 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Action Recognition with Action Prototypes
Dec 11, 2023



Early action recognition is an important and challenging problem that enables the recognition of an action from a partially observed video stream where the activity is potentially unfinished or even not started. In this work, we propose a novel model that learns a prototypical representation of the full action for each class and uses it to regularize the architecture and the visual representations of the partial observations. Our model is very simple in design and also efficient. We decompose the video into short clips, where a visual encoder extracts features from each clip independently. Later, a decoder aggregates together in an online fashion features from all the clips for the final class prediction. During training, for each partial observation, the model is jointly trained to both predict the label as well as the action prototypical representation which acts as a regularizer. We evaluate our method on multiple challenging real-world datasets and outperform the current state-of-the-art by a significant margin. For example, on early recognition observing only the first 10% of each video, our method improves the SOTA by +2.23 Top-1 accuracy on Something-Something-v2, +3.55 on UCF-101, +3.68 on SSsub21, and +5.03 on EPIC-Kitchens-55, where prior work used either multi-modal inputs (e.g. optical-flow) or batched inference. Finally, we also present exhaustive ablation studies to motivate the design choices we made, as well as gather insights regarding what our model is learning semantically.
Generation of Virtual Dual Energy Images from Standard Single-Shot Radiographs using Multi-scale and Conditional Adversarial Network
Oct 22, 2018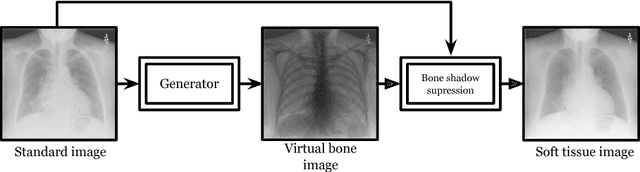
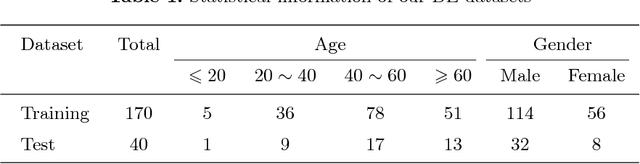
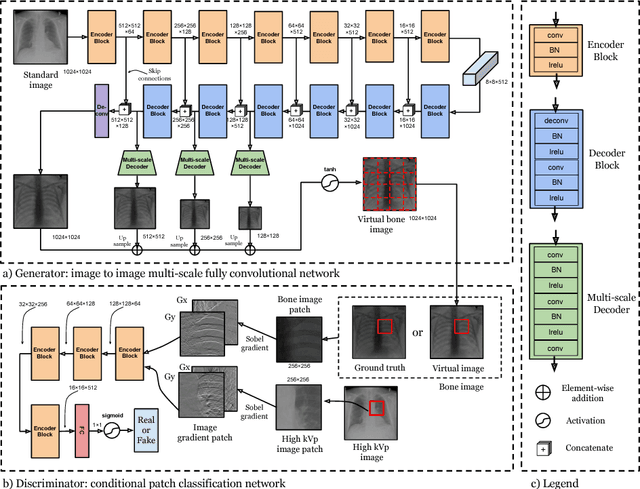
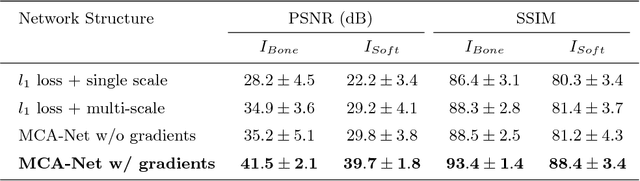
Dual-energy (DE) chest radiographs provide greater diagnostic information than standard radiographs by separating the image into bone and soft tissue, revealing suspicious lesions which may otherwise be obstructed from view. However, acquisition of DE images requires two physical scans, necessitating specialized hardware and processing, and images are prone to motion artifact. Generation of virtual DE images from standard, single-shot chest radiographs would expand the diagnostic value of standard radiographs without changing the acquisition procedure. We present a Multi-scale Conditional Adversarial Network (MCA-Net) which produces high-resolution virtual DE bone images from standard, single-shot chest radiographs. Our proposed MCA-Net is trained using the adversarial network so that it learns sharp details for the production of high-quality bone images. Then, the virtual DE soft tissue image is generated by processing the standard radiograph with the virtual bone image using a cross projection transformation. Experimental results from 210 patient DE chest radiographs demonstrated that the algorithm can produce high-quality virtual DE chest radiographs. Important structures were preserved, such as coronary calcium in bone images and lung lesions in soft tissue images. The average structure similarity index and the peak signal to noise ratio of the produced bone images in testing data were 96.4 and 41.5, which are significantly better than results from previous methods. Furthermore, our clinical evaluation results performed on the publicly available dataset indicates the clinical values of our algorithms. Thus, our algorithm can produce high-quality DE images that are potentially useful for radiologists, computer-aided diagnostics, and other diagnostic tasks.
Learning to Generate Long-term Future via Hierarchical Prediction
Jan 08, 2018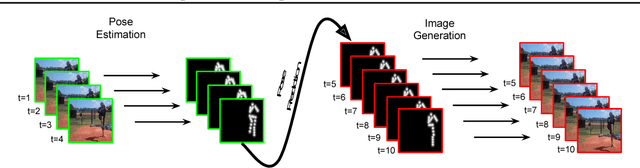
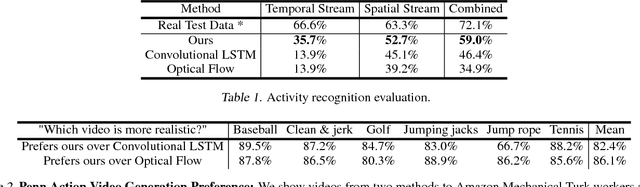

