 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis of Covid-19 Tweets using Evolutionary Classification-Based LSTM Model
Jun 13, 2021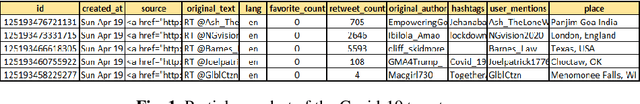



As the Covid-19 outbreaks rapidly all over the world day by day and also affects the lives of million, a number of countries declared complete lock-down to check its intensity. During this lockdown period, social media plat-forms have played an important role to spread information about this pandemic across the world, as people used to express their feelings through the social networks. Considering this catastrophic situation, we developed an experimental approach to analyze the reactions of people on Twitter taking into ac-count the popular words either directly or indirectly based on this pandemic. This paper represents the sentiment analysis on collected large number of tweets on Coronavirus or Covid-19. At first, we analyze the trend of public sentiment on the topics related to Covid-19 epidemic using an evolutionary classification followed by the n-gram analysis. Then we calculated the sentiment ratings on collected tweet based on their class. Finally, we trained the long-short term network using two types of rated tweets to predict sentiment on Covid-19 data and obtained an overall accuracy of 84.46%.
* 11 pages, 8 figures, 5 tables
Parallel Deep Learning-Driven Sarcasm Detection from Pop Culture Text and English Humor Literature
Jun 10, 2021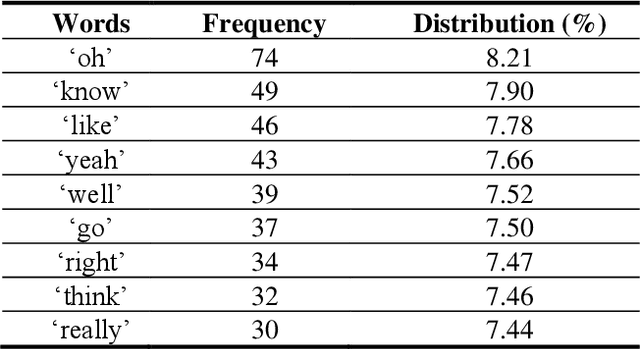
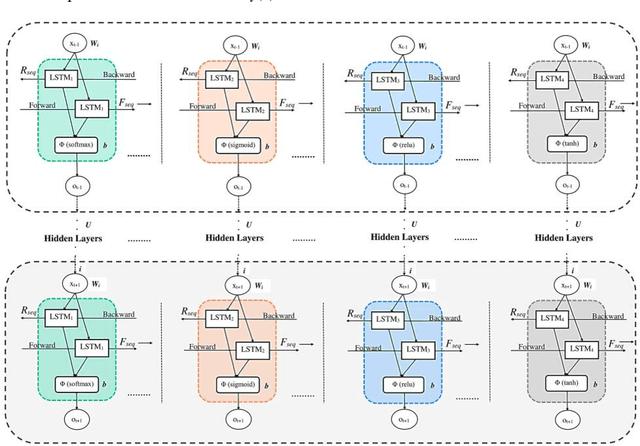
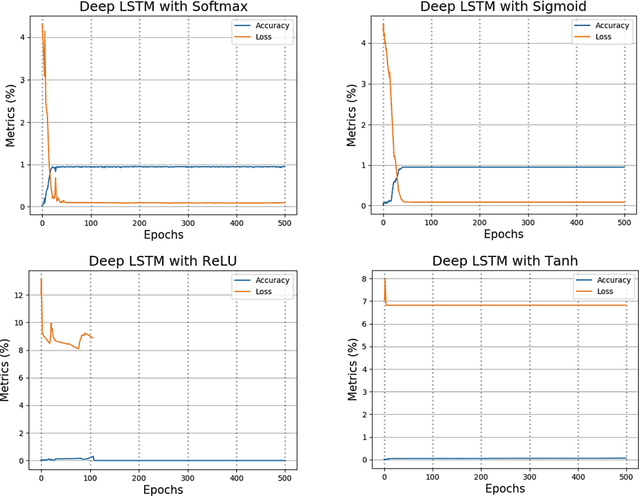
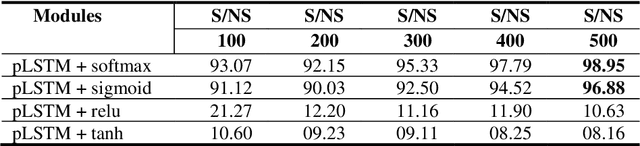
Sarcasm is a sophisticated way of wrapping any immanent truth, mes-sage, or even mockery within a hilarious manner. The advent of communications using social networks has mass-produced new avenues of socialization. It can be further said that humor, irony, sarcasm, and wit are the four chariots of being socially funny in the modern days. In this paper, we manually extract the sarcastic word distribution features of a benchmark pop culture sarcasm corpus, containing sarcastic dialogues and monologues. We generate input sequences formed of the weighted vectors from such words. We further propose an amalgamation of four parallel deep long-short term networks (pLSTM), each with distinctive activation classifier. These modules are primarily aimed at successfully detecting sarcasm from the text corpus. Our proposed model for detecting sarcasm peaks a training accuracy of 98.95% when trained with the discussed dataset. Consecutively, it obtains the highest of 98.31% overall validation accuracy on two handpicked Project Gutenberg English humor literature among all the test cases. Our approach transcends previous state-of-the-art works on several sarcasm corpora and results in a new gold standard performance for sarcasm detection.
* 10 pages, 2 figures, 4 tables
Detecting Generic Music Features with Single Layer Feedforward Network using Unsupervised Hebbian Computation
Aug 31, 2020


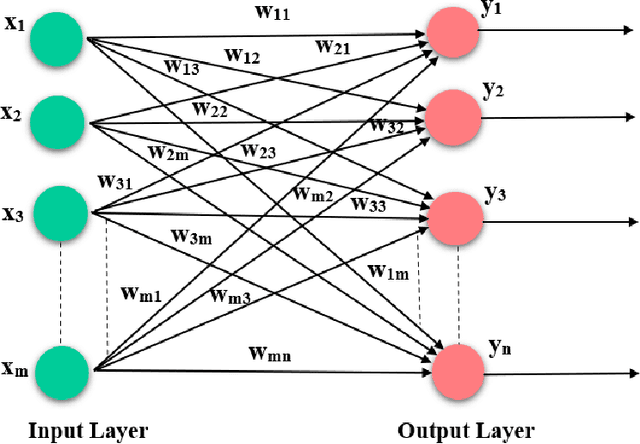
With the ever-increasing number of digital music and vast music track features through popular online music streaming software and apps, feature recognition using the neural network is being used for experimentation to produce a wide range of results across a variety of experiments recently. Through this work, the authors extract information on such features from a popular open-source music corpus and explored new recognition techniques, by applying unsupervised Hebbian learning techniques on their single-layer neural network using the same dataset. The authors show the detailed empirical findings to simulate how such an algorithm can help a single layer feedforward network in training for music feature learning as patterns. The unsupervised training algorithm enhances their proposed neural network to achieve an accuracy of 90.36% for successful music feature detection. For comparative analysis against similar tasks, authors put their results with the likes of several previous benchmark works. They further discuss the limitations and thorough error analysis of their work. The authors hope to discover and gather new information about this particular classification technique and its performance, and further understand future potential directions and prospects that could improve the art of computational music feature recognition.