 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-DETR: Concept Prompt Guide DETR Toward Stronger Universal Object Detection
Dec 13, 2024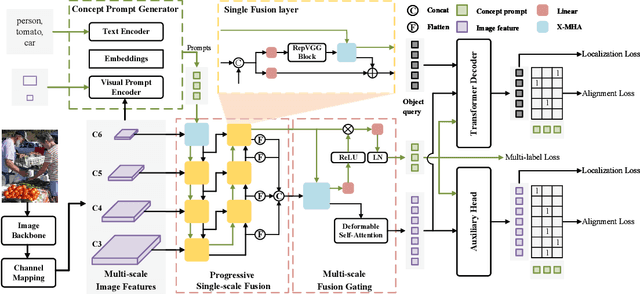
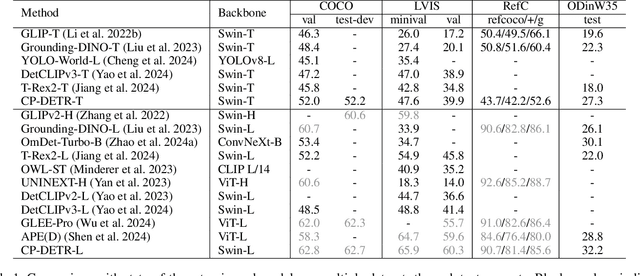
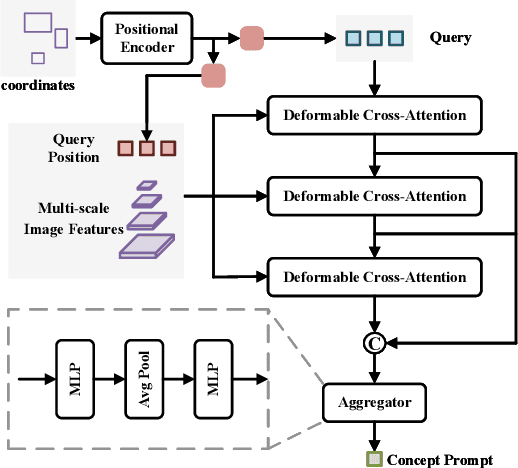
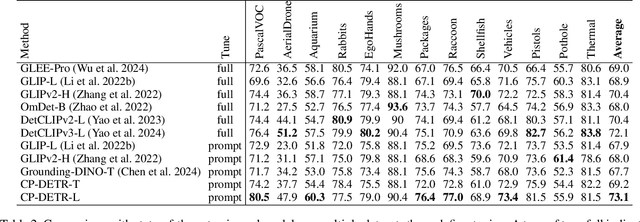
Recent research on universal object detection aims to introduce language in a SoTA closed-set detector and then generalize the open-set concepts by constructing large-scale (text-region) datasets for training. However, these methods face two main challenges: (i) how to efficiently use the prior information in the prompts to genericise objects and (ii) how to reduce alignment bias in the downstream tasks, both leading to sub-optimal performance in some scenarios beyond pre-training. To address these challenges, we propose a strong universal detection foundation model called CP-DETR, which is competitive in almost all scenarios, with only one pre-training weight. Specifically, we design an efficient prompt visual hybrid encoder that enhances the information interaction between prompt and visual through scale-by-scale and multi-scale fusion modules. Then, the hybrid encoder is facilitated to fully utilize the prompted information by prompt multi-label loss and auxiliary detection head. In addition to text prompts, we have designed two practical concept prompt generation methods, visual prompt and optimized prompt, to extract abstract concepts through concrete visual examples and stably reduce alignment bias in downstream tasks. With these effective designs, CP-DETR demonstrates superior universal detection performance in a broad spectrum of scenarios. For example, our Swin-T backbone model achieves 47.6 zero-shot AP on LVIS, and the Swin-L backbone model achieves 32.2 zero-shot AP on ODinW35. Furthermore, our visual prompt generation method achieves 68.4 AP on COCO val by interactive detection, and the optimized prompt achieves 73.1 fully-shot AP on ODinW13.
