 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-to-Text Benchmark '24: Lessons Learned
Dec 23, 2024

Speech brain-computer interfaces aim to decipher what a person is trying to say from neural activity alone, restoring communication to people with paralysis who have lost the ability to speak intelligibly. The Brain-to-Text Benchmark '24 and associated competition was created to foster the advancement of decoding algorithms that convert neural activity to text. Here, we summarize the lessons learned from the competition ending on June 1, 2024 (the top 4 entrants also presented their experiences in a recorded webinar). The largest improvements in accuracy were achieved using an ensembling approach, where the output of multiple independent decoders was merged using a fine-tuned large language model (an approach used by all 3 top entrants). Performance gains were also found by improving how the baseline recurrent neural network (RNN) model was trained, including by optimizing learning rate scheduling and by using a diphone training objective. Improving upon the model architecture itself proved more difficult, however, with attempts to use deep state space models or transformers not yet appearing to offer a benefit over the RNN baseline. The benchmark will remain open indefinitely to support further work towards increasing the accuracy of brain-to-text algorithms.
Switching Autoregressive Low-rank Tensor Models
Jun 07, 2023



An important problem in time-series analysis is modeling systems with time-varying dynamics. Probabilistic models with joint continuous and discrete latent states offer interpretable, efficient, and experimentally useful descriptions of such data. Commonly used models include autoregressive hidden Markov models (ARHMMs) and switching linear dynamical systems (SLDSs), each with its own advantages and disadvantages. ARHMMs permit exact inference and easy parameter estimation, but are parameter intensive when modeling long dependencies, and hence are prone to overfitting. In contrast, SLDSs can capture long-range dependencies in a parameter efficient way through Markovian latent dynamics, but present an intractable likelihood and a challenging parameter estimation task. In this paper, we propose switching autoregressive low-rank tensor (SALT) models, which retain the advantages of both approaches while ameliorating the weaknesses. SALT parameterizes the tensor of an ARHMM with a low-rank factorization to control the number of parameters and allow longer range dependencies without overfitting. We prove theoretical and discuss practical connections between SALT, linear dynamical systems, and SLDSs. We empirically demonstrate quantitative advantages of SALT models on a range of simulated and real prediction tasks, including behavioral and neural datasets. Furthermore, the learned low-rank tensor provides novel insights into temporal dependencies within each discrete state.
