 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLaGS: Relational Language Gaussian Splatting
Mar 18, 2026Achieving unified 3D perception and reasoning across tasks such as segmentation, retrieval, and relation understanding remains challenging, as existing methods are either object-centric or rely on costly training for inter-object reasoning. We present a novel framework that constructs a hierarchical language-distilled Gaussian scene and its 3D semantic scene graph without scene-specific training. A Gaussian pruning mechanism refines scene geometry, while a robust multi-view language alignment strategy aggregates noisy 2D features into accurate 3D object embeddings. On top of this hierarchy, we build an open-vocabulary 3D scene graph with Vision Language derived annotations and Graph Neural Network-based relational reasoning. Our approach enables efficient and scalable open-vocabulary 3D reasoning by jointly modeling hierarchical semantics and inter/intra-object relationships, validated across tasks including open-vocabulary segmentation, scene graph generation, and relation-guided retrieval. Project page: https://dfki-av.github.io/ReLaGS/
Diffusion Is Your Friend in Show, Suggest and Tell
Dec 10, 2025



Diffusion Denoising models demonstrated impressive results across generative Computer Vision tasks, but they still fail to outperform standard autoregressive solutions in the discrete domain, and only match them at best. In this work, we propose a different paradigm by adopting diffusion models to provide suggestions to the autoregressive generation rather than replacing them. By doing so, we combine the bidirectional and refining capabilities of the former with the strong linguistic structure provided by the latter. To showcase its effectiveness, we present Show, Suggest and Tell (SST), which achieves State-of-the-Art results on COCO, among models in a similar setting. In particular, SST achieves 125.1 CIDEr-D on the COCO dataset without Reinforcement Learning, outperforming both autoregressive and diffusion model State-of-the-Art results by 1.5 and 2.5 points. On top of the strong results, we performed extensive experiments to validate the proposal and analyze the impact of the suggestion module. Results demonstrate a positive correlation between suggestion and caption quality, overall indicating a currently underexplored but promising research direction. Code will be available at: https://github.com/jchenghu/show\_suggest\_tell.
Bidirectional Awareness Induction in Autoregressive Seq2Seq Models
Aug 25, 2024

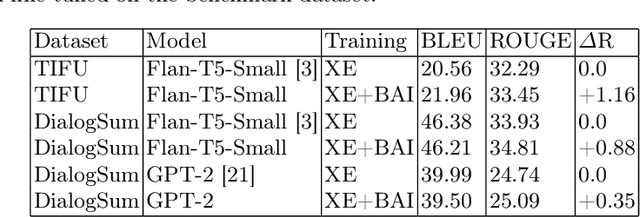

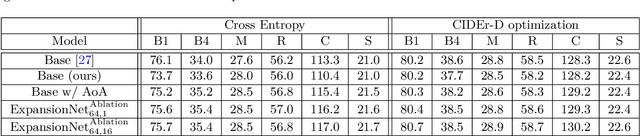
Autoregressive Sequence-To-Sequence models are the foundation of many Deep Learning achievements in major research fields such as Vision and Natural Language Processing. Despite that, they still present significant limitations. For instance, when errors occur in the early steps of the prediction, the whole output is severely affected. Such reliance on previously predicted tokens and the inherent computational unfriendliness of sequential algorithms, motivated researchers to explore different architectures and methods in the search for bidirectional approaches. In this work, we introduce the Bidirectional Awareness Induction (BAI), a training method that leverages a subset of elements in the network, the Pivots, to perform bidirectional learning without breaking the autoregressive constraints. To showcase its flexibility, we apply the method to three architectures, the Transformer, ExpansionNet v2 and GPT, then perform experiments over three tasks. Experimental results showcase BAI's effectiveness on all selected tasks and architectures. In particular, we observed an increase of up to 2.4 CIDEr in Image-Captioning, 4.96 BLEU in Neural Machine Translation, and 1.16 ROUGE in Text Summarization compared to the respective baselines. Notably, BAI not only has a positive impact on models trained from scratch but on pre-trained models as well. Such an aspect, combined with the absence of architectural requirements synergizes well with the current trend of LLMs.
Shifted Window Fourier Transform And Retention For Image Captioning
Aug 25, 2024Image Captioning is an important Language and Vision task that finds application in a variety of contexts, ranging from healthcare to autonomous vehicles. As many real-world applications rely on devices with limited resources, much effort in the field was put into the development of lighter and faster models. However, much of the current optimizations focus on the Transformer architecture in contrast to the existence of more efficient methods. In this work, we introduce SwiFTeR, an architecture almost entirely based on Fourier Transform and Retention, to tackle the main efficiency bottlenecks of current light image captioning models, being the visual backbone's onerosity, and the decoder's quadratic cost. SwiFTeR is made of only 20M parameters, and requires 3.1 GFLOPs for a single forward pass. Additionally, it showcases superior scalability to the caption length and its small memory requirements enable more images to be processed in parallel, compared to the traditional transformer-based architectures. For instance, it can generate 400 captions in one second. Although, for the time being, the caption quality is lower (110.2 CIDEr-D), most of the decrease is not attributed to the architecture but rather an incomplete training practice which currently leaves much room for improvements. Overall, SwiFTeR points toward a promising direction to new efficient architectural design. The implementation code will be released in the future.
Heterogeneous Encoders Scaling In The Transformer For Neural Machine Translation
Dec 26, 2023



