 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
Sep 12, 2022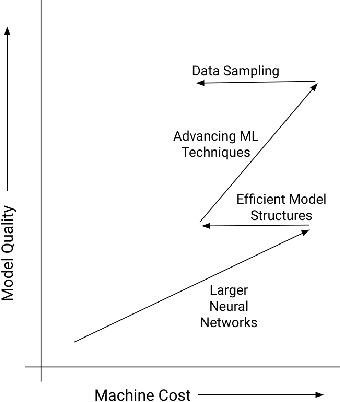
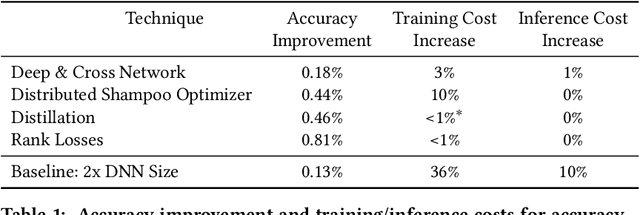
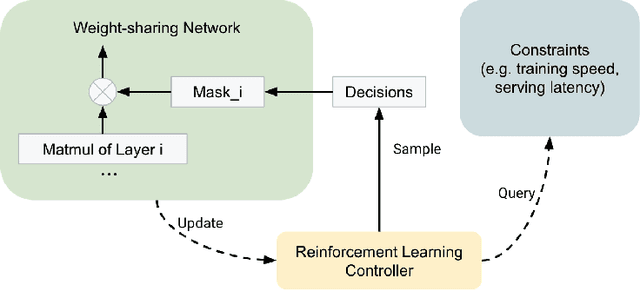

For industrial-scale advertising systems, prediction of ad click-through rate (CTR) is a central problem. Ad clicks constitute a significant class of user engagements and are often used as the primary signal for the usefulness of ads to users. Additionally, in cost-per-click advertising systems where advertisers are charged per click, click rate expectations feed directly into value estimation. Accordingly, CTR model development is a significant investment for most Internet advertising companies. Engineering for such problems requires many machine learning (ML) techniques suited to online learning that go well beyond traditional accuracy improvements, especially concerning efficiency, reproducibility, calibration, credit attribution. We present a case study of practical techniques deployed in Google's search ads CTR model. This paper provides an industry case study highlighting important areas of current ML research and illustrating how impactful new ML methods are evaluated and made useful in a large-scale industrial setting.
Second Order Optimization Made Practical
Feb 20, 2020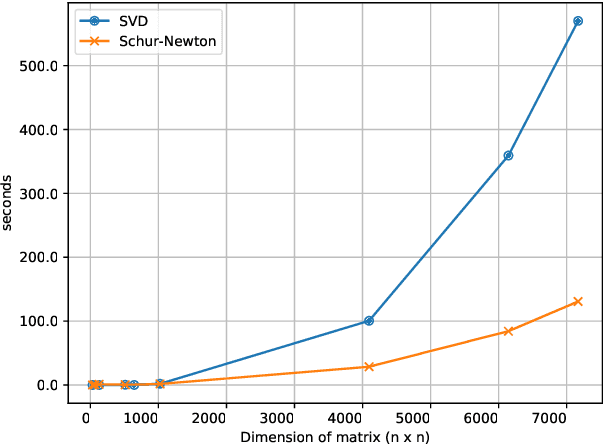

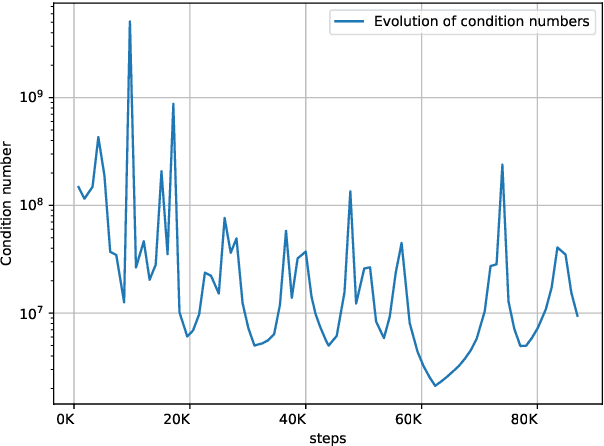

Optimization in machine learning, both theoretical and applied, is presently dominated by first-order gradient methods such as stochastic gradient descent. Second-order optimization methods that involve second-order derivatives and/or second-order statistics of the data have become far less prevalent despite strong theoretical properties, due to their prohibitive computation, memory and communication costs. In an attempt to bridge this gap between theoretical and practical optimization, we present a proof-of-concept distributed system implementation of a second-order preconditioned method (specifically, a variant of full-matrix Adagrad), that along with a few yet critical algorithmic and numerical improvements, provides significant practical gains in convergence on state-of-the-art deep models and gives rise to actual wall-time improvements in practice compared to conventional first-order methods. Our design effectively utilizes the prevalent heterogeneous hardware architecture for training deep models which consists of a multicore CPU coupled with multiple accelerator units. We demonstrate superior performance on very large learning problems in machine translation where our distributed implementation runs considerably faster than existing gradient-based methods.
Large Margin Deep Networks for Classification
Mar 15, 2018

