 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Data Annotators: How Close Are We to Human Performance
Apr 21, 2025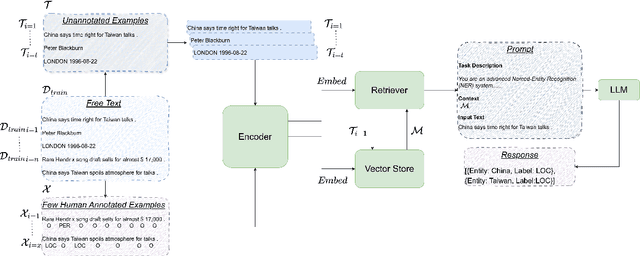
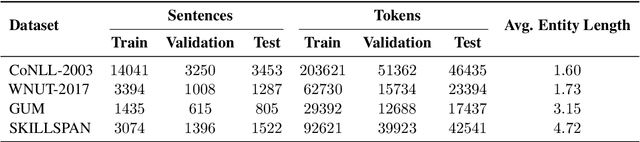
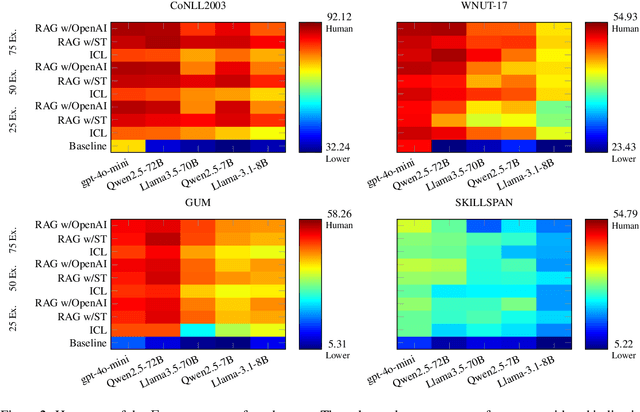
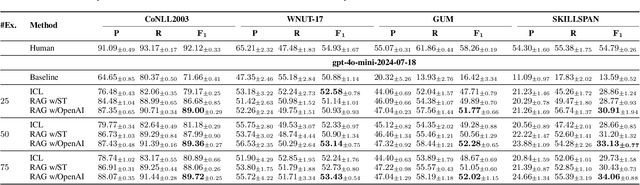
In NLP, fine-tuning LLMs is effective for various applications but requires high-quality annotated data. However, manual annotation of data is labor-intensive, time-consuming, and costly. Therefore, LLMs are increasingly used to automate the process, often employing in-context learning (ICL) in which some examples related to the task are given in the prompt for better performance. However, manually selecting context examples can lead to inefficiencies and suboptimal model performance. This paper presents comprehensive experiments comparing several LLMs, considering different embedding models, across various datasets for the Named Entity Recognition (NER) task. The evaluation encompasses models with approximately $7$B and $70$B parameters, including both proprietary and non-proprietary models. Furthermore, leveraging the success of Retrieval-Augmented Generation (RAG), it also considers a method that addresses the limitations of ICL by automatically retrieving contextual examples, thereby enhancing performance. The results highlight the importance of selecting the appropriate LLM and embedding model, understanding the trade-offs between LLM sizes and desired performance, and the necessity to direct research efforts towards more challenging datasets.
RGCVAE: Relational Graph Conditioned Variational Autoencoder for Molecule Design
May 19, 2023
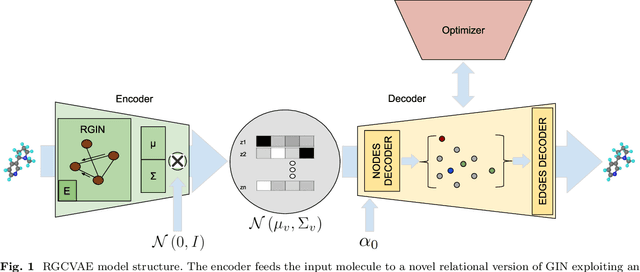
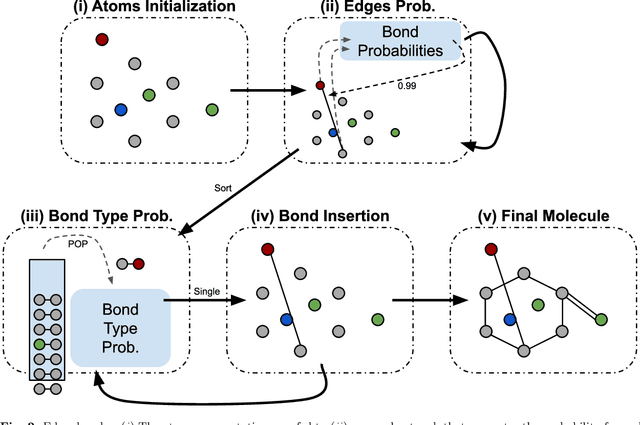
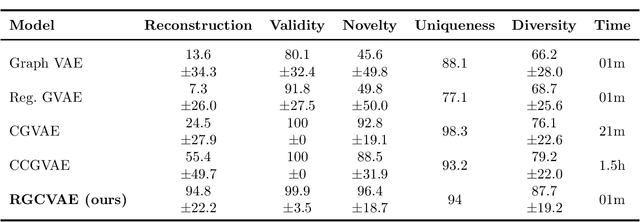
Identifying molecules that exhibit some pre-specified properties is a difficult problem to solve. In the last few years, deep generative models have been used for molecule generation. Deep Graph Variational Autoencoders are among the most powerful machine learning tools with which it is possible to address this problem. However, existing methods struggle in capturing the true data distribution and tend to be computationally expensive. In this work, we propose RGCVAE, an efficient and effective Graph Variational Autoencoder based on: (i) an encoding network exploiting a new powerful Relational Graph Isomorphism Network; (ii) a novel probabilistic decoding component. Compared to several state-of-the-art VAE methods on two widely adopted datasets, RGCVAE shows state-of-the-art molecule generation performance while being significantly faster to train.
Weakly-Supervised Visual-Textual Grounding with Semantic Prior Refinement
May 18, 2023

