 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Back and Forth: Video Super-Resolution with Explicit Temporal Difference Modeling
Apr 14, 2022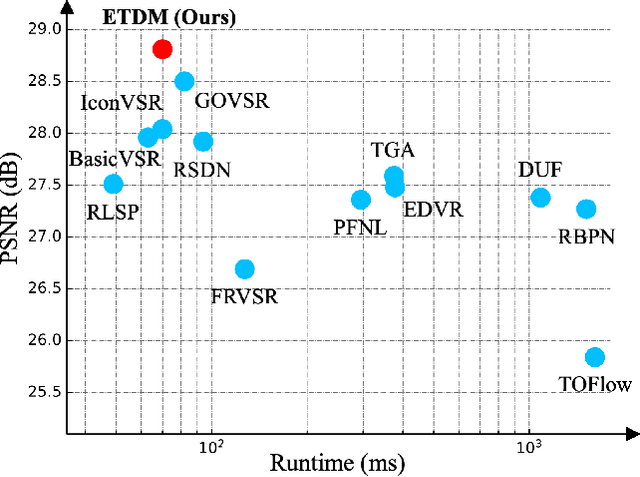
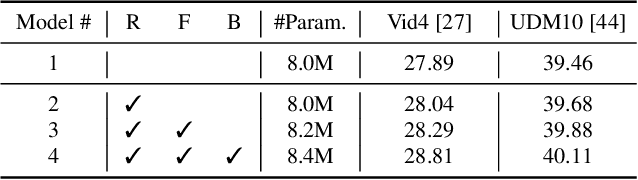
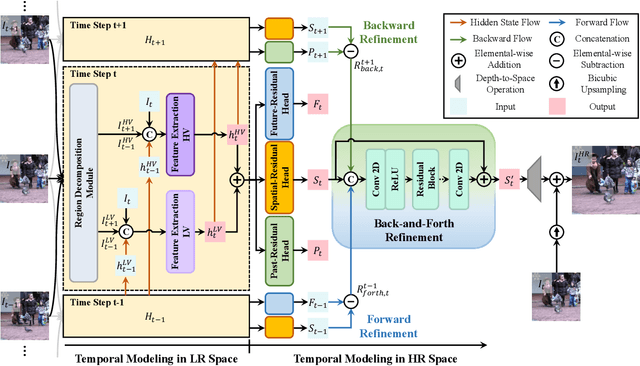
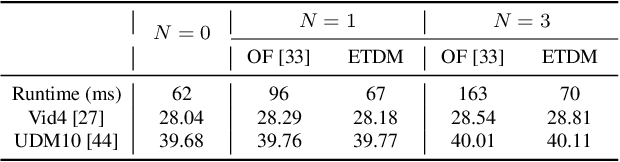
Temporal modeling is crucial for video super-resolution. Most of the video super-resolution methods adopt the optical flow or deformable convolution for explicitly motion compensation. However, such temporal modeling techniques increase the model complexity and might fail in case of occlusion or complex motion, resulting in serious distortion and artifacts. In this paper, we propose to explore the role of explicit temporal difference modeling in both LR and HR space. Instead of directly feeding consecutive frames into a VSR model, we propose to compute the temporal difference between frames and divide those pixels into two subsets according to the level of difference. They are separately processed with two branches of different receptive fields in order to better extract complementary information. To further enhance the super-resolution result, not only spatial residual features are extracted, but the difference between consecutive frames in high-frequency domain is also computed. It allows the model to exploit intermediate SR results in both future and past to refine the current SR output. The difference at different time steps could be cached such that information from further distance in time could be propagated to the current frame for refinement. Experiments on several video super-resolution benchmark datasets demonstrate the effectiveness of the proposed method and its favorable performance against state-of-the-art methods.
