 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

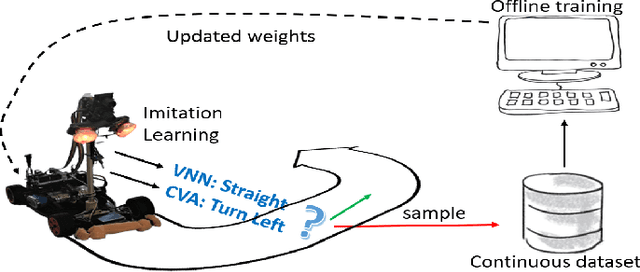
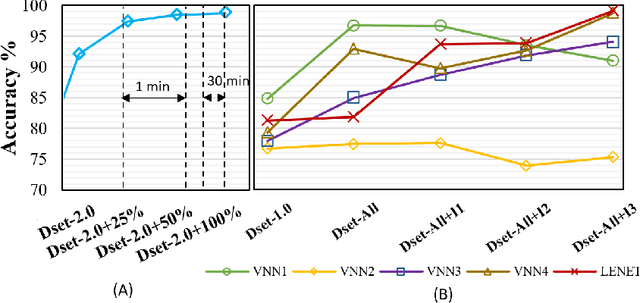
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Automated Design Space Exploration for optimised Deployment of DNN on Arm Cortex-A CPUs
Jun 09, 2020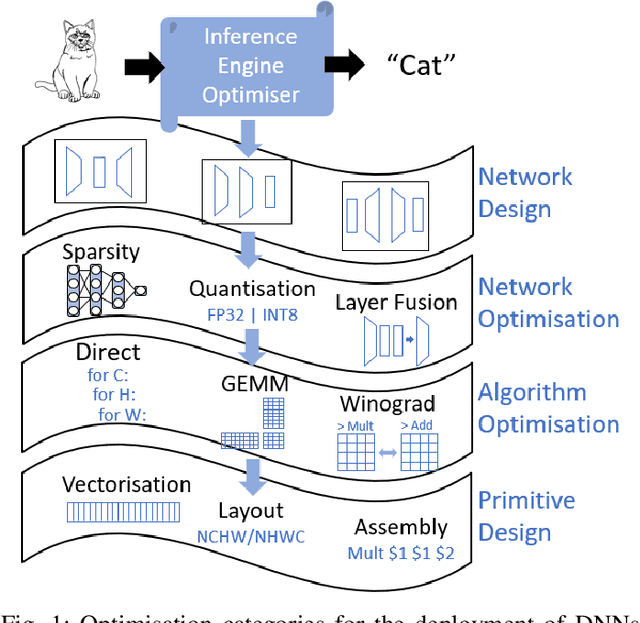
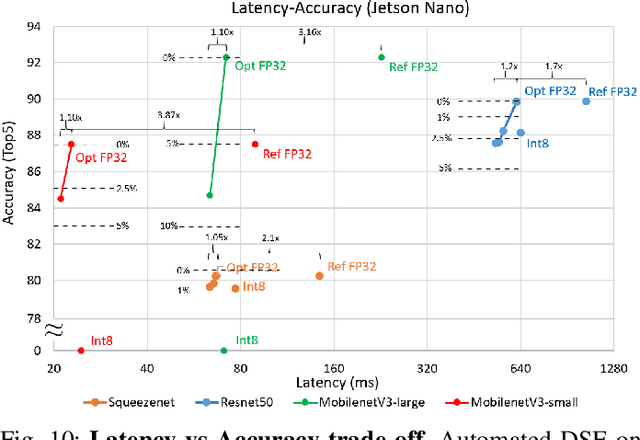
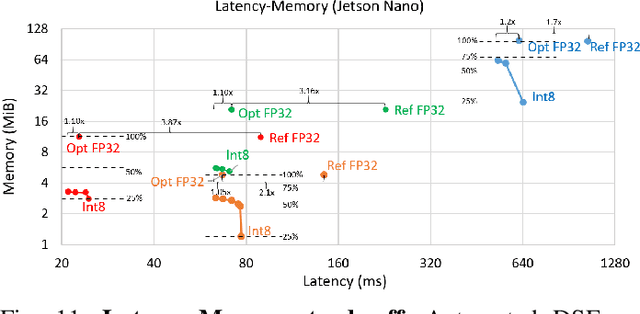
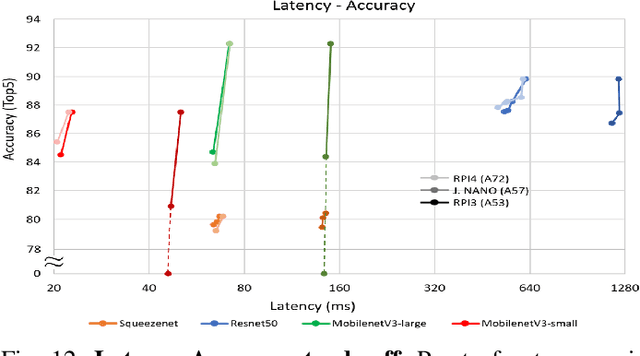
The spread of deep learning on embedded devices has prompted the development of numerous methods to optimise the deployment of deep neural networks (DNN). Works have mainly focused on: i) efficient DNN architectures, ii) network optimisation techniques such as pruning and quantisation, iii) optimised algorithms to speed up the execution of the most computational intensive layers and, iv) dedicated hardware to accelerate the data flow and computation. However, there is a lack of research on the combination of these methods as the space of approaches becomes too large to test and obtain a globally optimised solution, which leads to suboptimal deployment in terms of latency, accuracy, and memory. In this work, we first detail and analyse the methods to improve the deployment of DNNs across the different levels of software optimisation. Building on this knowledge, we present an automated exploration framework to ease the deployment of DNNs for industrial applications by automatically exploring the design space and learning an optimised solution that speeds up the performance and reduces the memory on embedded CPU platforms. The framework relies on a Reinforcement Learning -based search that, combined with a deep learning inference framework, enables the deployment of DNN implementations to obtain empirical measurements on embedded AI applications. Thus, we present a set of results for state-of-the-art DNNs on a range of Arm Cortex-A CPU platforms achieving up to 4x improvement in performance and over 2x reduction in memory with negligible loss in accuracy with respect to the BLAS floating-point implementation.
