 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Awareness Induction in Autoregressive Seq2Seq Models
Paper and Code
Aug 25, 2024

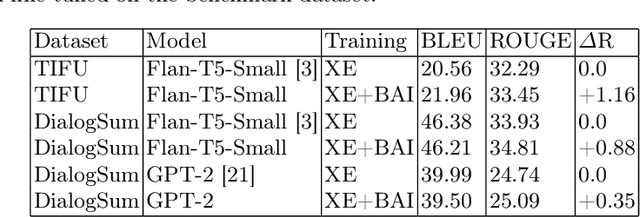

Autoregressive Sequence-To-Sequence models are the foundation of many Deep Learning achievements in major research fields such as Vision and Natural Language Processing. Despite that, they still present significant limitations. For instance, when errors occur in the early steps of the prediction, the whole output is severely affected. Such reliance on previously predicted tokens and the inherent computational unfriendliness of sequential algorithms, motivated researchers to explore different architectures and methods in the search for bidirectional approaches. In this work, we introduce the Bidirectional Awareness Induction (BAI), a training method that leverages a subset of elements in the network, the Pivots, to perform bidirectional learning without breaking the autoregressive constraints. To showcase its flexibility, we apply the method to three architectures, the Transformer, ExpansionNet v2 and GPT, then perform experiments over three tasks. Experimental results showcase BAI's effectiveness on all selected tasks and architectures. In particular, we observed an increase of up to 2.4 CIDEr in Image-Captioning, 4.96 BLEU in Neural Machine Translation, and 1.16 ROUGE in Text Summarization compared to the respective baselines. Notably, BAI not only has a positive impact on models trained from scratch but on pre-trained models as well. Such an aspect, combined with the absence of architectural requirements synergizes well with the current trend of LLMs.