 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Design Space Exploration for optimised Deployment of DNN on Arm Cortex-A CPUs
Jun 09, 2020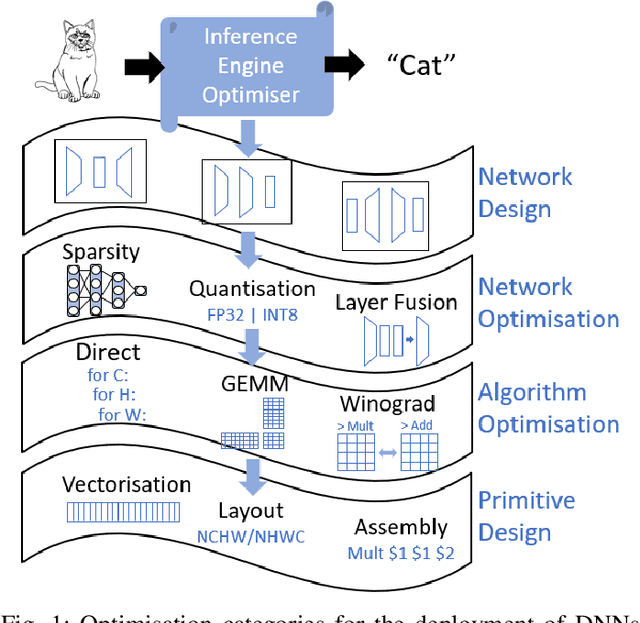
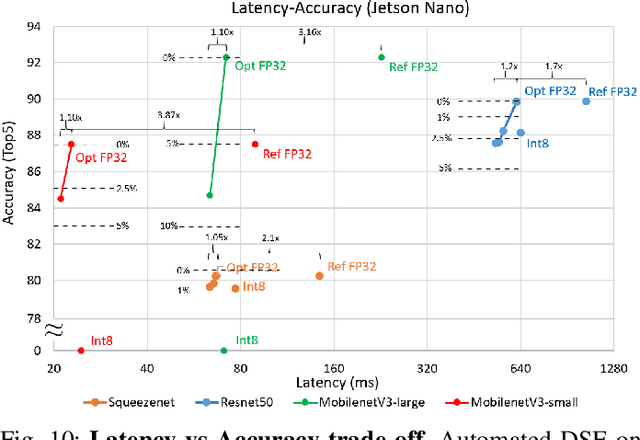
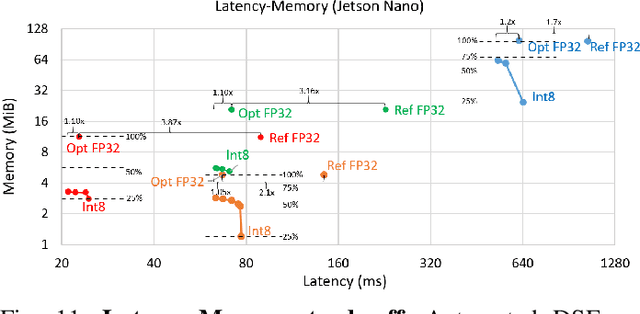
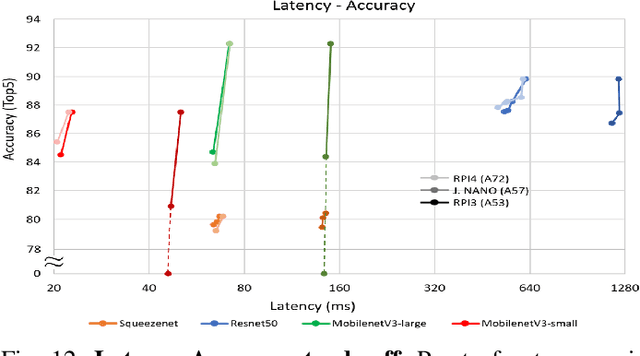
The spread of deep learning on embedded devices has prompted the development of numerous methods to optimise the deployment of deep neural networks (DNN). Works have mainly focused on: i) efficient DNN architectures, ii) network optimisation techniques such as pruning and quantisation, iii) optimised algorithms to speed up the execution of the most computational intensive layers and, iv) dedicated hardware to accelerate the data flow and computation. However, there is a lack of research on the combination of these methods as the space of approaches becomes too large to test and obtain a globally optimised solution, which leads to suboptimal deployment in terms of latency, accuracy, and memory. In this work, we first detail and analyse the methods to improve the deployment of DNNs across the different levels of software optimisation. Building on this knowledge, we present an automated exploration framework to ease the deployment of DNNs for industrial applications by automatically exploring the design space and learning an optimised solution that speeds up the performance and reduces the memory on embedded CPU platforms. The framework relies on a Reinforcement Learning -based search that, combined with a deep learning inference framework, enables the deployment of DNN implementations to obtain empirical measurements on embedded AI applications. Thus, we present a set of results for state-of-the-art DNNs on a range of Arm Cortex-A CPU platforms achieving up to 4x improvement in performance and over 2x reduction in memory with negligible loss in accuracy with respect to the BLAS floating-point implementation.