Learning to infer: RL-based search for DNN primitive selection on Heterogeneous Embedded Systems
Nov 18, 2018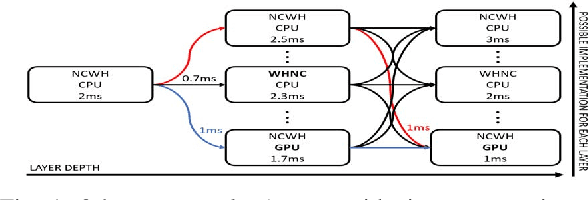
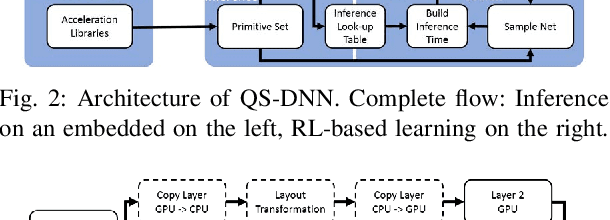
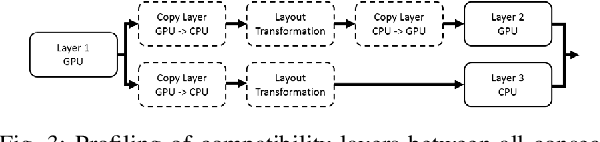
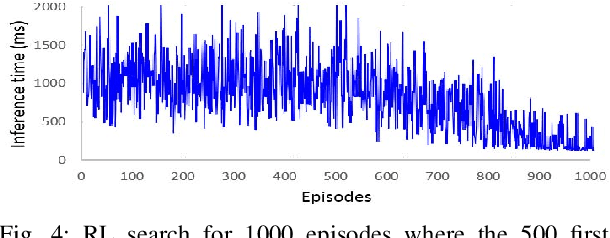
Deep Learning is increasingly being adopted by industry for computer vision applications running on embedded devices. While Convolutional Neural Networks' accuracy has achieved a mature and remarkable state, inference latency and throughput are a major concern especially when targeting low-cost and low-power embedded platforms. CNNs' inference latency may become a bottleneck for Deep Learning adoption by industry, as it is a crucial specification for many real-time processes. Furthermore, deployment of CNNs across heterogeneous platforms presents major compatibility issues due to vendor-specific technology and acceleration libraries. In this work, we present QS-DNN, a fully automatic search based on Reinforcement Learning which, combined with an inference engine optimizer, efficiently explores through the design space and empirically finds the optimal combinations of libraries and primitives to speed up the inference of CNNs on heterogeneous embedded devices. We show that, an optimized combination can achieve 45x speedup in inference latency on CPU compared to a dependency-free baseline and 2x on average on GPGPU compared to the best vendor library. Further, we demonstrate that, the quality of results and time "to-solution" is much better than with Random Search and achieves up to 15x better results for a short-time search.
