 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Continual Learning for Gaussian Splatting based Environments Reconstruction on Commercial Off-the-Shelf Edge Devices
Mar 09, 2026Novel view synthesis (NVS) is increasingly relevant for edge robotics, where compact and incrementally updatable 3D scene models are needed for SLAM, navigation, and inspection under tight memory and latency budgets. Variational Bayesian Gaussian Splatting (VBGS) enables replay-free continual updates for the 3DGS algorithm by maintaining a probabilistic scene model, but its high-precision computations and large intermediate tensors make on-device training impractical. We present a precision-adaptive optimization framework that enables VBGS training on resource-constrained hardware without altering its variational formulation. We (i) profile VBGS to identify memory/latency hotspots, (ii) fuse memory-dominant kernels to reduce materialized intermediate tensors, and (iii) automatically assign operation-level precisions via a mixed-precision search with bounded relative error. Across the Blender, Habitat, and Replica datasets, our optimised pipeline reduces peak memory from 9.44 GB to 1.11 GB and training time from ~234 min to ~61 min on an A5000 GPU, while preserving (and in some cases improving) reconstruction quality of the state-of-the-art VBGS baseline. We also enable for the first time NVS training on a commercial embedded platform, the Jetson Orin Nano, reducing per-frame latency by 19x compared to 3DGS.
Towards smart and adaptive agents for active sensing on edge devices
Jan 09, 2025TinyML has made deploying deep learning models on low-power edge devices feasible, creating new opportunities for real-time perception in constrained environments. However, the adaptability of such deep learning methods remains limited to data drift adaptation, lacking broader capabilities that account for the environment's underlying dynamics and inherent uncertainty. Deep learning's scaling laws, which counterbalance this limitation by massively up-scaling data and model size, cannot be applied when deploying on the Edge, where deep learning limitations are further amplified as models are scaled down for deployment on resource-constrained devices. This paper presents a smart agentic system capable of performing on-device perception and planning, enabling active sensing on the edge. By incorporating active inference into our solution, our approach extends beyond deep learning capabilities, allowing the system to plan in dynamic environments while operating in real time with a modest total model size of 2.3 MB. We showcase our proposed system by creating and deploying a saccade agent connected to an IoT camera with pan and tilt capabilities on an NVIDIA Jetson embedded device. The saccade agent controls the camera's field of view following optimal policies derived from the active inference principles, simulating human-like saccadic motion for surveillance and robotics applications.
Navigation under uncertainty: Trajectory prediction and occlusion reasoning with switching dynamical systems
Oct 14, 2024Predicting future trajectories of nearby objects, especially under occlusion, is a crucial task in autonomous driving and safe robot navigation. Prior works typically neglect to maintain uncertainty about occluded objects and only predict trajectories of observed objects using high-capacity models such as Transformers trained on large datasets. While these approaches are effective in standard scenarios, they can struggle to generalize to the long-tail, safety-critical scenarios. In this work, we explore a conceptual framework unifying trajectory prediction and occlusion reasoning under the same class of structured probabilistic generative model, namely, switching dynamical systems. We then present some initial experiments illustrating its capabilities using the Waymo open dataset.
On-Device Domain Learning for Keyword Spotting on Low-Power Extreme Edge Embedded Systems
Mar 12, 2024


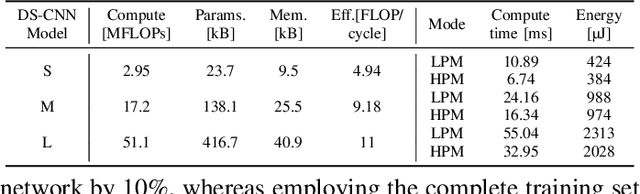
Keyword spotting accuracy degrades when neural networks are exposed to noisy environments. On-site adaptation to previously unseen noise is crucial to recovering accuracy loss, and on-device learning is required to ensure that the adaptation process happens entirely on the edge device. In this work, we propose a fully on-device domain adaptation system achieving up to 14% accuracy gains over already-robust keyword spotting models. We enable on-device learning with less than 10 kB of memory, using only 100 labeled utterances to recover 5% accuracy after adapting to the complex speech noise. We demonstrate that domain adaptation can be achieved on ultra-low-power microcontrollers with as little as 806 mJ in only 14 s on always-on, battery-operated devices.