Multi-Grained Contrast for Data-Efficient Unsupervised Representation Learning
Jul 02, 2024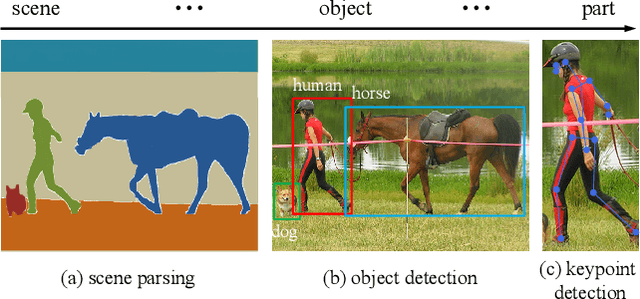
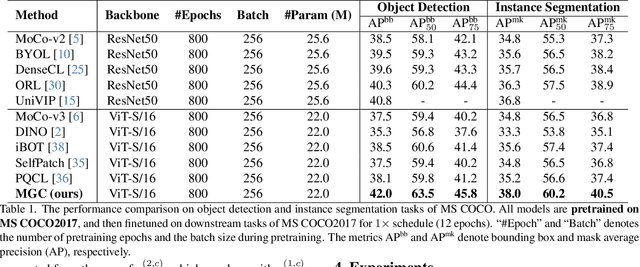
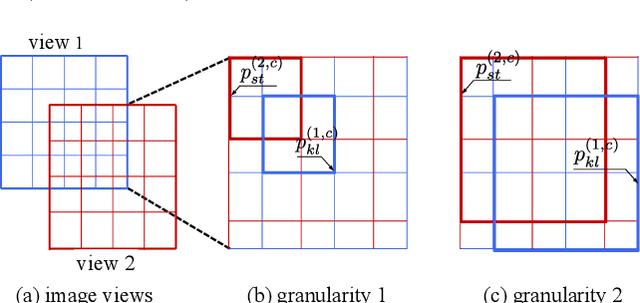
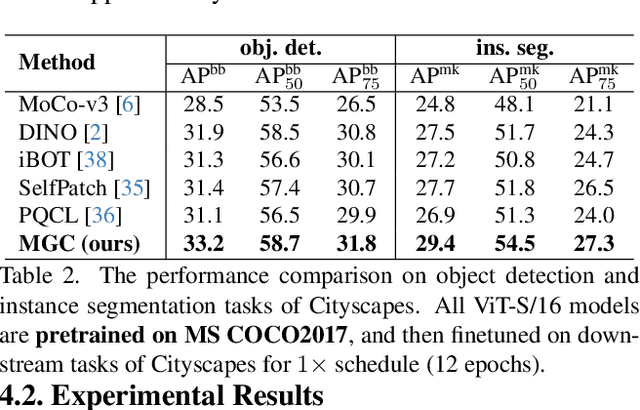
The existing contrastive learning methods mainly focus on single-grained representation learning, e.g., part-level, object-level or scene-level ones, thus inevitably neglecting the transferability of representations on other granularity levels. In this paper, we aim to learn multi-grained representations, which can effectively describe the image on various granularity levels, thus improving generalization on extensive downstream tasks. To this end, we propose a novel Multi-Grained Contrast method (MGC) for unsupervised representation learning. Specifically, we construct delicate multi-grained correspondences between positive views and then conduct multi-grained contrast by the correspondences to learn more general unsupervised representations. Without pretrained on large-scale dataset, our method significantly outperforms the existing state-of-the-art methods on extensive downstream tasks, including object detection, instance segmentation, scene parsing, semantic segmentation and keypoint detection. Moreover, experimental results support the data-efficient property and excellent representation transferability of our method. The source code and trained weights are available at \url{https://github.com/visresearch/mgc}.