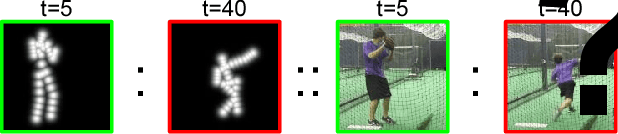
We propose a hierarchical approach for making long-term predictions of future frames. To avoid inherent compounding errors in recursive pixel-level prediction, we propose to first estimate high-level structure in the input frames, then predict how that structure evolves in the future, and finally by observing a single frame from the past and the predicted high-level structure, we construct the future frames without having to observe any of the pixel-level predictions. Long-term video prediction is difficult to perform by recurrently observing the predicted frames because the small errors in pixel space exponentially amplify as predictions are made deeper into the future. Our approach prevents pixel-level error propagation from happening by removing the need to observe the predicted frames. Our model is built with a combination of LSTM and analogy based encoder-decoder convolutional neural networks, which independently predict the video structure and generate the future frames, respectively. In experiments, our model is evaluated on the Human3.6M and Penn Action datasets on the task of long-term pixel-level video prediction of humans performing actions and demonstrate significantly better results than the state-of-the-art.
Decomposing Motion and Content for Natural Video Sequence Prediction
Jan 08, 2018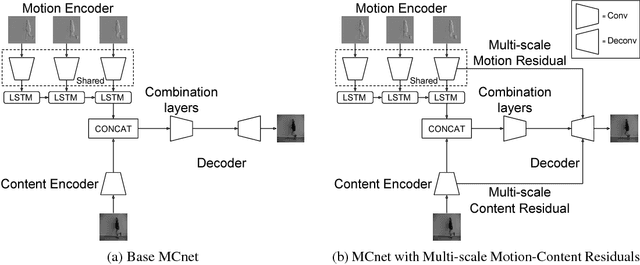
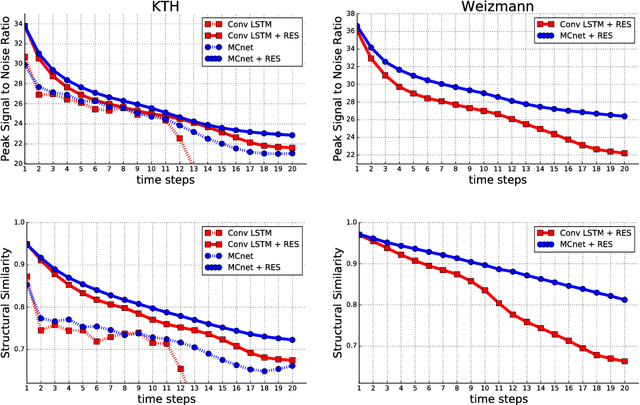

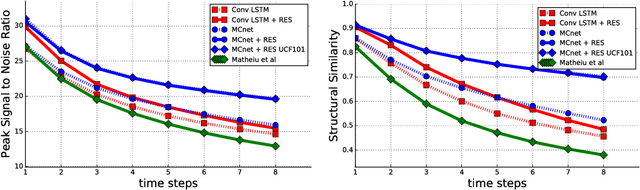
We propose a deep neural network for the prediction of future frames in natural video sequences. To effectively handle complex evolution of pixels in videos, we propose to decompose the motion and content, two key components generating dynamics in videos. Our model is built upon the Encoder-Decoder Convolutional Neural Network and Convolutional LSTM for pixel-level prediction, which independently capture the spatial layout of an image and the corresponding temporal dynamics. By independently modeling motion and content, predicting the next frame reduces to converting the extracted content features into the next frame content by the identified motion features, which simplifies the task of prediction. Our model is end-to-end trainable over multiple time steps, and naturally learns to decompose motion and content without separate training. We evaluate the proposed network architecture on human activity videos using KTH, Weizmann action, and UCF-101 datasets. We show state-of-the-art performance in comparison to recent approaches. To the best of our knowledge, this is the first end-to-end trainable network architecture with motion and content separation to model the spatiotemporal dynamics for pixel-level future prediction in natural videos.
Disentangling Motion, Foreground and Background Features in Videos
Jul 17, 2017



This paper introduces an unsupervised framework to extract semantically rich features for video representation. Inspired by how the human visual system groups objects based on motion cues, we propose a deep convolutional neural network that disentangles motion, foreground and background information. The proposed architecture consists of a 3D convolutional feature encoder for blocks of 16 frames, which is trained for reconstruction tasks over the first and last frames of the sequence. A preliminary supervised experiment was conducted to verify the feasibility of proposed method by training the model with a fraction of videos from the UCF-101 dataset taking as ground truth the bounding boxes around the activity regions. Qualitative results indicate that the network can successfully segment foreground and background in videos as well as update the foreground appearance based on disentangled motion features. The benefits of these learned features are shown in a discriminative classification task, where initializing the network with the proposed pretraining method outperforms both random initialization and autoencoder pretraining. Our model and source code are publicly available at https://imatge-upc.github.io/unsupervised-2017-cvprw/ .