QUENN: QUantization Engine for low-power Neural Networks
Nov 14, 2018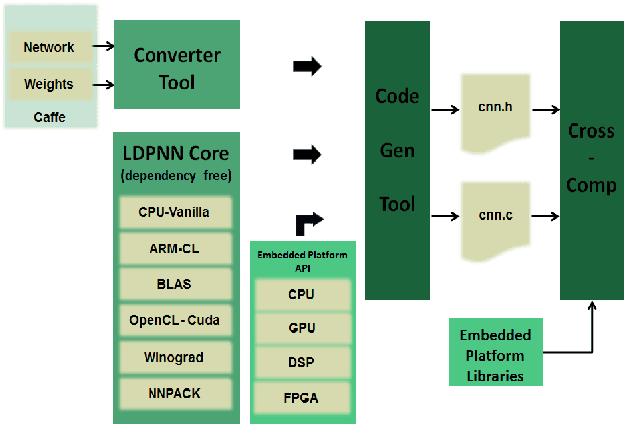
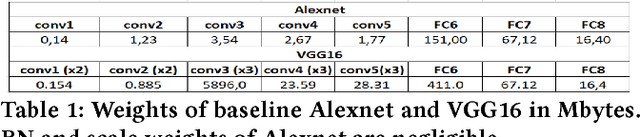
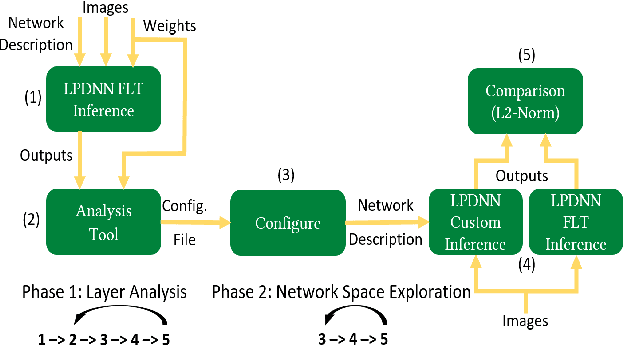

Deep Learning is moving to edge devices, ushering in a new age of distributed Artificial Intelligence (AI). The high demand of computational resources required by deep neural networks may be alleviated by approximate computing techniques, and most notably reduced-precision arithmetic with coarsely quantized numerical representations. In this context, Bonseyes comes in as an initiative to enable stakeholders to bring AI to low-power and autonomous environments such as: Automotive, Medical Healthcare and Consumer Electronics. To achieve this, we introduce LPDNN, a framework for optimized deployment of Deep Neural Networks on heterogeneous embedded devices. In this work, we detail the quantization engine that is integrated in LPDNN. The engine depends on a fine-grained workflow which enables a Neural Network Design Exploration and a sensitivity analysis of each layer for quantization. We demonstrate the engine with a case study on Alexnet and VGG16 for three different techniques for direct quantization: standard fixed-point, dynamic fixed-point and k-means clustering, and demonstrate the potential of the latter. We argue that using a Gaussian quantizer with k-means clustering can achieve better performance than linear quantizers. Without retraining, we achieve over 55.64\% saving for weights' storage and 69.17\% for run-time memory accesses with less than 1\% drop in top5 accuracy in Imagenet.