 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Automated Mixed-Low-Precision Quantization for tiny edge microcontrollers
Paper and Code
Aug 12, 2020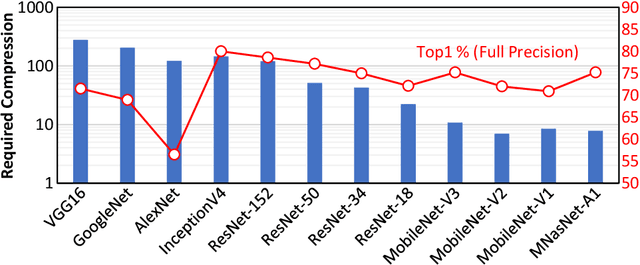
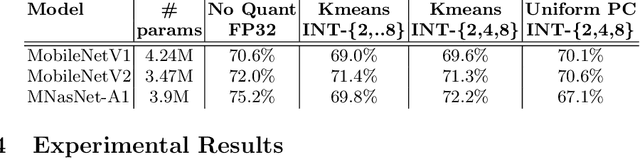
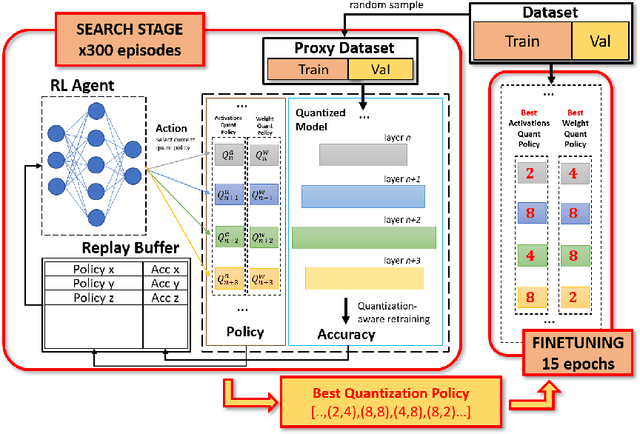
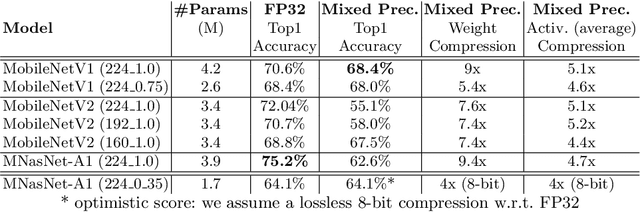
The severe on-chip memory limitations are currently preventing the deployment of the most accurate Deep Neural Network (DNN) models on tiny MicroController Units (MCUs), even if leveraging an effective 8-bit quantization scheme. To tackle this issue, in this paper we present an automated mixed-precision quantization flow based on the HAQ framework but tailored for the memory and computational characteristics of MCU devices. Specifically, a Reinforcement Learning agent searches for the best uniform quantization levels, among 2, 4, 8 bits, of individual weight and activation tensors, under the tight constraints on RAM and FLASH embedded memory sizes. We conduct an experimental analysis on MobileNetV1, MobileNetV2 and MNasNet models for Imagenet classification. Concerning the quantization policy search, the RL agent selects quantization policies that maximize the memory utilization. Given an MCU-class memory bound of 2MB for weight-only quantization, the compressed models produced by the mixed-precision engine result as accurate as the state-of-the-art solutions quantized with a non-uniform function, which is not tailored for CPUs featuring integer-only arithmetic. This denotes the viability of uniform quantization, required for MCU deployments, for deep weights compression. When also limiting the activation memory budget to 512kB, the best MobileNetV1 model scores up to 68.4% on Imagenet thanks to the found quantization policy, resulting to be 4% more accurate than the other 8-bit networks fitting the same memory constraints.