 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIB-DRR: Incremental Learning with Information-Back Discrete Representation Replay
Paper and Code
Apr 21, 2021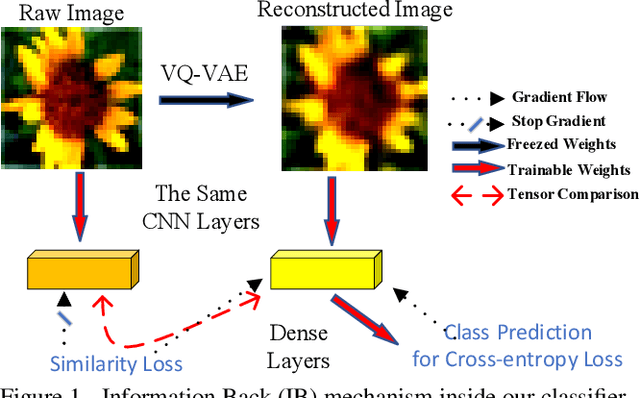
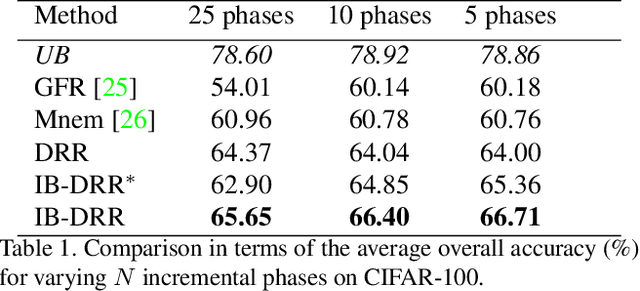
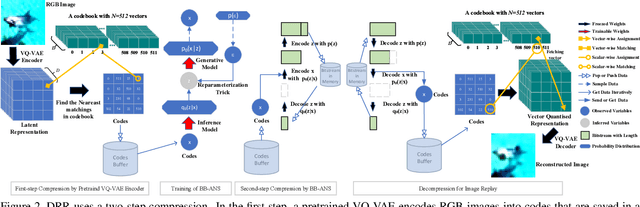
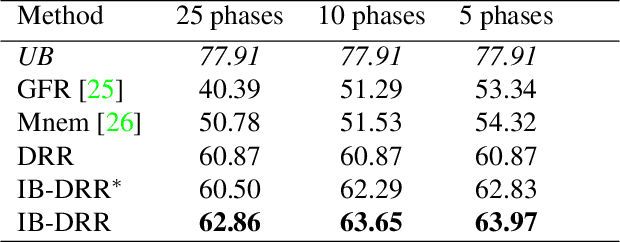
Incremental learning aims to enable machine learning models to continuously acquire new knowledge given new classes, while maintaining the knowledge already learned for old classes. Saving a subset of training samples of previously seen classes in the memory and replaying them during new training phases is proven to be an efficient and effective way to fulfil this aim. It is evident that the larger number of exemplars the model inherits the better performance it can achieve. However, finding a trade-off between the model performance and the number of samples to save for each class is still an open problem for replay-based incremental learning and is increasingly desirable for real-life applications. In this paper, we approach this open problem by tapping into a two-step compression approach. The first step is a lossy compression, we propose to encode input images and save their discrete latent representations in the form of codes that are learned using a hierarchical Vector Quantised Variational Autoencoder (VQ-VAE). In the second step, we further compress codes losslessly by learning a hierarchical latent variable model with bits-back asymmetric numeral systems (BB-ANS). To compensate for the information lost in the first step compression, we introduce an Information Back (IB) mechanism that utilizes real exemplars for a contrastive learning loss to regularize the training of a classifier. By maintaining all seen exemplars' representations in the format of `codes', Discrete Representation Replay (DRR) outperforms the state-of-art method on CIFAR-100 by a margin of 4% accuracy with a much less memory cost required for saving samples. Incorporated with IB and saving a small set of old raw exemplars as well, the accuracy of DRR can be further improved by 2% accuracy.