 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResonance RoPE: Improving Context Length Generalization of Large Language Models
Paper and Code
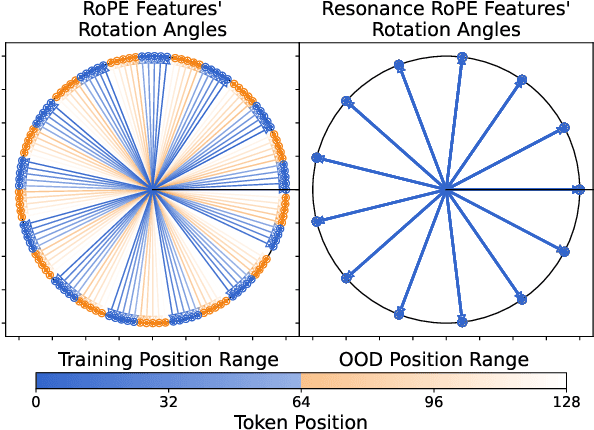

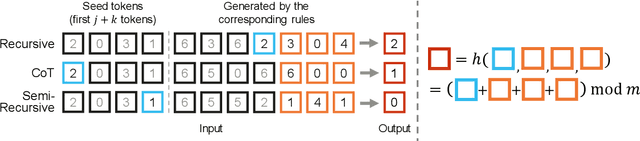
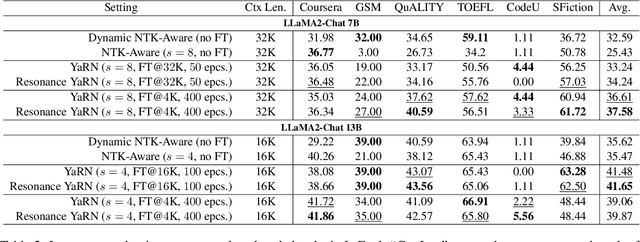
This paper addresses the challenge of train-short-test-long (TSTL) scenarios in Large Language Models (LLMs) equipped with Rotary Position Embedding (RoPE), where models pre-trained on shorter sequences face difficulty with out-of-distribution (OOD) token positions in longer sequences. We introduce Resonance RoPE, a novel approach designed to narrow the generalization gap in TSTL scenarios by refining the interpolation of RoPE features for OOD positions, significantly improving the model performance without additional online computational costs. Furthermore, we present PosGen, a new synthetic benchmark specifically designed for fine-grained behavior analysis in TSTL scenarios, aiming to isolate the constantly increasing difficulty of token generation on long contexts from the challenges of recognizing new token positions. Our experiments on synthetic tasks show that after applying Resonance RoPE, Transformers recognize OOD position better and more robustly. Our extensive LLM experiments also show superior performance after applying Resonance RoPE to the current state-of-the-art RoPE scaling method, YaRN, on both upstream language modeling tasks and a variety of downstream long-text applications.