 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Initialize your Network? Robust Initialization for WeightNorm & ResNets
Jun 05, 2019



Residual networks (ResNet) and weight normalization play an important role in various deep learning applications. However, parameter initialization strategies have not been studied previously for weight normalized networks and, in practice, initialization methods designed for un-normalized networks are used as a proxy. Similarly, initialization for ResNets have also been studied for un-normalized networks and often under simplified settings ignoring the shortcut connection. To address these issues, we propose a novel parameter initialization strategy that avoids explosion/vanishment of information across layers for weight normalized networks with and without residual connections. The proposed strategy is based on a theoretical analysis using mean field approximation. We run over 2,500 experiments and evaluate our proposal on image datasets showing that the proposed initialization outperforms existing initialization methods in terms of generalization performance, robustness to hyper-parameter values and variance between seeds, especially when networks get deeper in which case existing methods fail to even start training. Finally, we show that using our initialization in conjunction with learning rate warmup is able to reduce the gap between the performance of weight normalized and batch normalized networks.
Recurrent Neural Networks for Semantic Instance Segmentation
Sep 03, 2018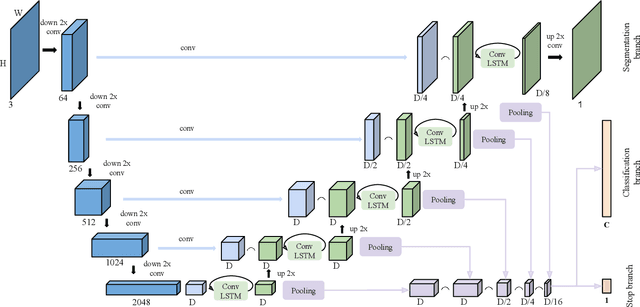

We present a recurrent model for semantic instance segmentation that sequentially generates binary masks and their associated class probabilities for every object in an image. Our proposed system is trainable end-to-end from an input image to a sequence of labeled masks and, compared to methods relying on object proposals, does not require post-processing steps on its output. We study the suitability of our recurrent model on three different instance segmentation benchmarks, namely Pascal VOC 2012, CVPPP Plant Leaf Segmentation and Cityscapes. Further, we analyze the object sorting patterns generated by our model and observe that it learns to follow a consistent pattern, which correlates with the activations learned in the encoder part of our network. Source code and models are available at https://imatge-upc.github.io/rsis/
Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks
Feb 05, 2018



Recurrent Neural Networks (RNNs) continue to show outstanding performance in sequence modeling tasks. However, training RNNs on long sequences often face challenges like slow inference, vanishing gradients and difficulty in capturing long term dependencies. In backpropagation through time settings, these issues are tightly coupled with the large, sequential computational graph resulting from unfolding the RNN in time. We introduce the Skip RNN model which extends existing RNN models by learning to skip state updates and shortens the effective size of the computational graph. This model can also be encouraged to perform fewer state updates through a budget constraint. We evaluate the proposed model on various tasks and show how it can reduce the number of required RNN updates while preserving, and sometimes even improving, the performance of the baseline RNN models. Source code is publicly available at https://imatge-upc.github.io/skiprnn-2017-telecombcn/ .
More cat than cute? Interpretable Prediction of Adjective-Noun Pairs
Aug 21, 2017



The increasing availability of affect-rich multimedia resources has bolstered interest in understanding sentiment and emotions in and from visual content. Adjective-noun pairs (ANP) are a popular mid-level semantic construct for capturing affect via visually detectable concepts such as "cute dog" or "beautiful landscape". Current state-of-the-art methods approach ANP prediction by considering each of these compound concepts as individual tokens, ignoring the underlying relationships in ANPs. This work aims at disentangling the contributions of the `adjectives' and `nouns' in the visual prediction of ANPs. Two specialised classifiers, one trained for detecting adjectives and another for nouns, are fused to predict 553 different ANPs. The resulting ANP prediction model is more interpretable as it allows us to study contributions of the adjective and noun components. Source code and models are available at https://imatge-upc.github.io/affective-2017-musa2/ .
Disentangling Motion, Foreground and Background Features in Videos
Jul 17, 2017



This paper introduces an unsupervised framework to extract semantically rich features for video representation. Inspired by how the human visual system groups objects based on motion cues, we propose a deep convolutional neural network that disentangles motion, foreground and background information. The proposed architecture consists of a 3D convolutional feature encoder for blocks of 16 frames, which is trained for reconstruction tasks over the first and last frames of the sequence. A preliminary supervised experiment was conducted to verify the feasibility of proposed method by training the model with a fraction of videos from the UCF-101 dataset taking as ground truth the bounding boxes around the activity regions. Qualitative results indicate that the network can successfully segment foreground and background in videos as well as update the foreground appearance based on disentangled motion features. The benefits of these learned features are shown in a discriminative classification task, where initializing the network with the proposed pretraining method outperforms both random initialization and autoencoder pretraining. Our model and source code are publicly available at https://imatge-upc.github.io/unsupervised-2017-cvprw/ .
From Pixels to Sentiment: Fine-tuning CNNs for Visual Sentiment Prediction
Jan 27, 2017



Visual multimedia have become an inseparable part of our digital social lives, and they often capture moments tied with deep affections. Automated visual sentiment analysis tools can provide a means of extracting the rich feelings and latent dispositions embedded in these media. In this work, we explore how Convolutional Neural Networks (CNNs), a now de facto computational machine learning tool particularly in the area of Computer Vision, can be specifically applied to the task of visual sentiment prediction. We accomplish this through fine-tuning experiments using a state-of-the-art CNN and via rigorous architecture analysis, we present several modifications that lead to accuracy improvements over prior art on a dataset of images from a popular social media platform. We additionally present visualizations of local patterns that the network learned to associate with image sentiment for insight into how visual positivity (or negativity) is perceived by the model.
Diving Deep into Sentiment: Understanding Fine-tuned CNNs for Visual Sentiment Prediction
Aug 24, 2015



Visual media are powerful means of expressing emotions and sentiments. The constant generation of new content in social networks highlights the need of automated visual sentiment analysis tools. While Convolutional Neural Networks (CNNs) have established a new state-of-the-art in several vision problems, their application to the task of sentiment analysis is mostly unexplored and there are few studies regarding how to design CNNs for this purpose. In this work, we study the suitability of fine-tuning a CNN for visual sentiment prediction as well as explore performance boosting techniques within this deep learning setting. Finally, we provide a deep-dive analysis into a benchmark, state-of-the-art network architecture to gain insight about how to design patterns for CNNs on the task of visual sentiment prediction.