 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarlequin: Color-driven Generation of Synthetic Data for Referring Expression Comprehension
Nov 22, 2024Referring Expression Comprehension (REC) aims to identify a particular object in a scene by a natural language expression, and is an important topic in visual language understanding. State-of-the-art methods for this task are based on deep learning, which generally requires expensive and manually labeled annotations. Some works tackle the problem with limited-supervision learning or relying on Large Vision and Language Models. However, the development of techniques to synthesize labeled data is overlooked. In this paper, we propose a novel framework that generates artificial data for the REC task, taking into account both textual and visual modalities. At first, our pipeline processes existing data to create variations in the annotations. Then, it generates an image using altered annotations as guidance. The result of this pipeline is a new dataset, called Harlequin, made by more than 1M queries. This approach eliminates manual data collection and annotation, enabling scalability and facilitating arbitrary complexity. We pre-train three REC models on Harlequin, then fine-tuned and evaluated on human-annotated datasets. Our experiments show that the pre-training on artificial data is beneficial for performance.
Where are my Neighbors? Exploiting Patches Relations in Self-Supervised Vision Transformer
Jun 01, 2022
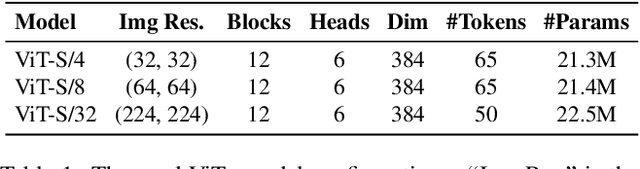


Vision Transformers (ViTs) enabled the use of transformer architecture on vision tasks showing impressive performances when trained on big datasets. However, on relatively small datasets, ViTs are less accurate given their lack of inductive bias. To this end, we propose a simple but still effective self-supervised learning (SSL) strategy to train ViTs, that without any external annotation, can significantly improve the results. Specifically, we define a set of SSL tasks based on relations of image patches that the model has to solve before or jointly during the downstream training. Differently from ViT, our RelViT model optimizes all the output tokens of the transformer encoder that are related to the image patches, thus exploiting more training signal at each training step. We investigated our proposed methods on several image benchmarks finding that RelViT improves the SSL state-of-the-art methods by a large margin, especially on small datasets.