Although the Transformer is currently the best-performing architecture in the homogeneous configuration (self-attention only) in Neural Machine Translation, many State-of-the-Art models in Natural Language Processing are made of a combination of different Deep Learning approaches. However, these models often focus on combining a couple of techniques only and it is unclear why some methods are chosen over others. In this work, we investigate the effectiveness of integrating an increasing number of heterogeneous methods. Based on a simple combination strategy and performance-driven synergy criteria, we designed the Multi-Encoder Transformer, which consists of up to five diverse encoders. Results showcased that our approach can improve the quality of the translation across a variety of languages and dataset sizes and it is particularly effective in low-resource languages where we observed a maximum increase of 7.16 BLEU compared to the single-encoder model.
A request for clarity over the End of Sequence token in the Self-Critical Sequence Training
May 20, 2023The Image Captioning research field is currently compromised by the lack of transparency and awareness over the End-of-Sequence token (<Eos>) in the Self-Critical Sequence Training. If the <Eos> token is omitted, a model can boost its performance up to +4.1 CIDEr-D using trivial sentence fragments. While this phenomenon poses an obstacle to a fair evaluation and comparison of established works, people involved in new projects are given the arduous choice between lower scores and unsatisfactory descriptions due to the competitive nature of the research. This work proposes to solve the problem by spreading awareness of the issue itself. In particular, we invite future works to share a simple and informative signature with the help of a library called SacreEOS. Code available at \emph{\href{https://github.com/jchenghu/sacreeos}{https://github.com/jchenghu/sacreeos}}
ExpansionNet v2: Block Static Expansion in fast end to end training for Image Captioning
Aug 19, 2022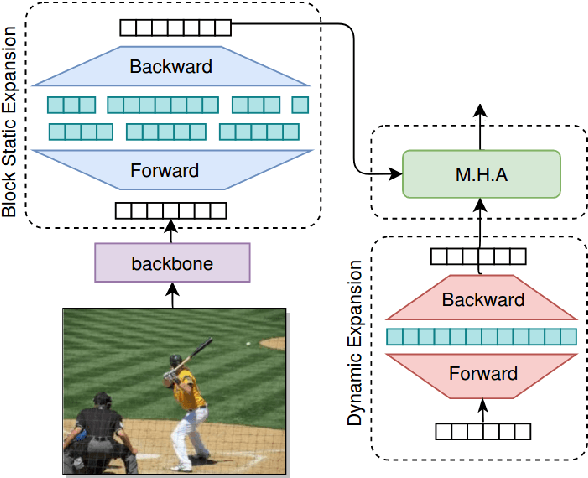


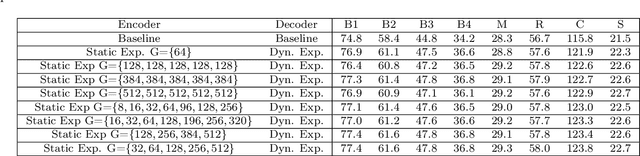
Expansion methods explore the possibility of performance bottlenecks in the input length in Deep Learning methods. In this work, we introduce the Block Static Expansion which distributes and processes the input over a heterogeneous and arbitrarily big collection of sequences characterized by a different length compared to the input one. Adopting this method we introduce a model called ExpansionNet v2, which is trained using our novel training strategy, designed to be not only effective but also 6 times faster compared to the standard approach of recent works in Image Captioning. The model achieves the state of art performance over the MS-COCO 2014 captioning challenge with a score of 143.7 CIDEr-D in the offline test split, 140.8 CIDEr-D in the online evaluation server and 72.9 All-CIDEr on the nocaps validation set. Source code available at: https://github.com/jchenghu/ExpansionNet_v2
ExpansionNet: exploring the sequence length bottleneck in the Transformer for Image Captioning
Jul 07, 2022
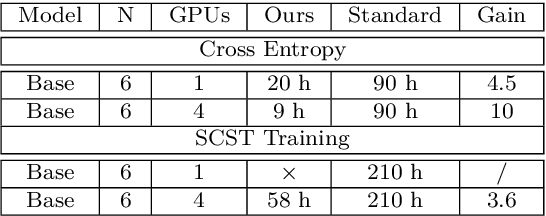
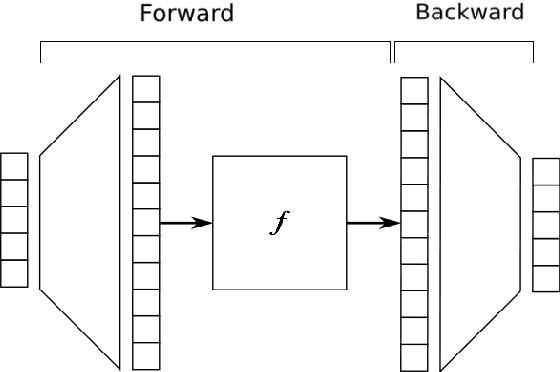
Most recent state of art architectures rely on combinations and variations of three approaches: convolutional, recurrent and self-attentive methods. Our work attempts in laying the basis for a new research direction for sequence modeling based upon the idea of modifying the sequence length. In order to do that, we propose a new method called ``Expansion Mechanism'' which transforms either dynamically or statically the input sequence into a new one featuring a different sequence length. Furthermore, we introduce a novel architecture that exploits such method and achieves competitive performances on the MS-COCO 2014 data set, yielding 134.6 and 131.4 CIDEr-D on the Karpathy test split in the ensemble and single model configuration respectively and 130 CIDEr-D in the official online testing server, despite being neither recurrent nor fully attentive. At the same time we address the efficiency aspect in our design and introduce a convenient training strategy suitable for most computational resources in contrast to the standard one. Source code is available at https://github.com/jchenghu/ExpansionNet