 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoping: A technique for efficient compression of LSTM models using sparse structured additive matrices
Feb 14, 2021
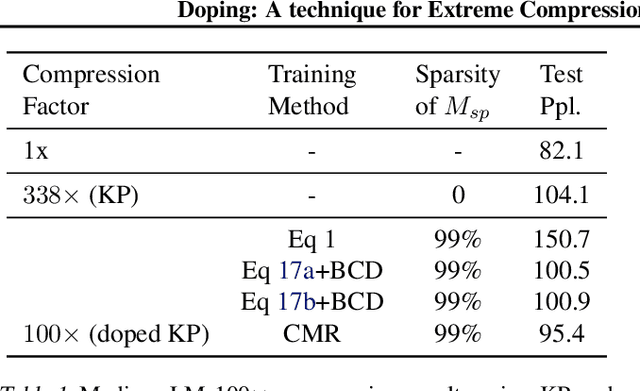
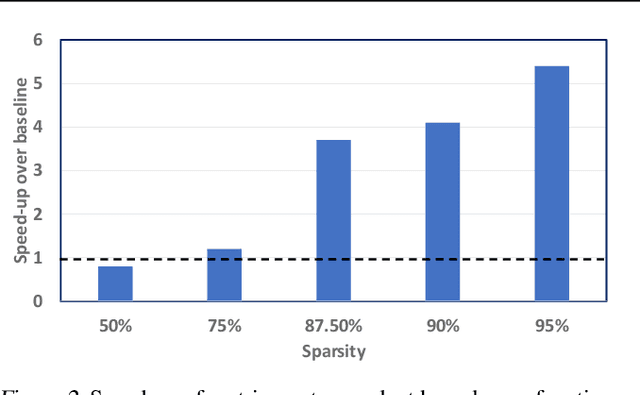

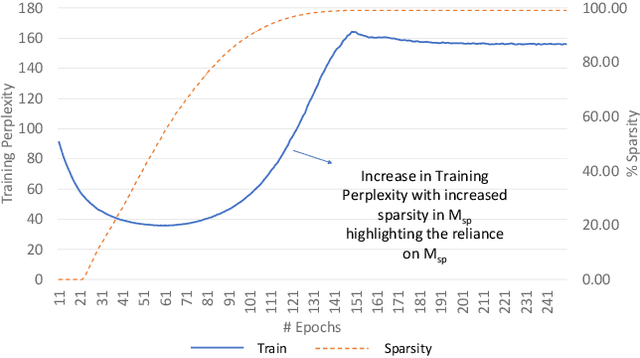
Structured matrices, such as those derived from Kronecker products (KP), are effective at compressing neural networks, but can lead to unacceptable accuracy loss when applied to large models. In this paper, we propose the notion of doping -- addition of an extremely sparse matrix to a structured matrix. Doping facilitates additional degrees of freedom for a small number of parameters, allowing them to independently diverge from the fixed structure. To train LSTMs with doped structured matrices, we introduce the additional parameter matrix while slowly annealing its sparsity level. However, we find that performance degrades as we slowly sparsify the doping matrix, due to co-matrix adaptation (CMA) between the structured and the sparse matrices. We address this over dependence on the sparse matrix using a co-matrix dropout regularization (CMR) scheme. We provide empirical evidence to show that doping, CMA and CMR are concepts generally applicable to multiple structured matrices (Kronecker Product, LMF, Hybrid Matrix Decomposition). Additionally, results with doped kronecker product matrices demonstrate state-of-the-art accuracy at large compression factors (10 - 25x) across 4 natural language processing applications with minor loss in accuracy. Doped KP compression technique outperforms previous state-of-the art compression results by achieving 1.3 - 2.4x higher compression factor at a similar accuracy, while also beating strong alternatives like pruning and low-rank methods by a large margin (8% or more). Additionally, we show that doped KP can be deployed on commodity hardware using the current software stack and achieve 2.5 - 5.5x inference run-time speed-up over baseline.