Robust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

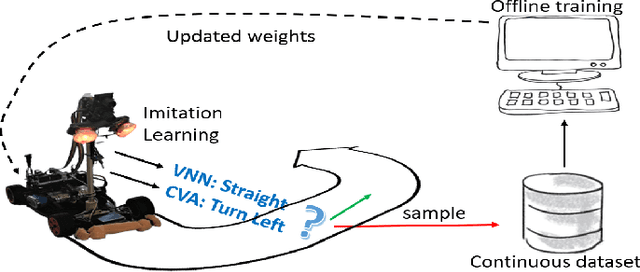
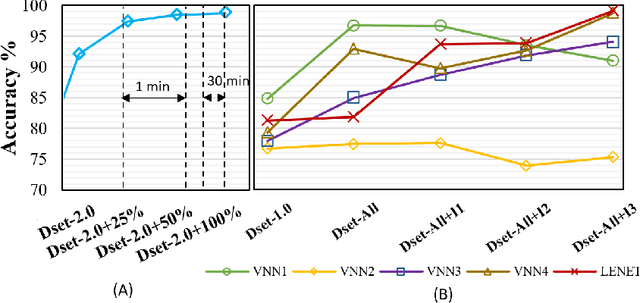
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Automated Design Space Exploration for optimised Deployment of DNN on Arm Cortex-A CPUs
Jun 09, 2020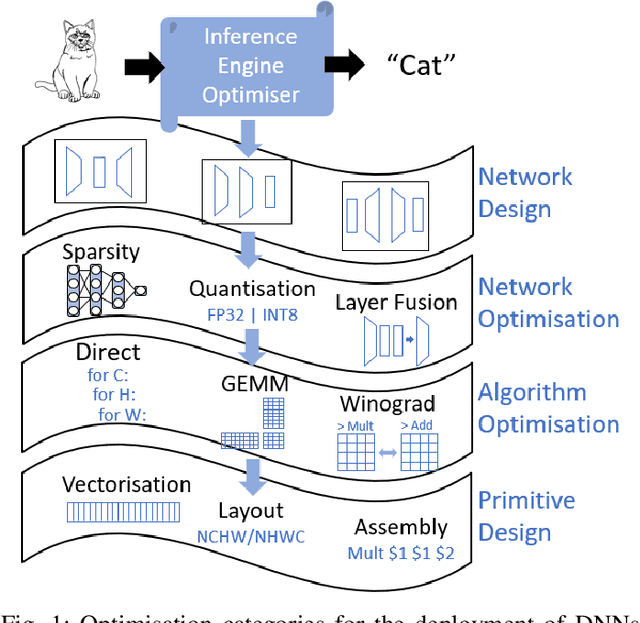
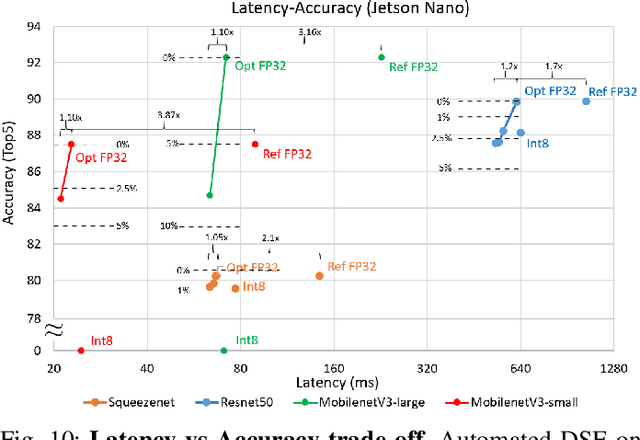
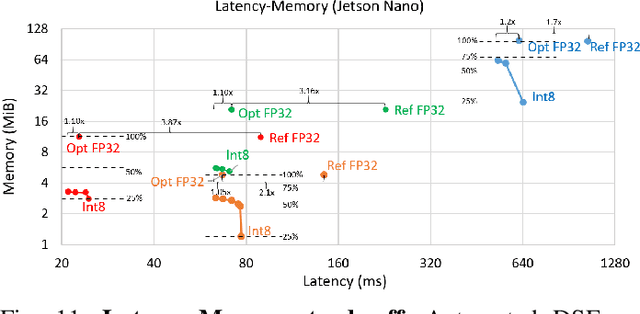
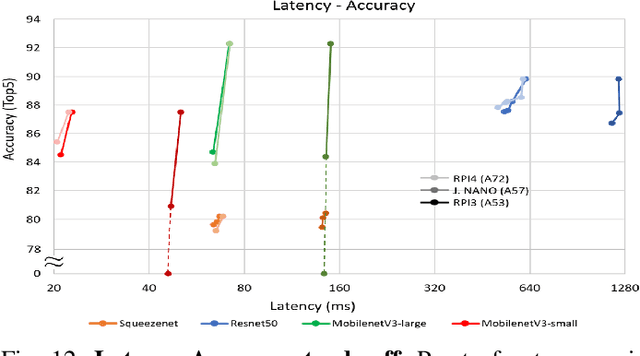
The spread of deep learning on embedded devices has prompted the development of numerous methods to optimise the deployment of deep neural networks (DNN). Works have mainly focused on: i) efficient DNN architectures, ii) network optimisation techniques such as pruning and quantisation, iii) optimised algorithms to speed up the execution of the most computational intensive layers and, iv) dedicated hardware to accelerate the data flow and computation. However, there is a lack of research on the combination of these methods as the space of approaches becomes too large to test and obtain a globally optimised solution, which leads to suboptimal deployment in terms of latency, accuracy, and memory. In this work, we first detail and analyse the methods to improve the deployment of DNNs across the different levels of software optimisation. Building on this knowledge, we present an automated exploration framework to ease the deployment of DNNs for industrial applications by automatically exploring the design space and learning an optimised solution that speeds up the performance and reduces the memory on embedded CPU platforms. The framework relies on a Reinforcement Learning -based search that, combined with a deep learning inference framework, enables the deployment of DNN implementations to obtain empirical measurements on embedded AI applications. Thus, we present a set of results for state-of-the-art DNNs on a range of Arm Cortex-A CPU platforms achieving up to 4x improvement in performance and over 2x reduction in memory with negligible loss in accuracy with respect to the BLAS floating-point implementation.
AI Pipeline - bringing AI to you. End-to-end integration of data, algorithms and deployment tools
Jan 15, 2019



