based method can construct collections of products with increased CTR, CVR, and order-diversity compared to expert-crafted collections.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

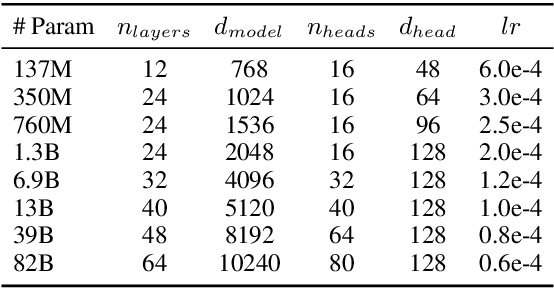
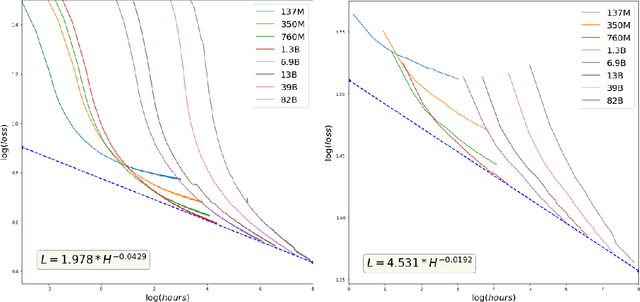
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.