 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Better Loss for Visual-Textual Grounding
Paper and Code
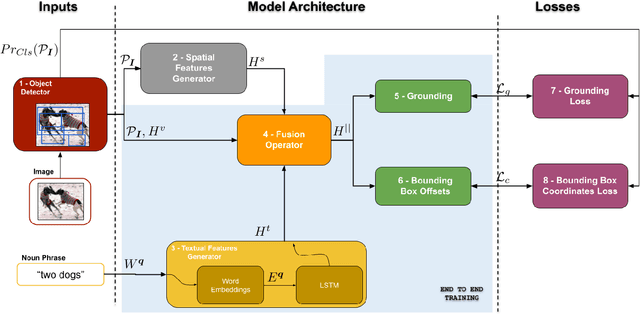
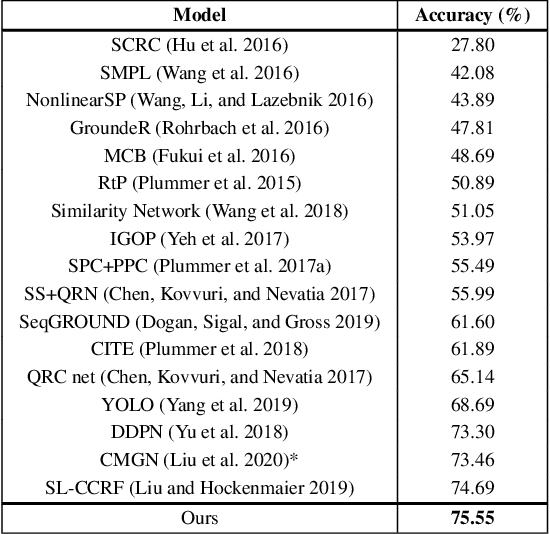

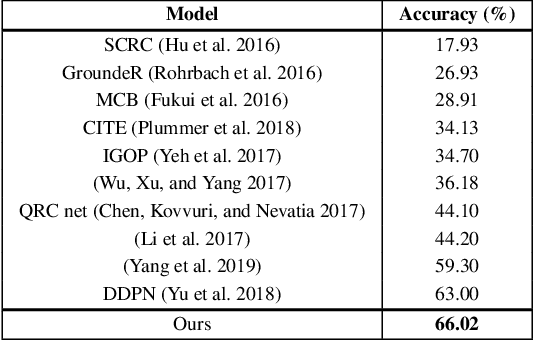
Given a textual phrase and an image, the visual grounding problem is defined as the task of locating the content of the image referenced by the sentence. It is a challenging task that has several real-world applications in human-computer interaction, image-text reference resolution, and video-text reference resolution. In the last years, several works have addressed this problem with heavy and complex models that try to capture visual-textual dependencies better than before. These models are typically constituted by two main components that focus on how to learn useful multi-modal features for grounding and how to improve the predicted bounding box of the visual mention, respectively. Finding the right learning balance between these two sub-tasks is not easy, and the current models are not necessarily optimal with respect to this issue. In this work, we propose a model that, although using a simple multi-modal feature fusion component, is able to achieve a higher accuracy than state-of-the-art models thanks to the adoption of a more effective loss function, based on the classes probabilities, that reach, in the considered datasets, a better learning balance between the two sub-tasks mentioned above.