 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Paper and Code
Oct 08, 2022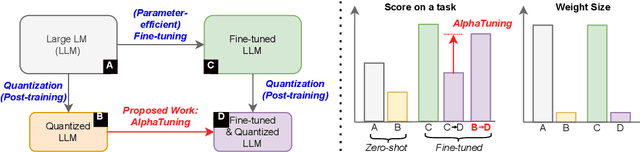

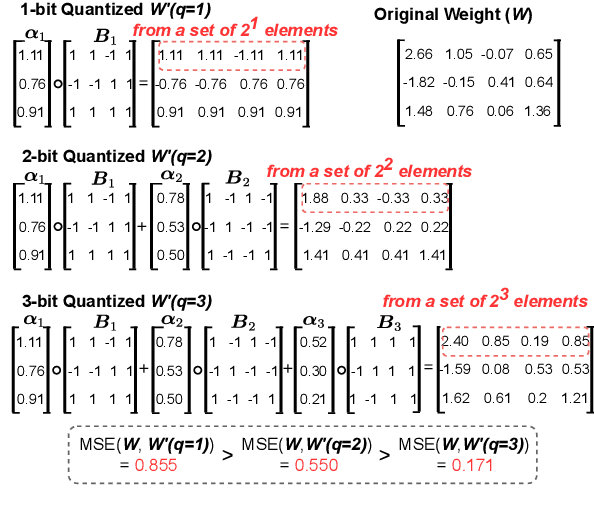
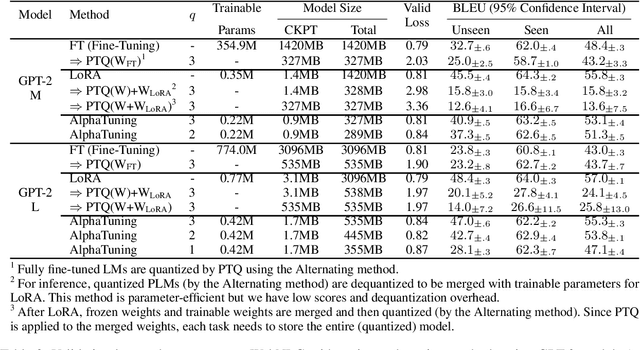
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.