Rank and run-time aware compression of NLP Applications
Oct 06, 2020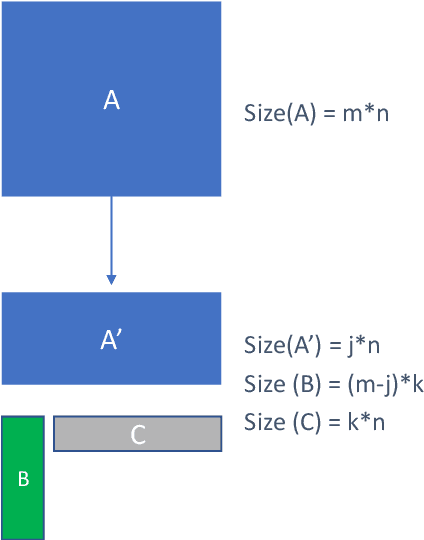
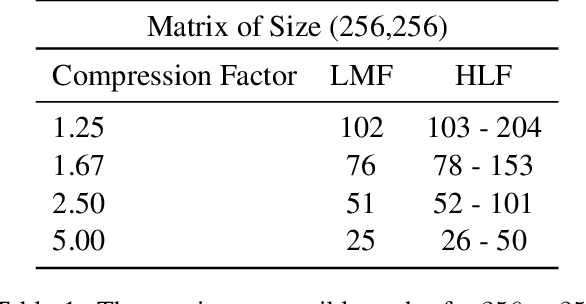
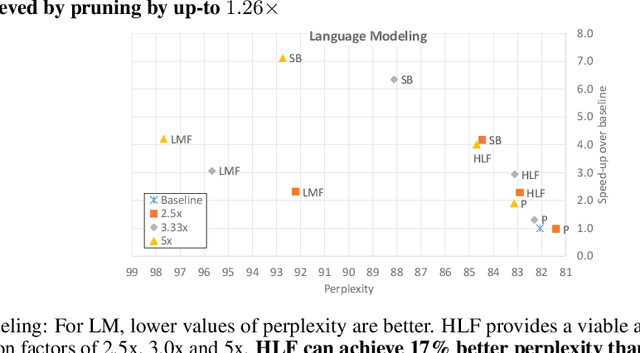
Sequence model based NLP applications can be large. Yet, many applications that benefit from them run on small devices with very limited compute and storage capabilities, while still having run-time constraints. As a result, there is a need for a compression technique that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper proposes a new compression technique called Hybrid Matrix Factorization that achieves this dual objective. HMF improves low-rank matrix factorization (LMF) techniques by doubling the rank of the matrix using an intelligent hybrid-structure leading to better accuracy than LMF. Further, by preserving dense matrices, it leads to faster inference run-time than pruning or structure matrix based compression technique. We evaluate the impact of this technique on 5 NLP benchmarks across multiple tasks (Translation, Intent Detection, Language Modeling) and show that for similar accuracy values and compression factors, HMF can achieve more than 2.32x faster inference run-time than pruning and 16.77% better accuracy than LMF.
High Throughput Matrix-Matrix Multiplication between Asymmetric Bit-Width Operands
Aug 03, 2020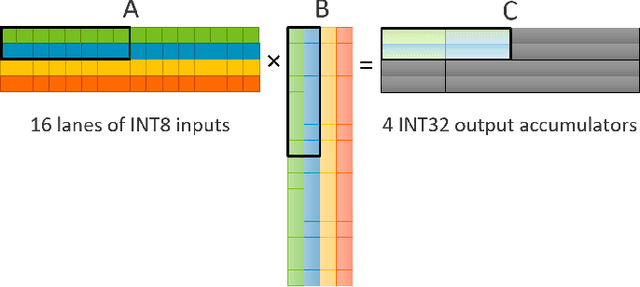
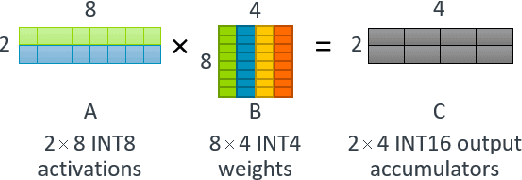
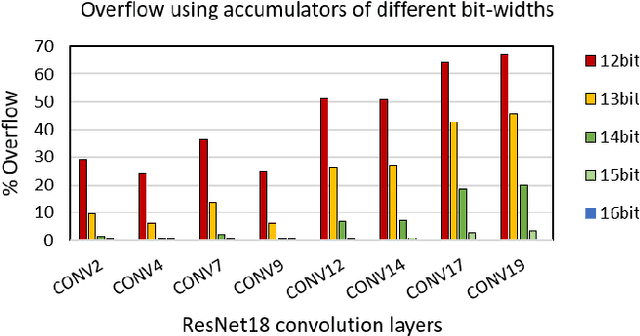
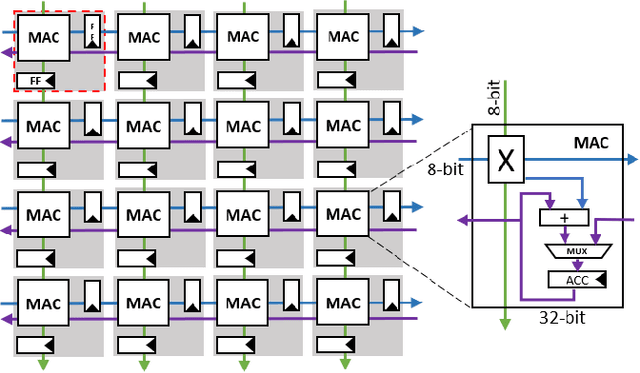
Matrix multiplications between asymmetric bit-width operands, especially between 8- and 4-bit operands are likely to become a fundamental kernel of many important workloads including neural networks and machine learning. While existing SIMD matrix multiplication instructions for symmetric bit-width operands can support operands of mixed precision by