Intent-based Product Collections for E-commerce using Pretrained Language Models
Oct 15, 2021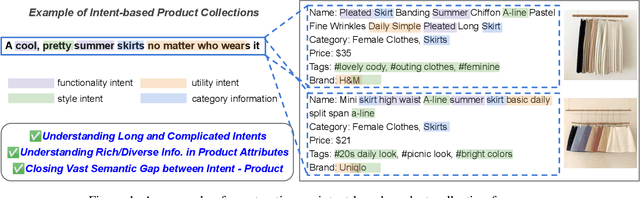
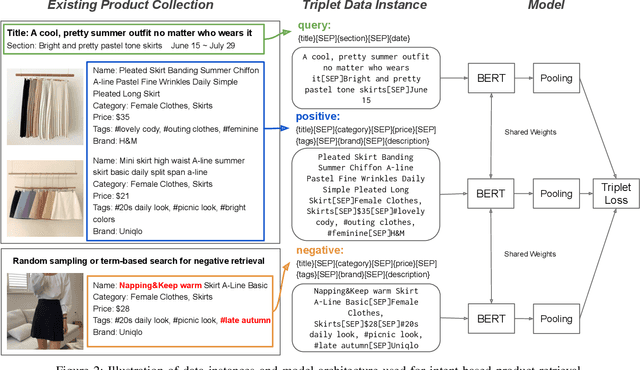
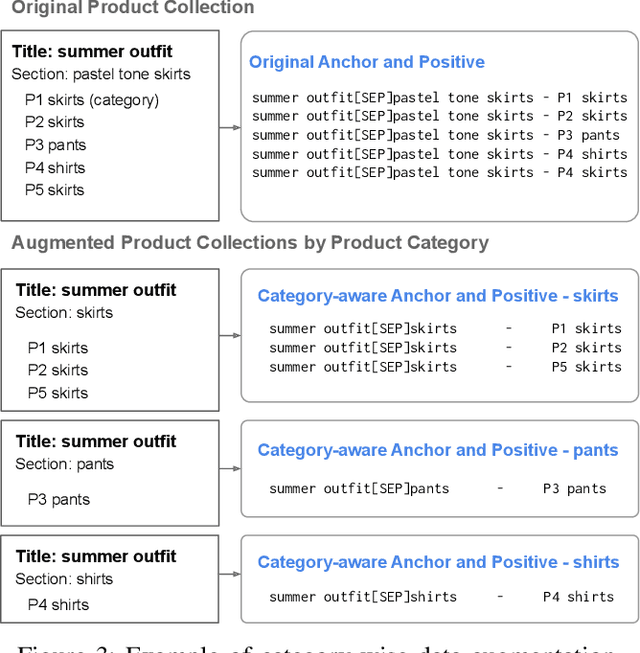
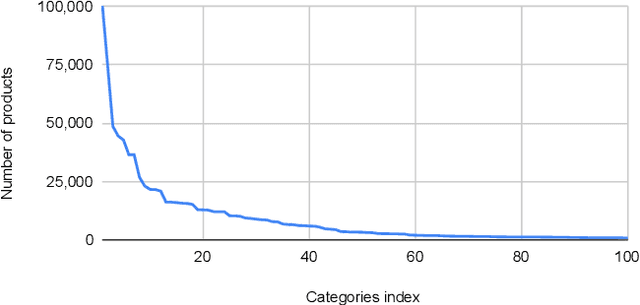
Building a shopping product collection has been primarily a human job. With the manual efforts of craftsmanship, experts collect related but diverse products with common shopping intent that are effective when displayed together, e.g., backpacks, laptop bags, and messenger bags for freshman bag gifts. Automatically constructing a collection requires an ML system to learn a complex relationship between the customer's intent and the product's attributes. However, there have been challenging points, such as 1) long and complicated intent sentences, 2) rich and diverse product attributes, and 3) a huge semantic gap between them, making the problem difficult. In this paper, we use a pretrained language model (PLM) that leverages textual attributes of web-scale products to make intent-based product collections. Specifically, we train a BERT with triplet loss by setting an intent sentence to an anchor and corresponding products to positive examples. Also, we improve the performance of the model by search-based negative sampling and category-wise positive pair augmentation. Our model significantly outperforms the search-based baseline model for intent-based product matching in offline evaluations. Furthermore, online experimental results on our e-commerce platform show that the PLM-based method can construct collections of products with increased CTR, CVR, and order-diversity compared to expert-crafted collections.
AUBER: Automated BERT Regularization
Sep 30, 2020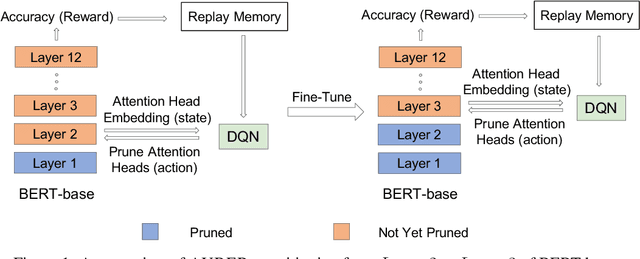
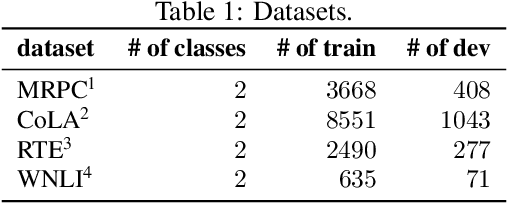
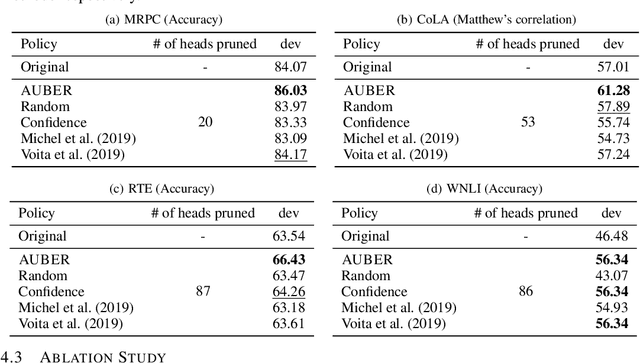

How can we effectively regularize BERT? Although BERT proves its effectiveness in various downstream natural language processing tasks, it often overfits when there are only a small number of training instances. A promising direction to regularize BERT is based on pruning its attention heads based on a proxy score for head importance. However, heuristic-based methods are usually suboptimal since they predetermine the order by which attention heads are pruned. In order to overcome such a limitation, we propose AUBER, an effective regularization method that leverages reinforcement learning to automatically prune attention heads from BERT. Instead of depending on heuristics or rule-based policies, AUBER learns a pruning policy that determines which attention heads should or should not be pruned for regularization. Experimental results show that AUBER outperforms existing pruning methods by achieving up to 10% better accuracy. In addition, our ablation study empirically demonstrates the effectiveness of our design choices for AUBER.