Next generation of embedded Information and Communication Technology (ICT) systems are interconnected collaborative intelligent systems able to perform autonomous tasks. Training and deployment of such systems on Edge devices however require a fine-grained integration of data and tools to achieve high accuracy and overcome functional and non-functional requirements. In this work, we present a modular AI pipeline as an integrating framework to bring data, algorithms and deployment tools together. By these means, we are able to interconnect the different entities or stages of particular systems and provide an end-to-end development of AI products. We demonstrate the effectiveness of the AI pipeline by solving an Automatic Speech Recognition challenge and we show that all the steps leading to an end-to-end development for Key-word Spotting tasks: importing, partitioning and pre-processing of speech data, training of different neural network architectures and their deployment on heterogeneous embedded platforms.
Learning to infer: RL-based search for DNN primitive selection on Heterogeneous Embedded Systems
Nov 18, 2018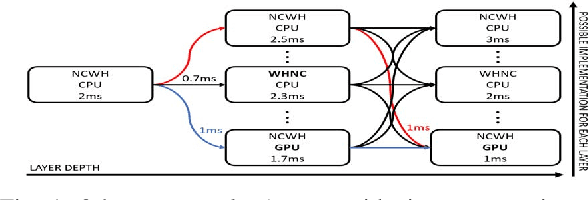
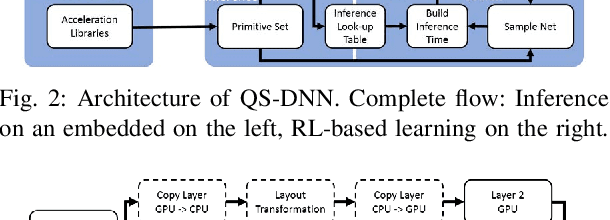
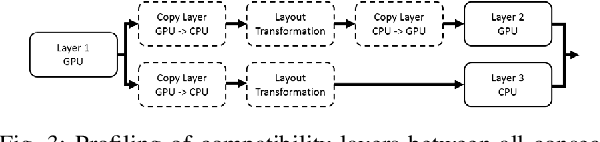
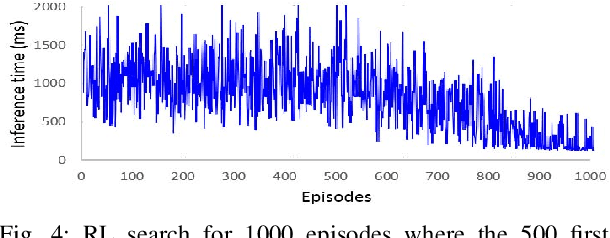
Deep Learning is increasingly being adopted by industry for computer vision applications running on embedded devices. While Convolutional Neural Networks' accuracy has achieved a mature and remarkable state, inference latency and throughput are a major concern especially when targeting low-cost and low-power embedded platforms. CNNs' inference latency may become a bottleneck for Deep Learning adoption by industry, as it is a crucial specification for many real-time processes. Furthermore, deployment of CNNs across heterogeneous platforms presents major compatibility issues due to vendor-specific technology and acceleration libraries. In this work, we present QS-DNN, a fully automatic search based on Reinforcement Learning which, combined with an inference engine optimizer, efficiently explores through the design space and empirically finds the optimal combinations of libraries and primitives to speed up the inference of CNNs on heterogeneous embedded devices. We show that, an optimized combination can achieve 45x speedup in inference latency on CPU compared to a dependency-free baseline and 2x on average on GPGPU compared to the best vendor library. Further, we demonstrate that, the quality of results and time "to-solution" is much better than with Random Search and achieves up to 15x better results for a short-time search.