zero- or sign-extending the narrow operand to match the size of the other operands, they cannot exploit the benefit of narrow bit-width of one of the operands. We propose a new SIMD matrix multiplication instruction that uses mixed precision on its inputs (8- and 4-bit operands) and accumulates product values into narrower 16-bit output accumulators, in turn allowing the SIMD operation at 128-bit vector width to process a greater number of data elements per instruction to improve processing throughput and memory bandwidth utilization without increasing the register read- and write-port bandwidth in CPUs. The proposed asymmetric-operand-size SIMD instruction offers 2x improvement in throughput of matrix multiplication in comparison to throughput obtained using existing symmetric-operand-size instructions while causing negligible (0.05%) overflow from 16-bit accumulators for representative machine learning workloads. The asymmetric-operand-size instruction not only can improve matrix multiplication throughput in CPUs, but also can be effective to support multiply-and-accumulate (MAC) operation between 8- and 4-bit operands in state-of-the-art DNN hardware accelerators (e.g., systolic array microarchitecture in Google TPU, etc.) and offer similar improvement in matrix multiply performance seamlessly without violating the various implementation constraints. We demonstrate how a systolic array architecture designed for symmetric-operand-size instructions could be modified to support an asymmetric-operand-sized instruction.
Compressing Language Models using Doped Kronecker Products
Jan 31, 2020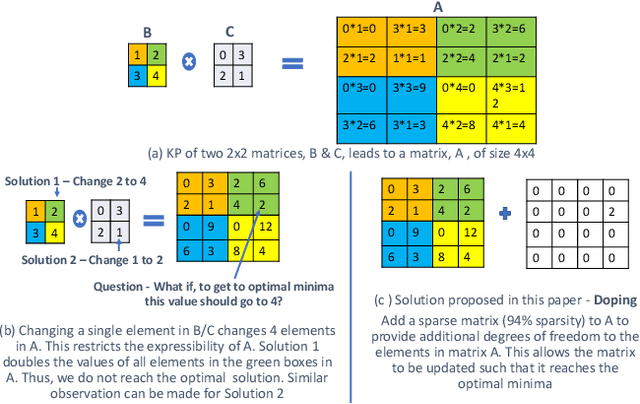
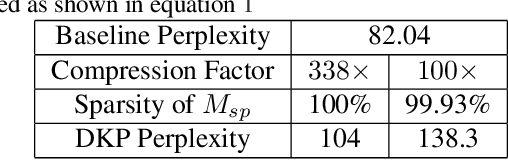
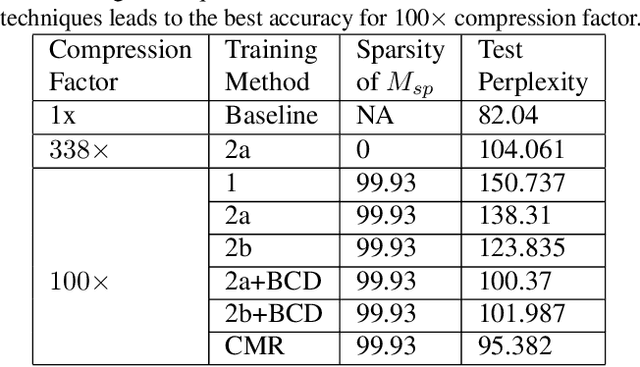