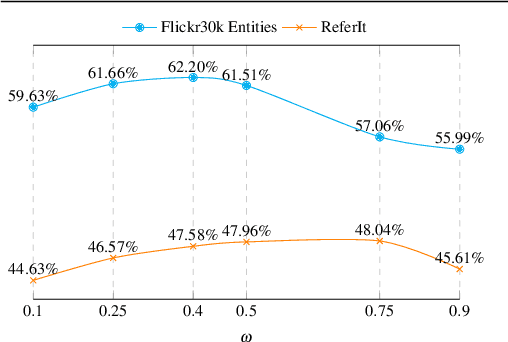

Using only image-sentence pairs, weakly-supervised visual-textual grounding aims to learn region-phrase correspondences of the respective entity mentions. Compared to the supervised approach, learning is more difficult since bounding boxes and textual phrases correspondences are unavailable. In light of this, we propose the Semantic Prior Refinement Model (SPRM), whose predictions are obtained by combining the output of two main modules. The first untrained module aims to return a rough alignment between textual phrases and bounding boxes. The second trained module is composed of two sub-components that refine the rough alignment to improve the accuracy of the final phrase-bounding box alignments. The model is trained to maximize the multimodal similarity between an image and a sentence, while minimizing the multimodal similarity of the same sentence and a new unrelated image, carefully selected to help the most during training. Our approach shows state-of-the-art results on two popular datasets, Flickr30k Entities and ReferIt, shining especially on ReferIt with a 9.6% absolute improvement. Moreover, thanks to the untrained component, it reaches competitive performances just using a small fraction of training examples.
A Better Loss for Visual-Textual Grounding
Aug 11, 2021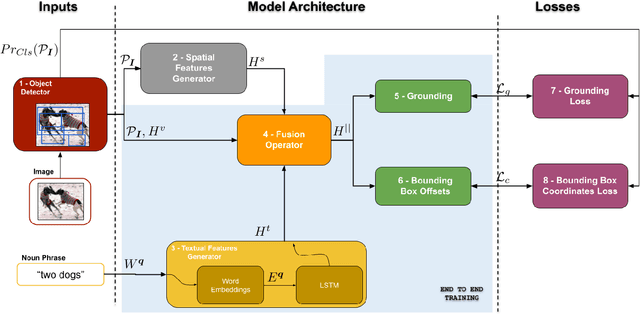
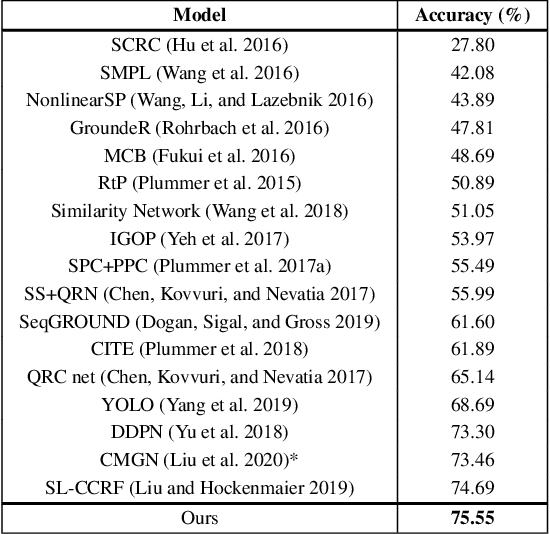