Searching for Winograd-aware Quantized Networks
Feb 25, 2020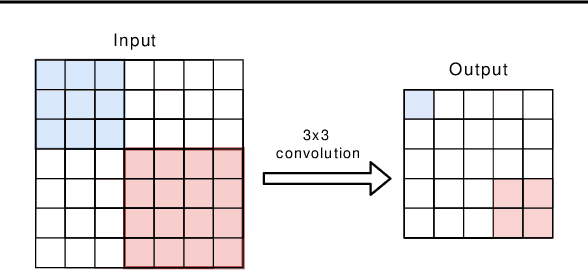
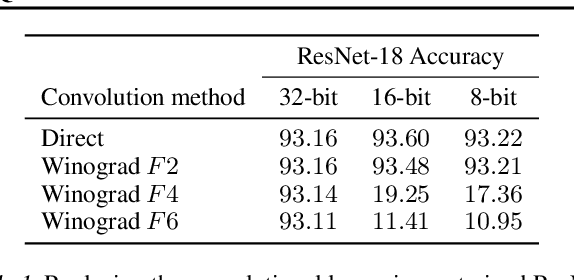
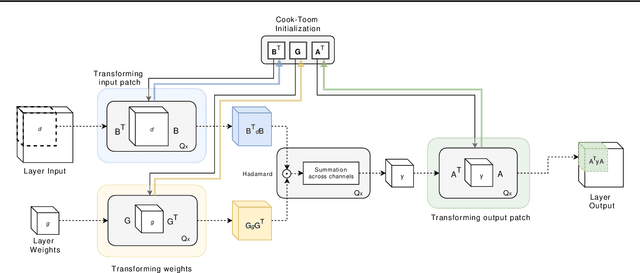
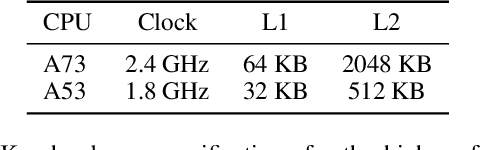
Lightweight architectural designs of Convolutional Neural Networks (CNNs) together with quantization have paved the way for the deployment of demanding computer vision applications on mobile devices. Parallel to this, alternative formulations to the convolution operation such as FFT, Strassen and Winograd, have been adapted for use in CNNs offering further speedups. Winograd convolutions are the fastest known algorithm for spatially small convolutions, but exploiting their full potential comes with the burden of numerical error, rendering them unusable in quantized contexts. In this work we propose a Winograd-aware formulation of convolution layers which exposes the numerical inaccuracies introduced by the Winograd transformations to the learning of the model parameters, enabling the design of competitive quantized models without impacting model size. We also address the source of the numerical error and propose a relaxation on the form of the transformation matrices, resulting in up to 10% higher classification accuracy on CIFAR-10. Finally, we propose wiNAS, a neural architecture search (NAS) framework that jointly optimizes a given macro-architecture for accuracy and latency leveraging Winograd-aware layers. A Winograd-aware ResNet-18 optimized with wiNAS for CIFAR-10 results in 2.66x speedup compared to im2row, one of the most widely used optimized convolution implementations, with no loss in accuracy.
