 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn adaptive cognitive sensor node for ECG monitoring in the Internet of Medical Things
Jun 11, 2021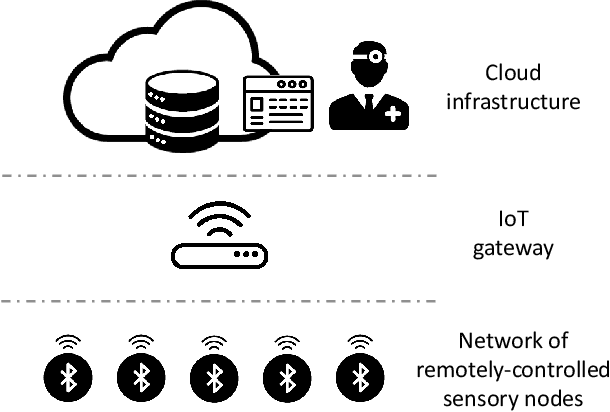
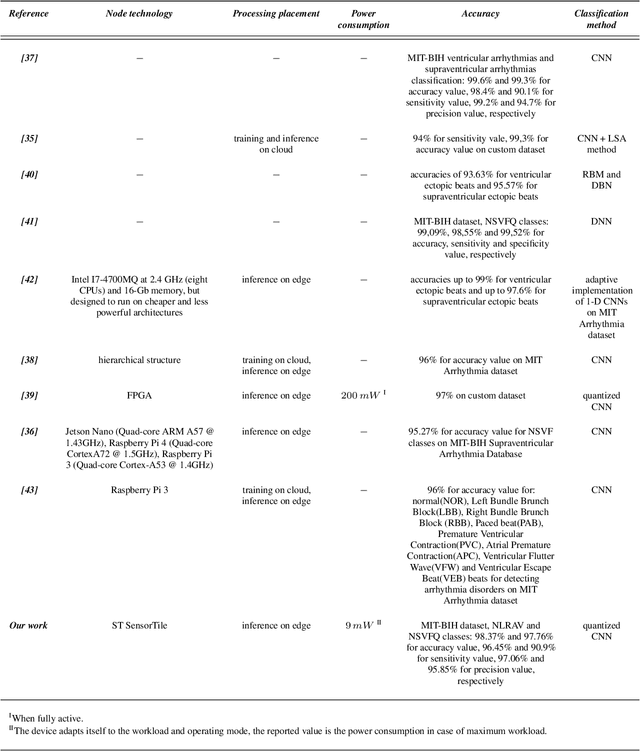
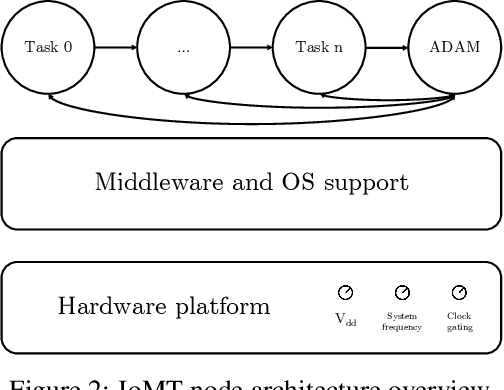
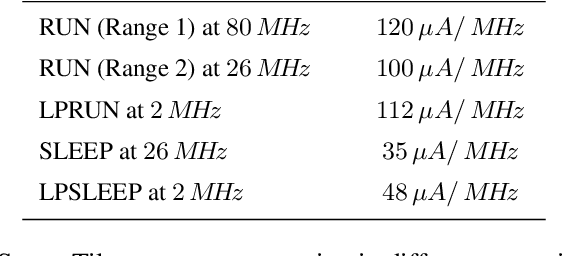
The Internet of Medical Things (IoMT) paradigm is becoming mainstream in multiple clinical trials and healthcare procedures. It relies on novel very accurate and compact sensing devices and communication infrastructures, opening previously unmatched possibilities of implementing data collection and continuous patient monitoring. Nevertheless, to fully exploit the potential of this technology, some steps forwards are needed. First, the edge-computing paradigm must be added to the picture. A certain level of near-sensor processing has to be enabled, to improve the scalability, portability, reliability, responsiveness of the IoMT nodes. Second, novel, increasingly accurate, data analysis algorithms, such as those based on artificial intelligence and Deep Learning, must be exploited. To reach these objectives, designers, programmers of IoMT nodes, have to face challenging optimization tasks, in order to execute fairly complex computing tasks on low-power wearable and portable processing systems, with tight power and battery lifetime budgets. In this work, we explore the implementation of cognitive data analysis algorithm on resource-constrained computing platforms. To minimize power consumption, we add an adaptivity layer that dynamically manages the hardware and software configuration of the device to adapt it at runtime to the required operating mode. We have assessed our approach on a use-case using a convolutional neural network to classify electrocardiogram (ECG) traces on a low-power microcontroller. Our experimental results show that adapting the node setup to the workload at runtime can save up to 50% power consumption and a quantized neural network reaches an accuracy value higher than 98% for arrhythmia disorders detection on MIT-BIH Arrhythmia dataset.