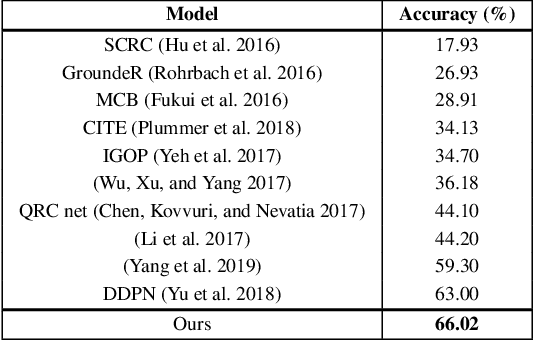
Given a textual phrase and an image, the visual grounding problem is defined as the task of locating the content of the image referenced by the sentence. It is a challenging task that has several real-world applications in human-computer interaction, image-text reference resolution, and video-text reference resolution. In the last years, several works have addressed this problem with heavy and complex models that try to capture visual-textual dependencies better than before. These models are typically constituted by two main components that focus on how to learn useful multi-modal features for grounding and how to improve the predicted bounding box of the visual mention, respectively. Finding the right learning balance between these two sub-tasks is not easy, and the current models are not necessarily optimal with respect to this issue. In this work, we propose a model that, although using a simple multi-modal feature fusion component, is able to achieve a higher accuracy than state-of-the-art models thanks to the adoption of a more effective loss function, based on the classes probabilities, that reach, in the considered datasets, a better learning balance between the two sub-tasks mentioned above.
Conditional Constrained Graph Variational Autoencoders for Molecule Design
Sep 01, 2020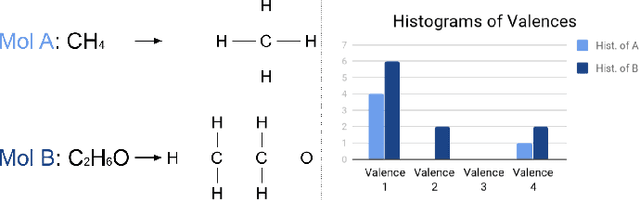

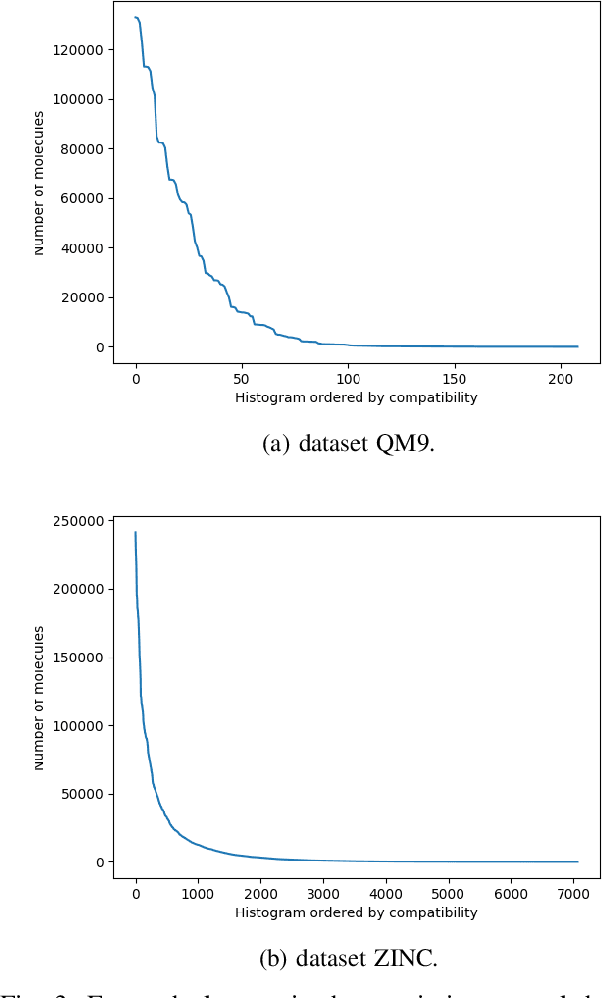

In recent years, deep generative models for graphs have been used to generate new molecules. These models have produced good results, leading to several proposals in the literature. However, these models may have troubles learning some of the complex laws governing the chemical world. In this work, we explore the usage of the histogram of atom valences to drive the generation of molecules in such models. We present Conditional Constrained Graph Variational Autoencoder (CCGVAE), a model that implements this key-idea in a state-of-the-art model, and shows improved results on several evaluation metrics on two commonly adopted datasets for molecule generation.
A Systematic Assessment of Deep Learning Models for Molecule Generation
Aug 20, 2020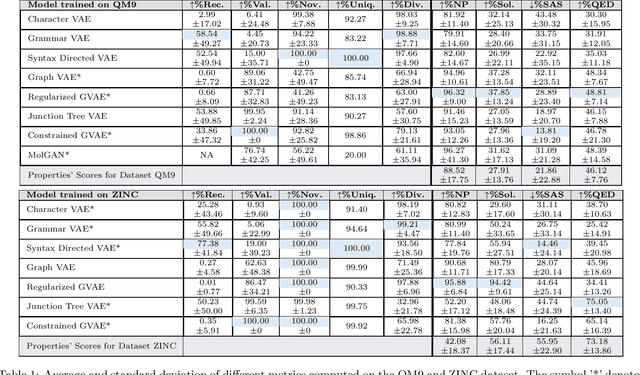
In recent years the scientific community has devoted much effort in the development of deep learning models for the generation of new molecules with desirable properties (i.e. drugs). This has produced many proposals in literature. However, a systematic comparison among the different VAE methods is still missing. For this reason, we propose an extensive testbed for the evaluation of generative models for drug discovery, and we present the results obtained by many of the models proposed in literature.