 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ultra-Low Power Wearable BMI System with Continual Learning Capabilities
Sep 16, 2024



Driven by the progress in efficient embedded processing, there is an accelerating trend toward running machine learning models directly on wearable Brain-Machine Interfaces (BMIs) to improve portability and privacy and maximize battery life. However, achieving low latency and high classification performance remains challenging due to the inherent variability of electroencephalographic (EEG) signals across sessions and the limited onboard resources. This work proposes a comprehensive BMI workflow based on a CNN-based Continual Learning (CL) framework, allowing the system to adapt to inter-session changes. The workflow is deployed on a wearable, parallel ultra-low power BMI platform (BioGAP). Our results based on two in-house datasets, Dataset A and Dataset B, show that the CL workflow improves average accuracy by up to 30.36% and 10.17%, respectively. Furthermore, when implementing the continual learning on a Parallel Ultra-Low Power (PULP) microcontroller (GAP9), it achieves an energy consumption as low as 0.45mJ per inference and an adaptation time of only 21.5ms, yielding around 25h of battery life with a small 100mAh, 3.7V battery on BioGAP. Our setup, coupled with the compact CNN model and on-device CL capabilities, meets users' needs for improved privacy, reduced latency, and enhanced inter-session performance, offering good promise for smart embedded real-world BMIs.
Train-On-Request: An On-Device Continual Learning Workflow for Adaptive Real-World Brain Machine Interfaces
Sep 13, 2024



Brain-machine interfaces (BMIs) are expanding beyond clinical settings thanks to advances in hardware and algorithms. However, they still face challenges in user-friendliness and signal variability. Classification models need periodic adaptation for real-life use, making an optimal re-training strategy essential to maximize user acceptance and maintain high performance. We propose TOR, a train-on-request workflow that enables user-specific model adaptation to novel conditions, addressing signal variability over time. Using continual learning, TOR preserves knowledge across sessions and mitigates inter-session variability. With TOR, users can refine, on demand, the model through on-device learning (ODL) to enhance accuracy adapting to changing conditions. We evaluate the proposed methodology on a motor-movement dataset recorded with a non-stigmatizing wearable BMI headband, achieving up to 92% accuracy and a re-calibration time as low as 1.6 minutes, a 46% reduction compared to a naive transfer learning workflow. We additionally demonstrate that TOR is suitable for ODL in extreme edge settings by deploying the training procedure on a RISC-V ultra-low-power SoC (GAP9), resulting in 21.6 ms of latency and 1 mJ of energy consumption per training step. To the best of our knowledge, this work is the first demonstration of an online, energy-efficient, dynamic adaptation of a BMI model to the intrinsic variability of EEG signals in real-time settings.
12 mJ per Class On-Device Online Few-Shot Class-Incremental Learning
Mar 12, 2024



Few-Shot Class-Incremental Learning (FSCIL) enables machine learning systems to expand their inference capabilities to new classes using only a few labeled examples, without forgetting the previously learned classes. Classical backpropagation-based learning and its variants are often unsuitable for battery-powered, memory-constrained systems at the extreme edge. In this work, we introduce Online Few-Shot Class-Incremental Learning (O-FSCIL), based on a lightweight model consisting of a pretrained and metalearned feature extractor and an expandable explicit memory storing the class prototypes. The architecture is pretrained with a novel feature orthogonality regularization and metalearned with a multi-margin loss. For learning a new class, our approach extends the explicit memory with novel class prototypes, while the remaining architecture is kept frozen. This allows learning previously unseen classes based on only a few examples with one single pass (hence online). O-FSCIL obtains an average accuracy of 68.62% on the FSCIL CIFAR100 benchmark, achieving state-of-the-art results. Tailored for ultra-low-power platforms, we implement O-FSCIL on the 60 mW GAP9 microcontroller, demonstrating online learning capabilities within just 12 mJ per new class.
Boosting keyword spotting through on-device learnable user speech characteristics
Mar 12, 2024



Keyword spotting systems for always-on TinyML-constrained applications require on-site tuning to boost the accuracy of offline trained classifiers when deployed in unseen inference conditions. Adapting to the speech peculiarities of target users requires many in-domain samples, often unavailable in real-world scenarios. Furthermore, current on-device learning techniques rely on computationally intensive and memory-hungry backbone update schemes, unfit for always-on, battery-powered devices. In this work, we propose a novel on-device learning architecture, composed of a pretrained backbone and a user-aware embedding learning the user's speech characteristics. The so-generated features are fused and used to classify the input utterance. For domain shifts generated by unseen speakers, we measure error rate reductions of up to 19% from 30.1% to 24.3% based on the 35-class problem of the Google Speech Commands dataset, through the inexpensive update of the user projections. We moreover demonstrate the few-shot learning capabilities of our proposed architecture in sample- and class-scarce learning conditions. With 23.7 kparameters and 1 MFLOP per epoch required for on-device training, our system is feasible for TinyML applications aimed at battery-powered microcontrollers.
On-Device Domain Learning for Keyword Spotting on Low-Power Extreme Edge Embedded Systems
Mar 12, 2024


