 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Is Your Friend in Show, Suggest and Tell
Dec 10, 2025



Diffusion Denoising models demonstrated impressive results across generative Computer Vision tasks, but they still fail to outperform standard autoregressive solutions in the discrete domain, and only match them at best. In this work, we propose a different paradigm by adopting diffusion models to provide suggestions to the autoregressive generation rather than replacing them. By doing so, we combine the bidirectional and refining capabilities of the former with the strong linguistic structure provided by the latter. To showcase its effectiveness, we present Show, Suggest and Tell (SST), which achieves State-of-the-Art results on COCO, among models in a similar setting. In particular, SST achieves 125.1 CIDEr-D on the COCO dataset without Reinforcement Learning, outperforming both autoregressive and diffusion model State-of-the-Art results by 1.5 and 2.5 points. On top of the strong results, we performed extensive experiments to validate the proposal and analyze the impact of the suggestion module. Results demonstrate a positive correlation between suggestion and caption quality, overall indicating a currently underexplored but promising research direction. Code will be available at: https://github.com/jchenghu/show\_suggest\_tell.
Shifted Window Fourier Transform And Retention For Image Captioning
Aug 25, 2024Image Captioning is an important Language and Vision task that finds application in a variety of contexts, ranging from healthcare to autonomous vehicles. As many real-world applications rely on devices with limited resources, much effort in the field was put into the development of lighter and faster models. However, much of the current optimizations focus on the Transformer architecture in contrast to the existence of more efficient methods. In this work, we introduce SwiFTeR, an architecture almost entirely based on Fourier Transform and Retention, to tackle the main efficiency bottlenecks of current light image captioning models, being the visual backbone's onerosity, and the decoder's quadratic cost. SwiFTeR is made of only 20M parameters, and requires 3.1 GFLOPs for a single forward pass. Additionally, it showcases superior scalability to the caption length and its small memory requirements enable more images to be processed in parallel, compared to the traditional transformer-based architectures. For instance, it can generate 400 captions in one second. Although, for the time being, the caption quality is lower (110.2 CIDEr-D), most of the decrease is not attributed to the architecture but rather an incomplete training practice which currently leaves much room for improvements. Overall, SwiFTeR points toward a promising direction to new efficient architectural design. The implementation code will be released in the future.
Bidirectional Awareness Induction in Autoregressive Seq2Seq Models
Aug 25, 2024

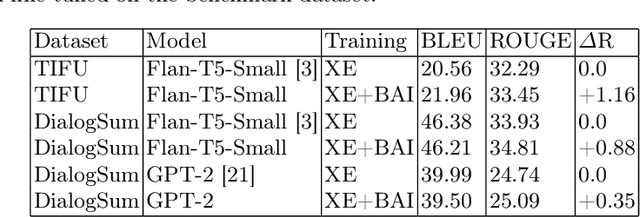

Autoregressive Sequence-To-Sequence models are the foundation of many Deep Learning achievements in major research fields such as Vision and Natural Language Processing. Despite that, they still present significant limitations. For instance, when errors occur in the early steps of the prediction, the whole output is severely affected. Such reliance on previously predicted tokens and the inherent computational unfriendliness of sequential algorithms, motivated researchers to explore different architectures and methods in the search for bidirectional approaches. In this work, we introduce the Bidirectional Awareness Induction (BAI), a training method that leverages a subset of elements in the network, the Pivots, to perform bidirectional learning without breaking the autoregressive constraints. To showcase its flexibility, we apply the method to three architectures, the Transformer, ExpansionNet v2 and GPT, then perform experiments over three tasks. Experimental results showcase BAI's effectiveness on all selected tasks and architectures. In particular, we observed an increase of up to 2.4 CIDEr in Image-Captioning, 4.96 BLEU in Neural Machine Translation, and 1.16 ROUGE in Text Summarization compared to the respective baselines. Notably, BAI not only has a positive impact on models trained from scratch but on pre-trained models as well. Such an aspect, combined with the absence of architectural requirements synergizes well with the current trend of LLMs.
Heterogeneous Encoders Scaling In The Transformer For Neural Machine Translation
Dec 26, 2023



