 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo spectral cues matter in contrast-based graph self-supervised learning?
Paper and Code


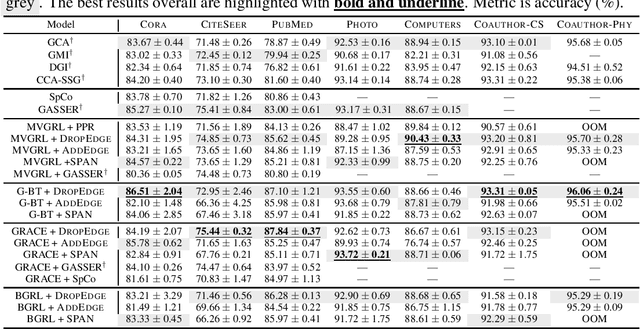
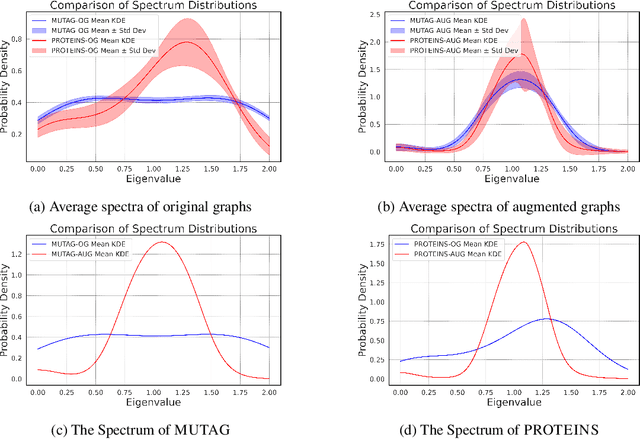
The recent surge in contrast-based graph self-supervised learning has prominently featured an intensified exploration of spectral cues. However, an intriguing paradox emerges, as methods grounded in seemingly conflicting assumptions or heuristic approaches regarding the spectral domain demonstrate notable enhancements in learning performance. This paradox prompts a critical inquiry into the genuine contribution of spectral information to contrast-based graph self-supervised learning. This study undertakes an extensive investigation into this inquiry, conducting a thorough study of the relationship between spectral characteristics and the learning outcomes of contemporary methodologies. Based on this analysis, we claim that the effectiveness and significance of spectral information need to be questioned. Instead, we revisit simple edge perturbation: random edge dropping designed for node-level self-supervised learning and random edge adding intended for graph-level self-supervised learning. Compelling evidence is presented that these simple yet effective strategies consistently yield superior performance while demanding significantly fewer computational resources compared to all prior spectral augmentation methods. The proposed insights represent a significant leap forward in the field, potentially reshaping the understanding and implementation of graph self-supervised learning.