Frequency Superposition -- A Multi-Frequency Stimulation Method in SSVEP-based BCIs
Apr 25, 2021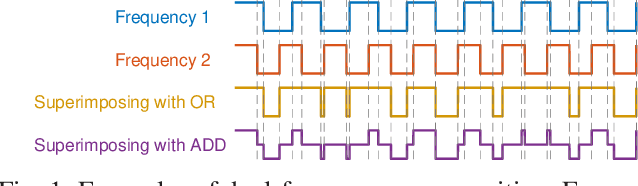
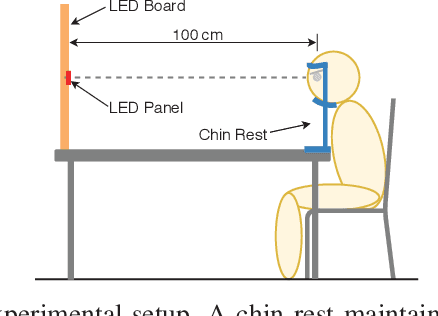
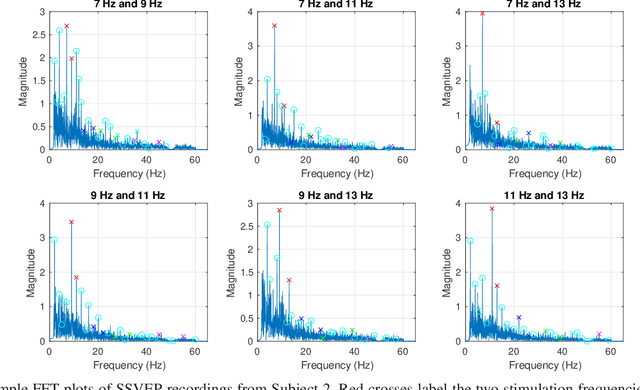
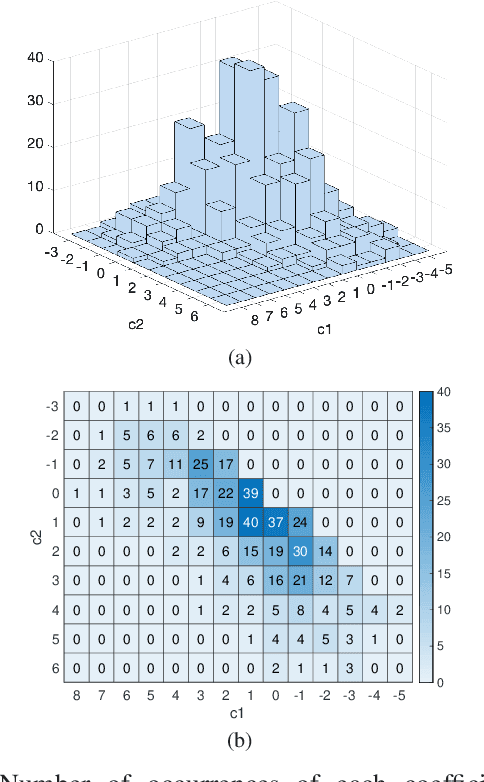
The steady-state visual evoked potential (SSVEP) is one of the most widely used modalities in brain-computer interfaces (BCIs) due to its many advantages. However, the existence of harmonics and the limited range of responsive frequencies in SSVEP make it challenging to further expand the number of targets without sacrificing other aspects of the interface or putting additional constraints on the system. This paper introduces a novel multi-frequency stimulation method for SSVEP and investigates its potential to effectively and efficiently increase the number of targets presented. The proposed stimulation method, obtained by the superposition of the stimulation signals at different frequencies, is size-efficient, allows single-step target identification, puts no strict constraints on the usable frequency range, can be suited to self-paced BCIs, and does not require specific light sources. In addition to the stimulus frequencies and their harmonics, the evoked SSVEP waveforms include frequencies that are integer linear combinations of the stimulus frequencies. Results of decoding SSVEPs collected from nine subjects using canonical correlation analysis (CCA) with only the frequencies and harmonics as reference, also demonstrate the potential of using such a stimulation paradigm in SSVEP-based BCIs.