Kronecker Products (KP) have been used to compress IoT RNN Applications by 15-38x compression factors, achieving better results than traditional compression methods. However when KP is applied to large Natural Language Processing tasks, it leads to significant accuracy loss (approx 26%). This paper proposes a way to recover accuracy otherwise lost when applying KP to large NLP tasks, by allowing additional degrees of freedom in the KP matrix. More formally, we propose doping, a process of adding an extremely sparse overlay matrix on top of the pre-defined KP structure. We call this compression method doped kronecker product compression. To train these models, we present a new solution to the phenomenon of co-matrix adaption (CMA), which uses a new regularization scheme called co matrix dropout regularization (CMR). We present experimental results that demonstrate compression of a large language model with LSTM layers of size 25 MB by 25x with 1.4% loss in perplexity score. At 25x compression, an equivalent pruned network leads to 7.9% loss in perplexity score, while HMD and LMF lead to 15% and 27% loss in perplexity score respectively.
* Link to Workshop - https://mlsys.org/Conferences/2020/Schedule?showEvent=1297
Ternary MobileNets via Per-Layer Hybrid Filter Banks
Nov 04, 2019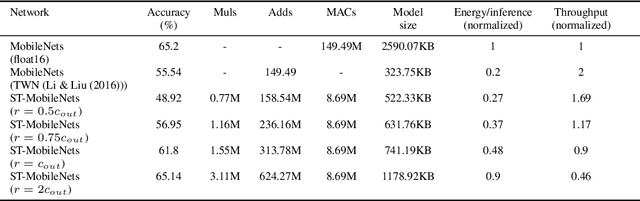
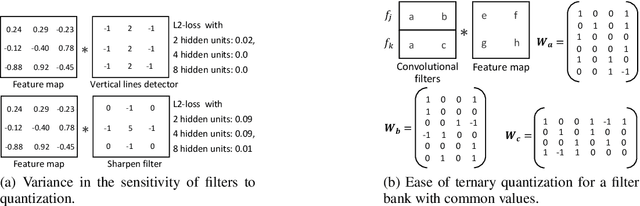
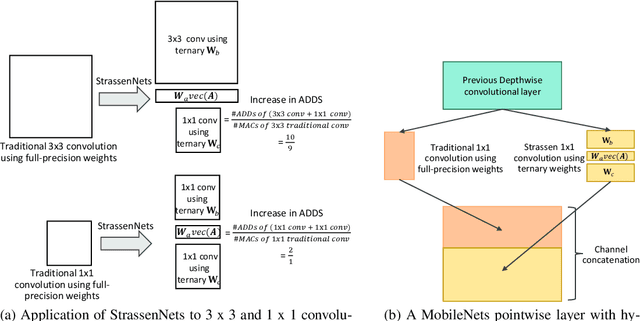
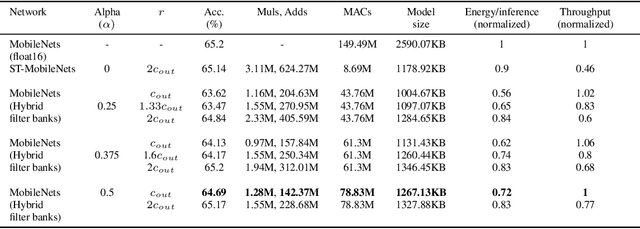
MobileNets family of computer vision neural networks have fueled tremendous progress in the design and organization of resource-efficient architectures in recent years. New applications with stringent real-time requirements on highly constrained devices require further compression of MobileNets-like already compute-efficient networks. Model quantization is a widely used technique to compress and accelerate neural network inference and prior works have quantized MobileNets to 4-6 bits albeit with a modest to