NEURAghe: Exploiting CPU-FPGA Synergies for Efficient and Flexible CNN Inference Acceleration on Zynq SoCs
Dec 04, 2017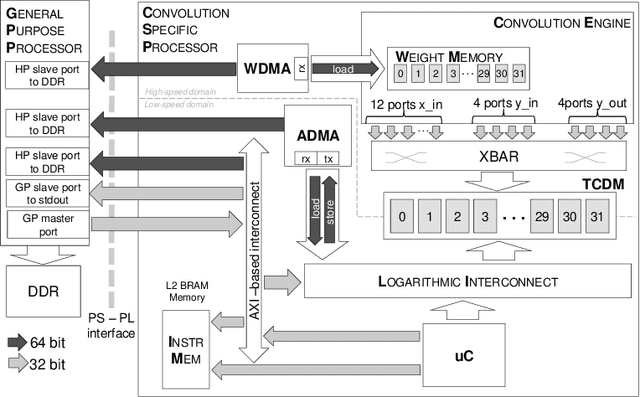
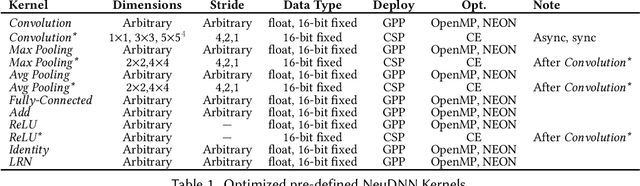
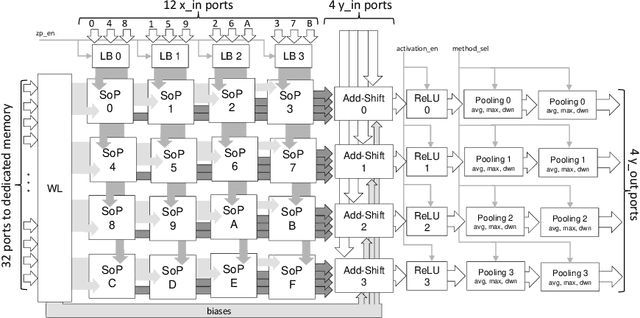

Deep convolutional neural networks (CNNs) obtain outstanding results in tasks that require human-level understanding of data, like image or speech recognition. However, their computational load is significant, motivating the development of CNN-specialized accelerators. This work presents NEURAghe, a flexible and efficient hardware/software solution for the acceleration of CNNs on Zynq SoCs. NEURAghe leverages the synergistic usage of Zynq ARM cores and of a powerful and flexible Convolution-Specific Processor deployed on the reconfigurable logic. The Convolution-Specific Processor embeds both a convolution engine and a programmable soft core, releasing the ARM processors from most of the supervision duties and allowing the accelerator to be controlled by software at an ultra-fine granularity. This methodology opens the way for cooperative heterogeneous computing: while the accelerator takes care of the bulk of the CNN workload, the ARM cores can seamlessly execute hard-to-accelerate parts of the computational graph, taking advantage of the NEON vector engines to further speed up computation. Through the companion NeuDNN SW stack, NEURAghe supports end-to-end CNN-based classification with a peak performance of 169 Gops/s, and an energy efficiency of 17 Gops/W. Thanks to our heterogeneous computing model, our platform improves upon the state-of-the-art, achieving a frame rate of 5.5 fps on the end-to-end execution of VGG-16, and 6.6 fps on ResNet-18.