Efficient Winograd or Cook-Toom Convolution Kernel Implementation on Widely Used Mobile CPUs
Mar 04, 2019

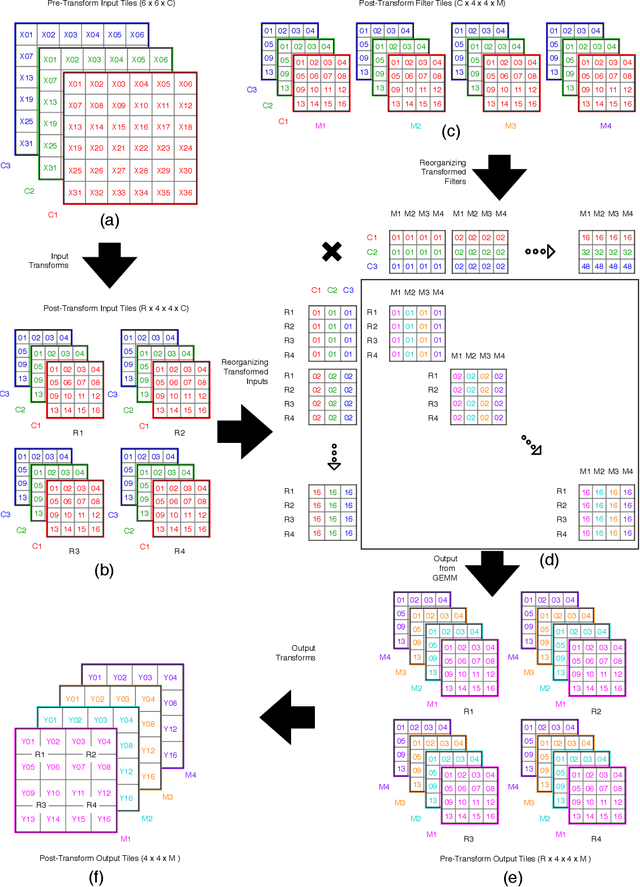
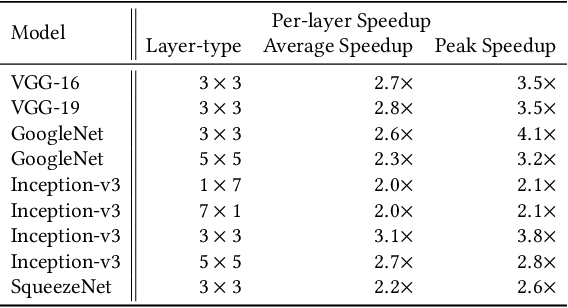
The Winograd or Cook-Toom class of algorithms help to reduce the overall compute complexity of many modern deep convolutional neural networks (CNNs). Although there has been a lot of research done on model and algorithmic optimization of CNN, little attention has been paid to the efficient implementation of these algorithms on embedded CPUs, which usually have very limited memory and low power budget. This paper aims to fill this gap and focuses on the efficient implementation of Winograd or Cook-Toom based convolution on modern Arm Cortex-A CPUs, widely used in mobile devices today. Specifically, we demonstrate a reduction in inference latency by using a set of optimization strategies that improve the utilization of computational resources, and by effectively leveraging the ARMv8-A NEON SIMD instruction set. We evaluated our proposed region-wise multi-channel implementations on Arm Cortex-A73 platform using several representative CNNs. The results show significant performance improvements in full network, up to 60%, over existing im2row/im2col based optimization techniques