significant drop in accuracy. While quantization to sub-byte values (i.e. precision less than or equal to 8 bits) has been valuable, even further quantization of MobileNets to binary or ternary values is necessary to realize significant energy savings and possibly runtime speedups on specialized hardware, such as ASICs and FPGAs. Under the key observation that convolutional filters at each layer of a deep neural network may respond differently to ternary quantization, we propose a novel quantization method that generates per-layer hybrid filter banks consisting of full-precision and ternary weight filters for MobileNets. The layer-wise hybrid filter banks essentially combine the strengths of full-precision and ternary weight filters to derive a compact, energy-efficient architecture for MobileNets. Using this proposed quantization method, we quantized a substantial portion of weight filters of MobileNets to ternary values resulting in 27.98% savings in energy, and a 51.07% reduction in the model size, while achieving comparable accuracy and no degradation in throughput on specialized hardware in comparison to the baseline full-precision MobileNets.
Pushing the limits of RNN Compression
Oct 09, 2019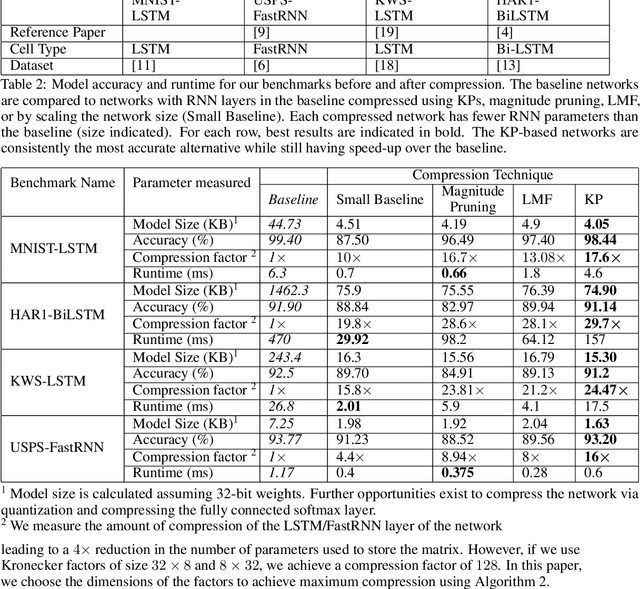
Recurrent Neural Networks (RNN) can be difficult to deploy on resource constrained devices due to their size. As a result, there is a need for compression techniques that can significantly compress RNNs without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker product (KP). KPs can compress RNN layers by 16-38x with minimal accuracy loss. We show that KP can beat the task accuracy achieved by other state-of-the-art compression techniques (pruning and low-rank matrix factorization) across 4 benchmarks spanning 3 different applications, while simultaneously improving inference run-time.