Although the Transformer is currently the best-performing architecture in the homogeneous configuration (self-attention only) in Neural Machine Translation, many State-of-the-Art models in Natural Language Processing are made of a combination of different Deep Learning approaches. However, these models often focus on combining a couple of techniques only and it is unclear why some methods are chosen over others. In this work, we investigate the effectiveness of integrating an increasing number of heterogeneous methods. Based on a simple combination strategy and performance-driven synergy criteria, we designed the Multi-Encoder Transformer, which consists of up to five diverse encoders. Results showcased that our approach can improve the quality of the translation across a variety of languages and dataset sizes and it is particularly effective in low-resource languages where we observed a maximum increase of 7.16 BLEU compared to the single-encoder model.
A request for clarity over the End of Sequence token in the Self-Critical Sequence Training
May 20, 2023The Image Captioning research field is currently compromised by the lack of transparency and awareness over the End-of-Sequence token (<Eos>) in the Self-Critical Sequence Training. If the <Eos> token is omitted, a model can boost its performance up to +4.1 CIDEr-D using trivial sentence fragments. While this phenomenon poses an obstacle to a fair evaluation and comparison of established works, people involved in new projects are given the arduous choice between lower scores and unsatisfactory descriptions due to the competitive nature of the research. This work proposes to solve the problem by spreading awareness of the issue itself. In particular, we invite future works to share a simple and informative signature with the help of a library called SacreEOS. Code available at \emph{\href{https://github.com/jchenghu/sacreeos}{https://github.com/jchenghu/sacreeos}}
ExpansionNet v2: Block Static Expansion in fast end to end training for Image Captioning
Aug 19, 2022


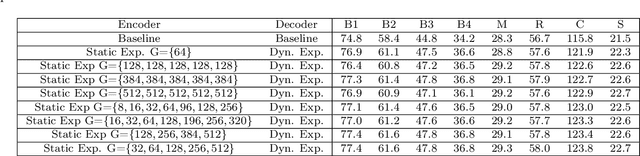
Expansion methods explore the possibility of performance bottlenecks in the input length in Deep Learning methods. In this work, we introduce the Block Static Expansion which distributes and processes the input over a heterogeneous and arbitrarily big collection of sequences characterized by a different length compared to the input one. Adopting this method we introduce a model called ExpansionNet v2, which is trained using our novel training strategy, designed to be not only effective but also 6 times faster compared to the standard approach of recent works in Image Captioning. The model achieves the state of art performance over the MS-COCO 2014 captioning challenge with a score of 143.7 CIDEr-D in the offline test split, 140.8 CIDEr-D in the online evaluation server and 72.9 All-CIDEr on the nocaps validation set. Source code available at: https://github.com/jchenghu/ExpansionNet_v2
A TinyML Platform for On-Device Continual Learning with Quantized Latent Replays
Oct 20, 2021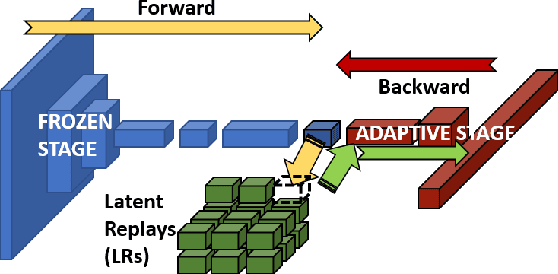

