 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEURAghe: Exploiting CPU-FPGA Synergies for Efficient and Flexible CNN Inference Acceleration on Zynq SoCs
Paper and Code
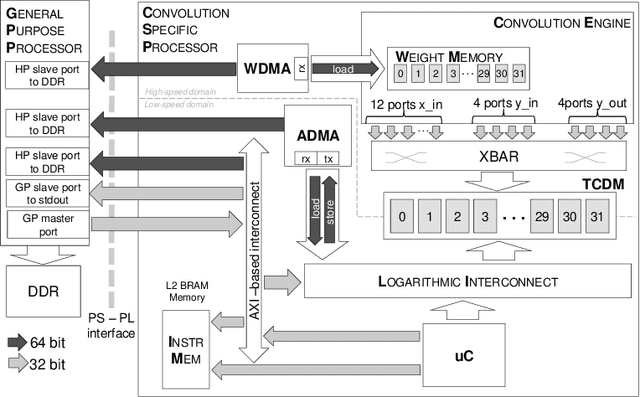
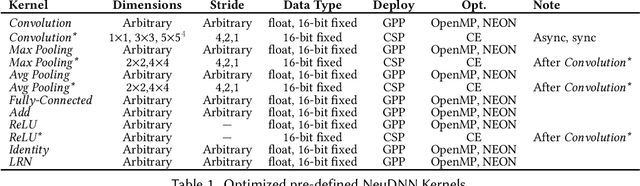
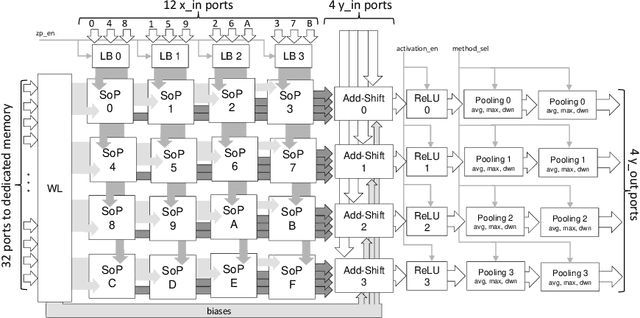

Deep convolutional neural networks (CNNs) obtain outstanding results in tasks that require human-level understanding of data, like image or speech recognition. However, their computational load is significant, motivating the development of CNN-specialized accelerators. This work presents NEURAghe, a flexible and efficient hardware/software solution for the acceleration of CNNs on Zynq SoCs. NEURAghe leverages the synergistic usage of Zynq ARM cores and of a powerful and flexible Convolution-Specific Processor deployed on the reconfigurable logic. The Convolution-Specific Processor embeds both a convolution engine and a programmable soft core, releasing the ARM processors from most of the supervision duties and allowing the accelerator to be controlled by software at an ultra-fine granularity. This methodology opens the way for cooperative heterogeneous computing: while the accelerator takes care of the bulk of the CNN workload, the ARM cores can seamlessly execute hard-to-accelerate parts of the computational graph, taking advantage of the NEON vector engines to further speed up computation. Through the companion NeuDNN SW stack, NEURAghe supports end-to-end CNN-based classification with a peak performance of 169 Gops/s, and an energy efficiency of 17 Gops/W. Thanks to our heterogeneous computing model, our platform improves upon the state-of-the-art, achieving a frame rate of 5.5 fps on the end-to-end execution of VGG-16, and 6.6 fps on ResNet-18.