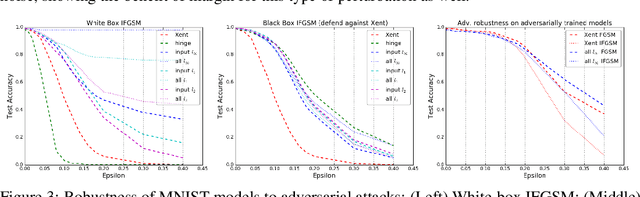

We present a formulation of deep learning that aims at producing a large margin classifier. The notion of margin, minimum distance to a decision boundary, has served as the foundation of several theoretically profound and empirically successful results for both classification and regression tasks. However, most large margin algorithms are applicable only to shallow models with a preset feature representation; and conventional margin methods for neural networks only enforce margin at the output layer. Such methods are therefore not well suited for deep networks. In this work, we propose a novel loss function to impose a margin on any chosen set of layers of a deep network (including input and hidden layers). Our formulation allows choosing any norm on the metric measuring the margin. We demonstrate that the decision boundary obtained by our loss has nice properties compared to standard classification loss functions. Specifically, we show improved empirical results on the MNIST, CIFAR-10 and ImageNet datasets on multiple tasks: generalization from small training sets, corrupted labels, and robustness against adversarial perturbations. The resulting loss is general and complementary to existing data augmentation (such as random/adversarial input transform) and regularization techniques (such as weight decay, dropout, and batch norm).
Regret-based Reward Elicitation for Markov Decision Processes
May 09, 2012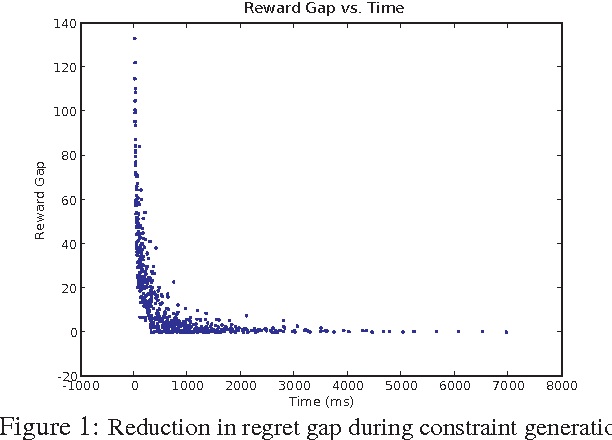
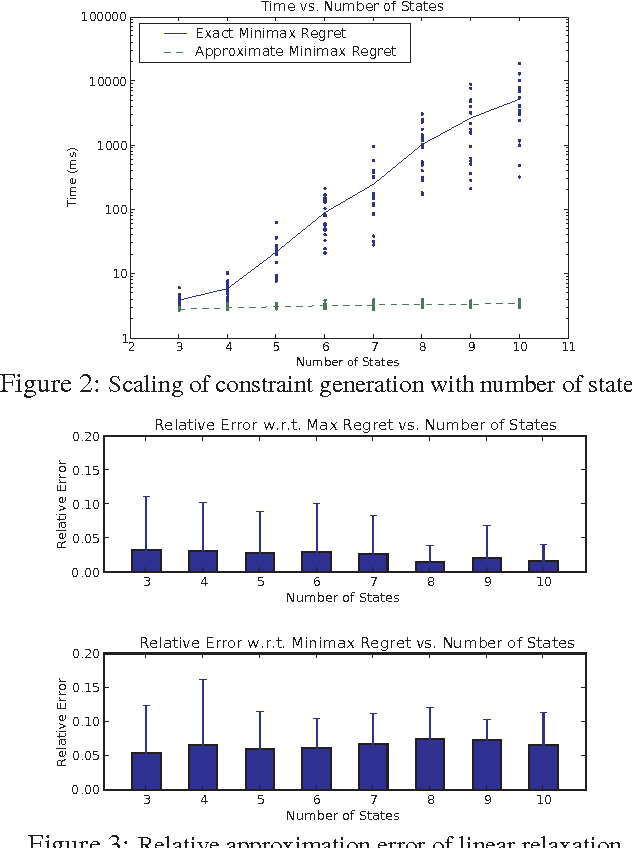
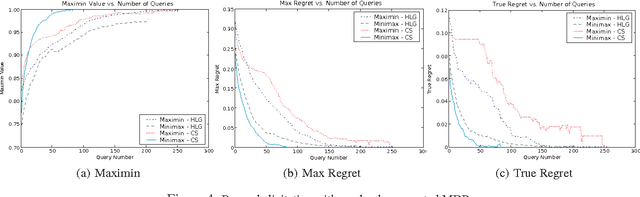
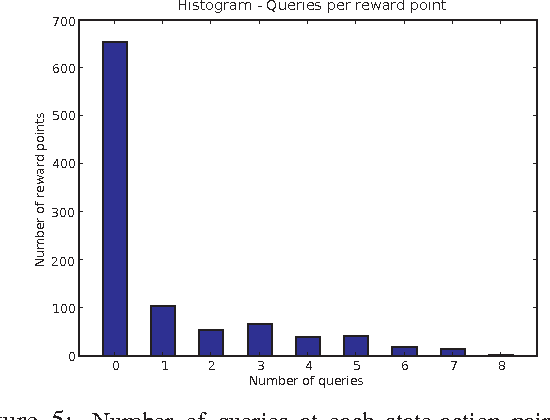
The specification of aMarkov decision process (MDP) can be difficult. Reward function specification is especially problematic; in practice, it is often cognitively complex and time-consuming for users to precisely specify rewards. This work casts the problem of specifying rewards as one of preference elicitation and aims to minimize the degree of precision with which a reward function must be specified while still allowing optimal or near-optimal policies to be produced. We first discuss how robust policies can be computed for MDPs given only partial reward information using the minimax regret criterion. We then demonstrate how regret can be reduced by efficiently eliciting reward information using bound queries, using regret-reduction as a means for choosing suitable queries. Empirical results demonstrate that regret-based reward elicitation offers an effective way to produce near-optimal policies without resorting to the precise specification of the entire reward function.