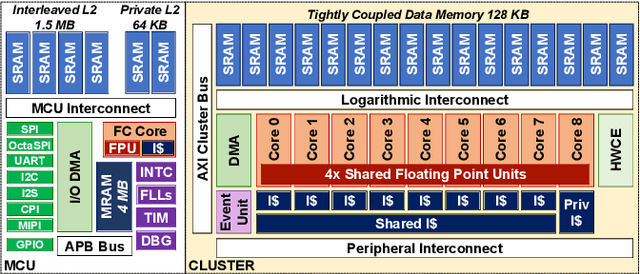
In the last few years, research and development on Deep Learning models and techniques for ultra-low-power devices in a word, TinyML has mainly focused on a train-then-deploy assumption, with static models that cannot be adapted to newly collected data without cloud-based data collection and fine-tuning. Latent Replay-based Continual Learning (CL) techniques[1] enable online, serverless adaptation in principle, but so farthey have still been too computation and memory-hungry for ultra-low-power TinyML devices, which are typically based on microcontrollers. In this work, we introduce a HW/SW platform for end-to-end CL based on a 10-core FP32-enabled parallel ultra-low-power (PULP) processor. We rethink the baseline Latent Replay CL algorithm, leveraging quantization of the frozen stage of the model and Latent Replays (LRs) to reduce their memory cost with minimal impact on accuracy. In particular, 8-bit compression of the LR memory proves to be almost lossless (-0.26% with 3000LR) compared to the full-precision baseline implementation, but requires 4x less memory, while 7-bit can also be used with an additional minimal accuracy degradation (up to 5%). We also introduce optimized primitives for forward and backward propagation on the PULP processor. Our results show that by combining these techniques, continual learning can be achieved in practice using less than 64MB of memory an amount compatible with embedding in TinyML devices. On an advanced 22nm prototype of our platform, called VEGA, the proposed solution performs onaverage 65x faster than a low-power STM32 L4 microcontroller, being 37x more energy efficient enough for a lifetime of 535h when learning a new mini-batch of data once every minute.
Leveraging Automated Mixed-Low-Precision Quantization for tiny edge microcontrollers
Aug 12, 2020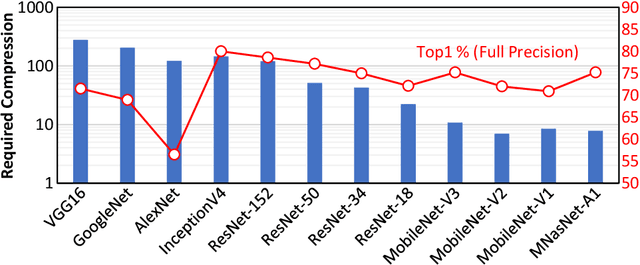
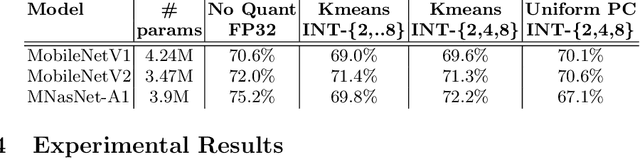
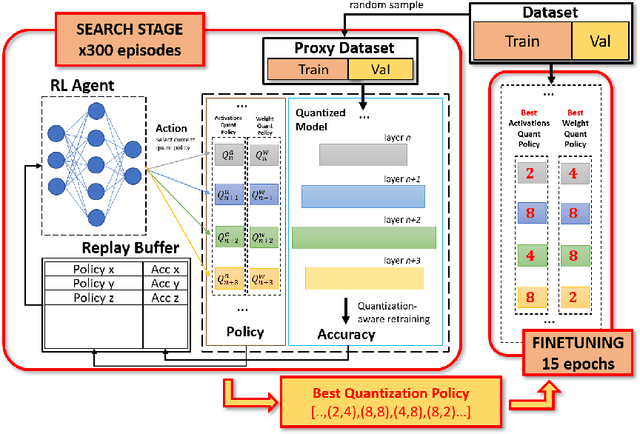
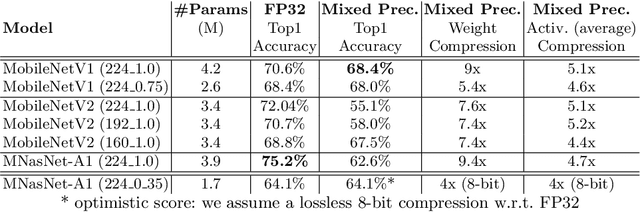
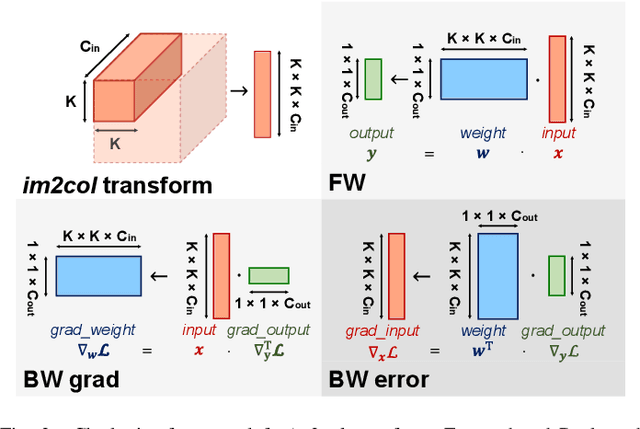
The severe on-chip memory limitations are currently preventing the deployment of the most accurate Deep Neural Network (DNN) models on tiny MicroController Units (MCUs), even if leveraging an effective 8-bit quantization scheme. To tackle this issue, in this paper we present an automated mixed-precision quantization flow based on the HAQ framework but tailored for the memory and computational characteristics of MCU devices. Specifically, a Reinforcement Learning agent searches for the best uniform quantization levels, among 2, 4, 8 bits, of individual weight and activation tensors, under the tight constraints on RAM and FLASH embedded memory sizes. We conduct an experimental analysis on MobileNetV1, MobileNetV2 and MNasNet models for Imagenet classification. Concerning the quantization policy search, the RL agent selects quantization policies that maximize the memory utilization. Given an MCU-class memory bound of 2MB for weight-only quantization, the compressed models produced by the mixed-precision engine result as accurate as the state-of-the-art solutions quantized with a non-uniform function, which is not tailored for CPUs featuring integer-only arithmetic. This denotes the viability of uniform quantization, required for MCU deployments, for deep weights compression. When also limiting the activation memory budget to 512kB, the best MobileNetV1 model scores up to 68.4% on Imagenet thanks to the found quantization policy, resulting to be 4% more accurate than the other 8-bit networks fitting the same memory constraints.
Robust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