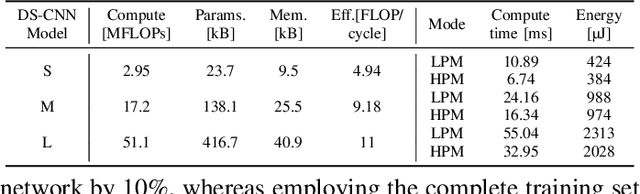
Keyword spotting accuracy degrades when neural networks are exposed to noisy environments. On-site adaptation to previously unseen noise is crucial to recovering accuracy loss, and on-device learning is required to ensure that the adaptation process happens entirely on the edge device. In this work, we propose a fully on-device domain adaptation system achieving up to 14% accuracy gains over already-robust keyword spotting models. We enable on-device learning with less than 10 kB of memory, using only 100 labeled utterances to recover 5% accuracy after adapting to the complex speech noise. We demonstrate that domain adaptation can be achieved on ultra-low-power microcontrollers with as little as 806 mJ in only 14 s on always-on, battery-operated devices.
MS-RANAS: Multi-Scale Resource-Aware Neural Architecture Search
Sep 29, 2020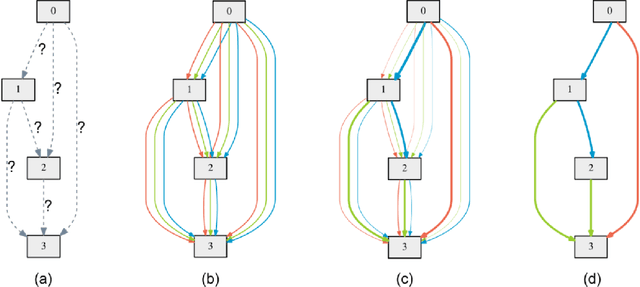
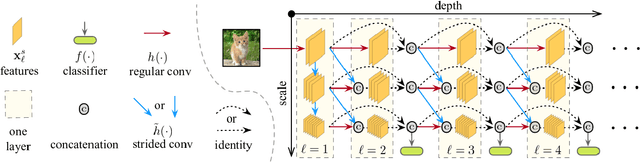
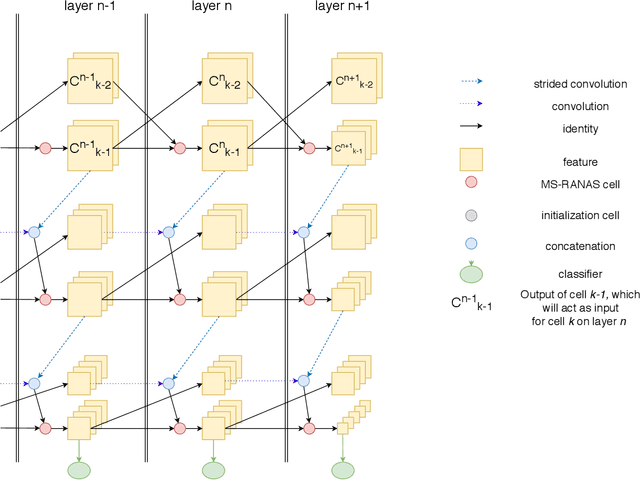
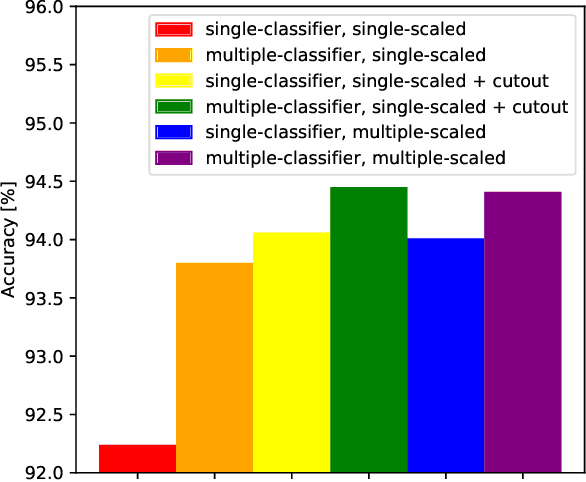
Neural Architecture Search (NAS) has proved effective in offering outperforming alternatives to handcrafted neural networks. In this paper we analyse the benefits of NAS for image classification tasks under strict computational constraints. Our aim is to automate the design of highly efficient deep neural networks, capable of offering fast and accurate predictions and that could be deployed on a low-memory, low-power system-on-chip. The task thus becomes a three-party trade-off between accuracy, computational complexity, and memory requirements. To address this concern, we propose Multi-Scale Resource-Aware Neural Architecture Search (MS-RANAS). We employ a one-shot architecture search approach in order to obtain a reduced search cost and we focus on an anytime prediction setting. Through the usage of multiple-scaled features and early classifiers, we achieved state-of-the-art results in terms of accuracy-speed trade-off.