FALCON: Fast and Lightweight Convolution for Compressing and Accelerating CNN
Sep 25, 2019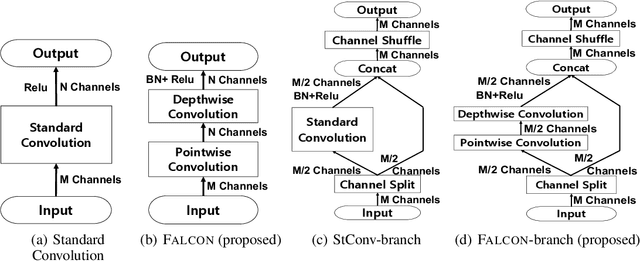
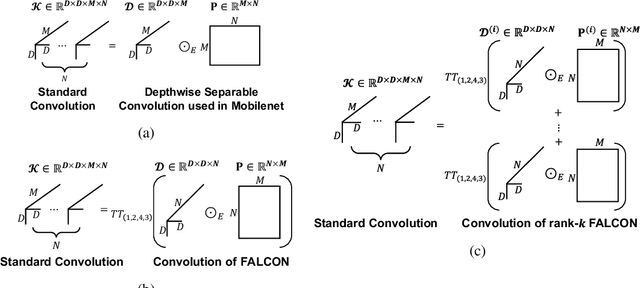
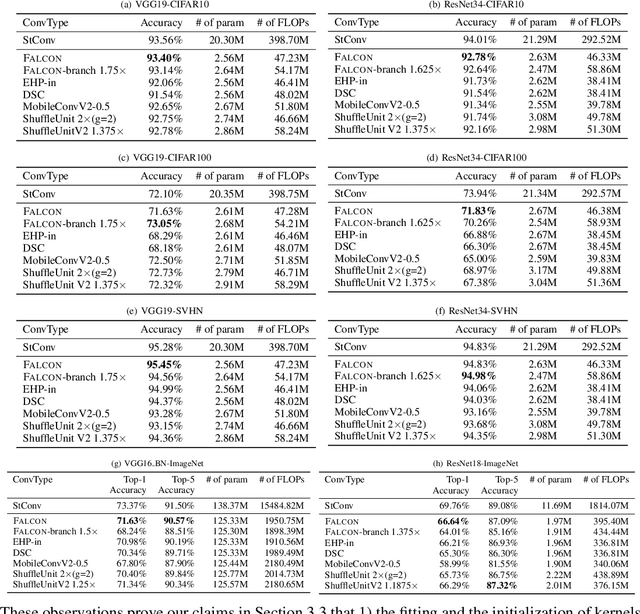
How can we efficiently compress Convolutional Neural Networks (CNN) while retaining their accuracy on classification tasks? A promising direction is based on depthwise separable convolution which replaces a standard convolution with a depthwise convolution and a pointwise convolution. However, previous works based on depthwise separable convolution are limited since 1) they are mostly heuristic approaches without a precise understanding of their relations to standard convolution, and 2) their accuracies do not match that of the standard convolution. In this paper, we propose FALCON, an accurate and lightweight method for compressing CNN. FALCON is derived by interpreting existing convolution methods based on depthwise separable convolution using EHP, our proposed mathematical formulation to approximate the standard convolution kernel. Such interpretation leads to developing a generalized version rank-k FALCON which further improves the accuracy while sacrificing a bit of compression and computation reduction rates. In addition, we propose FALCON-branch by fitting FALCON into the previous state-of-the-art convolution unit ShuffleUnitV2 which gives even better accuracy. Experiments show that FALCON and FALCON-branch outperform 1) existing methods based on depthwise separable convolution and 2) standard CNN models by up to 8x compression and 8x computation reduction while ensuring similar accuracy. We also demonstrate that rank-k FALCON provides even better accuracy than standard convolution in many cases, while using a smaller number of parameters and floating-point operations.