 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representation Learning for 3D Point Cloud Data
Paper and Code
Oct 13, 2021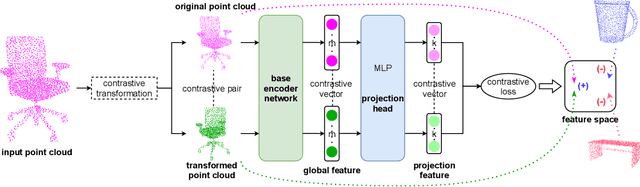


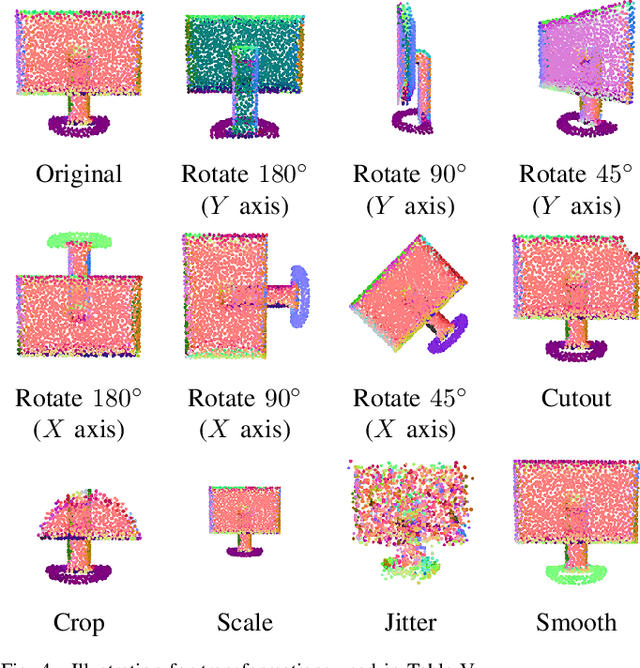
Though a number of point cloud learning methods have been proposed to handle unordered points, most of them are supervised and require labels for training. By contrast, unsupervised learning of point cloud data has received much less attention to date. In this paper, we propose a simple yet effective approach for unsupervised point cloud learning. In particular, we identify a very useful transformation which generates a good contrastive version of an original point cloud. They make up a pair. After going through a shared encoder and a shared head network, the consistency between the output representations are maximized with introducing two variants of contrastive losses to respectively facilitate downstream classification and segmentation. To demonstrate the efficacy of our method, we conduct experiments on three downstream tasks which are 3D object classification (on ModelNet40 and ModelNet10), shape part segmentation (on ShapeNet Part dataset) as well as scene segmentation (on S3DIS). Comprehensive results show that our unsupervised contrastive representation learning enables impressive outcomes in object classification and semantic segmentation. It generally outperforms current unsupervised methods, and even achieves comparable performance to supervised methods. Our source codes will be made publicly available.