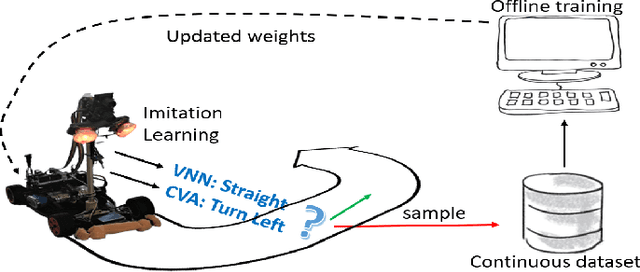
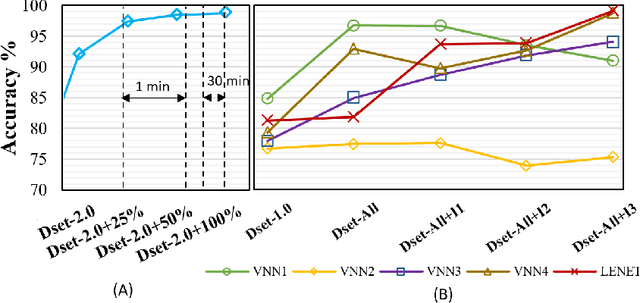
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Memory-Driven Mixed Low Precision Quantization For Enabling Deep Network Inference On Microcontrollers
May 30, 2019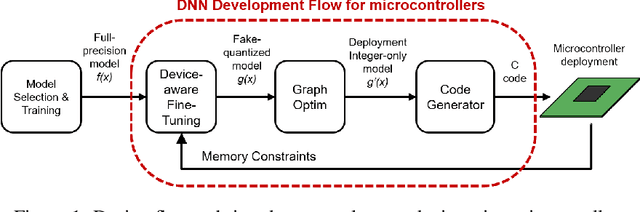

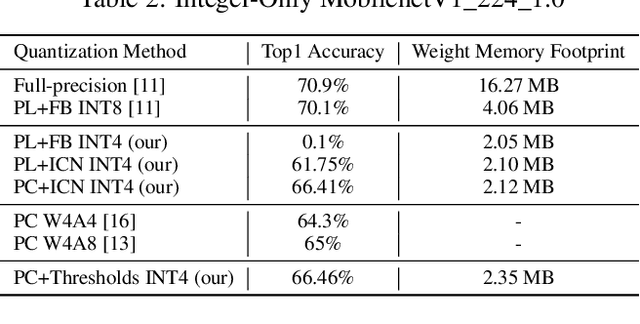
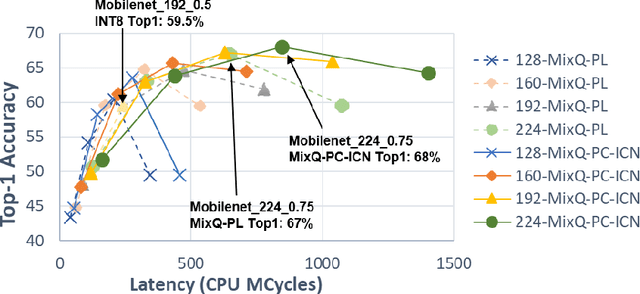
This paper presents a novel end-to-end methodology for enabling the deployment of low-error deep networks on microcontrollers. To fit the memory and computational limitations of resource-constrained edge-devices, we exploit mixed low-bitwidth compression, featuring 8, 4 or 2-bit uniform quantization, and we model the inference graph with integer-only operations. Our approach aims at determining the minimum bit precision of every activation and weight tensor given the memory constraints of a device. This is achieved through a rule-based iterative procedure, which cuts the number of bits of the most memory-demanding layers, aiming at meeting the memory constraints. After a quantization-aware retraining step, the fake-quantized graph is converted into an inference integer-only model by inserting the Integer Channel-Normalization (ICN) layers, which introduce a negligible loss as demonstrated on INT4 MobilenetV1 models. We report the latency-accuracy evaluation of mixed-precision MobilenetV1 family networks on a STM32H7 microcontroller. Our experimental results demonstrate an end-to-end deployment of an integer-only Mobilenet network with Top1 accuracy of 68% on a device with only 2MB of FLASH memory and 512kB of RAM, improving by 8% the Top1 accuracy with respect to previously published 8 bit implementations for microcontrollers.