QUENN: QUantization Engine for low-power Neural Networks
Nov 14, 2018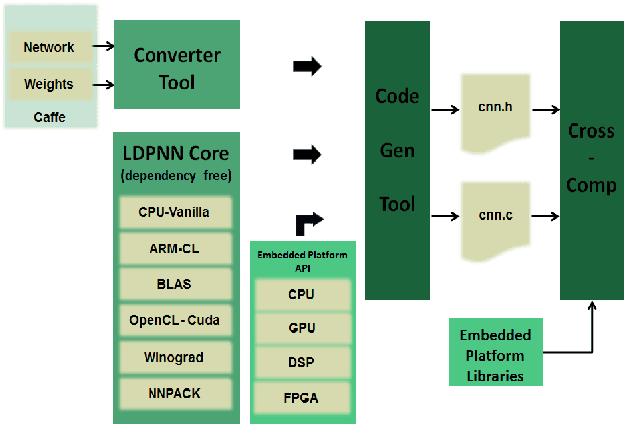
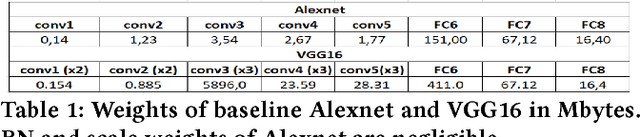
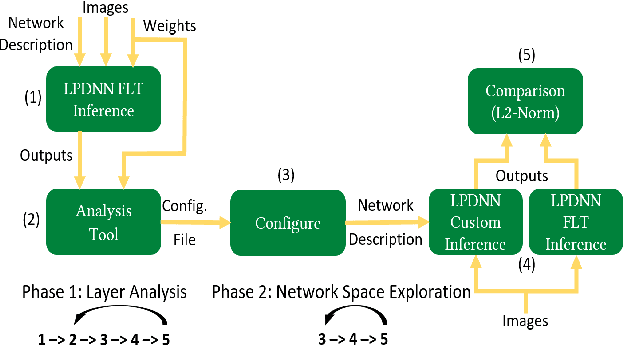

Deep Learning is moving to edge devices, ushering in a new age of distributed Artificial Intelligence (AI). The high demand of computational resources required by deep neural networks may be alleviated by approximate computing techniques, and most notably reduced-precision arithmetic with coarsely quantized numerical representations. In this context, Bonseyes comes in as an initiative to enable stakeholders to bring AI to low-power and autonomous environments such as: Automotive, Medical Healthcare and Consumer Electronics. To achieve this, we introduce LPDNN, a framework for optimized deployment of Deep Neural Networks on heterogeneous embedded devices. In this work, we detail the quantization engine that is integrated in LPDNN. The engine depends on a fine-grained workflow which enables a Neural Network Design Exploration and a sensitivity analysis of each layer for quantization. We demonstrate the engine with a case study on Alexnet and VGG16 for three different techniques for direct quantization: standard fixed-point, dynamic fixed-point and k-means clustering, and demonstrate the potential of the latter. We argue that using a Gaussian quantizer with k-means clustering can achieve better performance than linear quantizers. Without retraining, we achieve over 55.64\% saving for weights' storage and 69.17\% for run-time memory accesses with less than 1\% drop in top5 accuracy in Imagenet.