 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Temporal Modeling for Video Super-resolution
Paper and Code


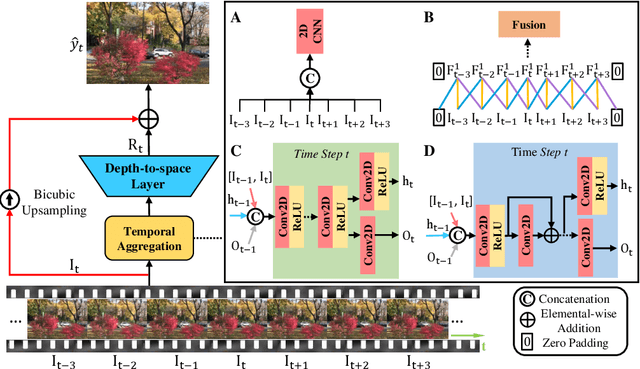

Video super-resolution plays an important role in surveillance video analysis and ultra-high-definition video display, which has drawn much attention in both the research and industrial communities. Although many deep learning-based VSR methods have been proposed, it is hard to directly compare these methods since the different loss functions and training datasets have a significant impact on the super-resolution results. In this work, we carefully study and compare three temporal modeling methods (2D CNN with early fusion, 3D CNN with slow fusion and Recurrent Neural Network) for video super-resolution. We also propose a novel Recurrent Residual Network (RRN) for efficient video super-resolution, where residual learning is utilized to stabilize the training of RNN and meanwhile to boost the super-resolution performance. Extensive experiments show that the proposed RRN is highly computational efficiency and produces temporal consistent VSR results with finer details than other temporal modeling methods. Besides, the proposed method achieves state-of-the-art results on several widely used benchmarks.