Asymmetric Patch Sampling for Contrastive Learning
Jun 05, 2023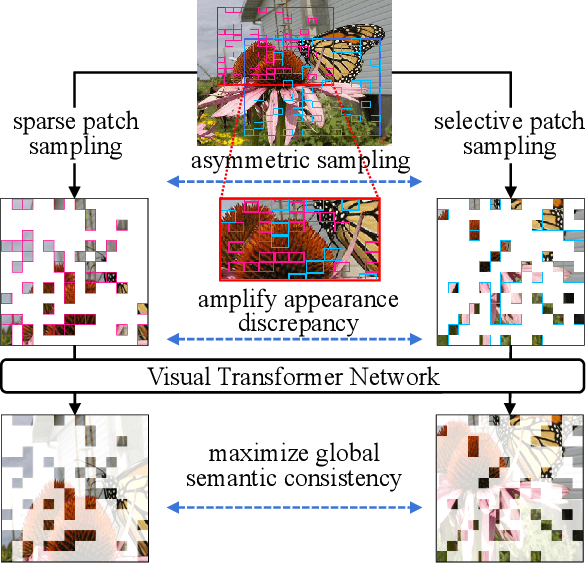
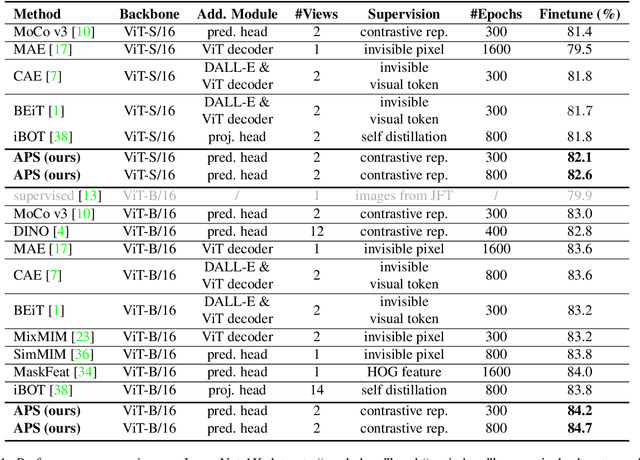
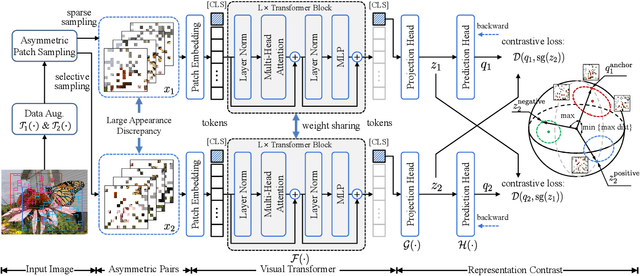

Asymmetric appearance between positive pair effectively reduces the risk of representation degradation in contrastive learning. However, there are still a mass of appearance similarities between positive pair constructed by the existing methods, which inhibits the further representation improvement. In this paper, we propose a novel asymmetric patch sampling strategy for contrastive learning, to further boost the appearance asymmetry for better representations. Specifically, dual patch sampling strategies are applied to the given image, to obtain asymmetric positive pairs. First, sparse patch sampling is conducted to obtain the first view, which reduces spatial redundancy of image and allows a more asymmetric view. Second, a selective patch sampling is proposed to construct another view with large appearance discrepancy relative to the first one. Due to the inappreciable appearance similarity between positive pair, the trained model is encouraged to capture the similarity on semantics, instead of low-level ones. Experimental results demonstrate that our proposed method significantly outperforms the existing self-supervised methods on both ImageNet-1K and CIFAR dataset, e.g., 2.5% finetune accuracy improvement on CIFAR100. Furthermore, our method achieves state-of-the-art performance on downstream tasks, object detection and instance segmentation on COCO.Additionally, compared to other self-supervised methods, our method is more efficient on both memory and computation during training. The source code is available at https://github.com/visresearch/aps.