 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Data Annotators: How Close Are We to Human Performance
Apr 21, 2025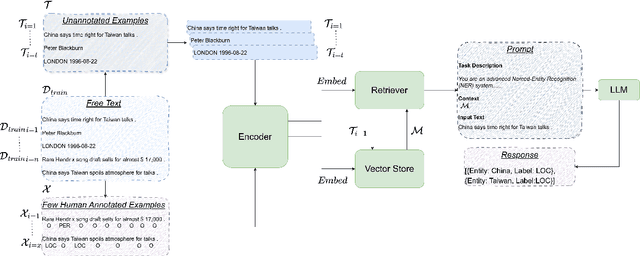
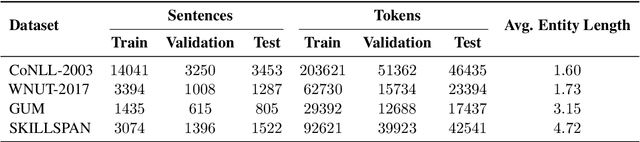
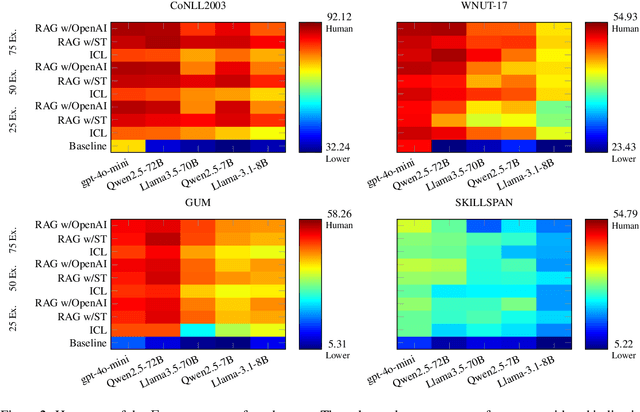
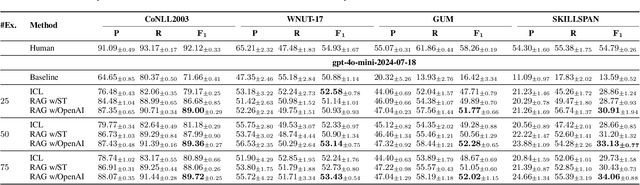
In NLP, fine-tuning LLMs is effective for various applications but requires high-quality annotated data. However, manual annotation of data is labor-intensive, time-consuming, and costly. Therefore, LLMs are increasingly used to automate the process, often employing in-context learning (ICL) in which some examples related to the task are given in the prompt for better performance. However, manually selecting context examples can lead to inefficiencies and suboptimal model performance. This paper presents comprehensive experiments comparing several LLMs, considering different embedding models, across various datasets for the Named Entity Recognition (NER) task. The evaluation encompasses models with approximately $7$B and $70$B parameters, including both proprietary and non-proprietary models. Furthermore, leveraging the success of Retrieval-Augmented Generation (RAG), it also considers a method that addresses the limitations of ICL by automatically retrieving contextual examples, thereby enhancing performance. The results highlight the importance of selecting the appropriate LLM and embedding model, understanding the trade-offs between LLM sizes and desired performance, and the necessity to direct research efforts towards more challenging datasets.