* 6 pages. arXiv admin note: substantial text overlap with arXiv:1906.02876
Compressing RNNs for IoT devices by 15-38x using Kronecker Products
Jun 18, 2019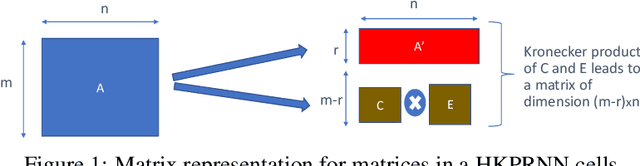
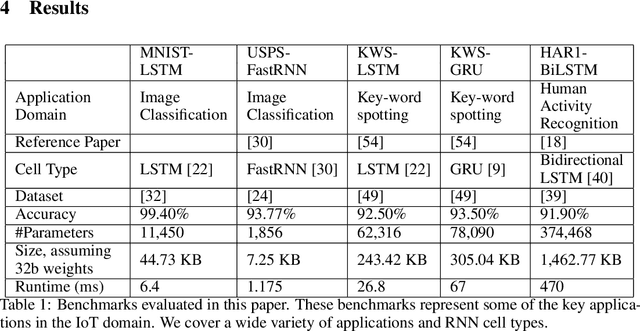
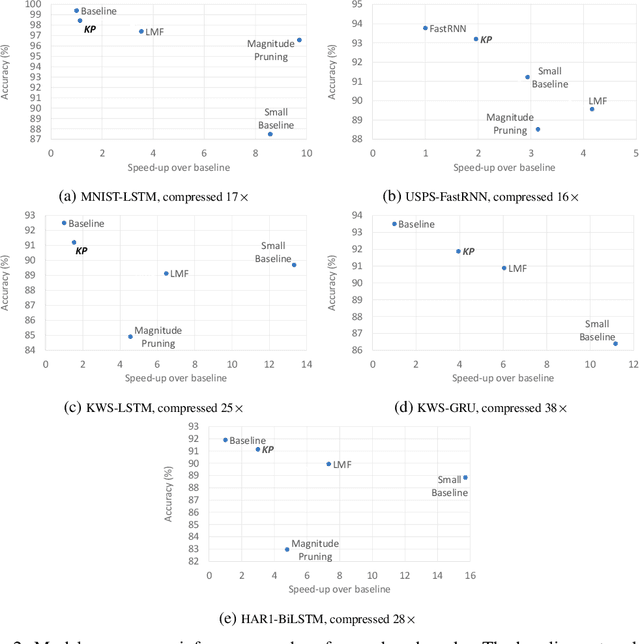
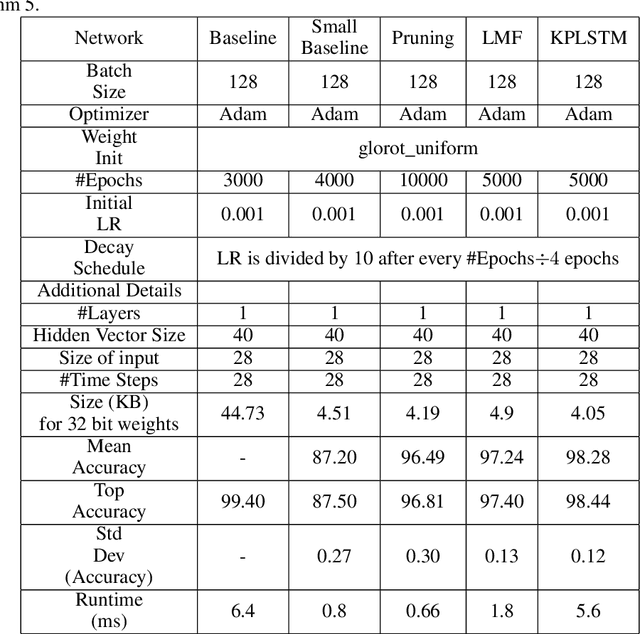
Recurrent Neural Networks (RNN) can be large and compute-intensive, making them hard to deploy on resource constrained devices. As a result, there is a need for compression technique that can significantly compress recurrent neural networks, without negatively impacting task accuracy. This paper introduces a method to compress RNNs for resource constrained environments using Kronecker products. We call the RNNs compressed using Kronecker products as Kronecker product Recurrent Neural Networks (KPRNNs). KPRNNs can compress the LSTM[22], GRU [9] and parameter optimized FastRNN [30] layers by 15 - 38x with minor loss in accuracy and can act as in-place replacement of most RNN cells in existing applications. By quantizing the Kronecker compressed networks to 8 bits, we further push the compression factor to 50x. We compare the accuracy and runtime of KPRNNs with other state-of-the-art compression techniques across 5 benchmarks spanning 3 different applications, showing its generality. Additionally, we show how to control the compression factors achieved by Kronecker products using a novel hybrid decomposition technique. We call the RNN cells compressed using Kronecker products with this control mechanism as hybrid Kronecker product RNNs (HKPRNN). Using HKPRNN, we compress RNN Cells in 2 benchmarks by 10x and 20x achieving better accuracy than other state-of-the-art compression techniques.
Run-Time Efficient RNN Compression for Inference on Edge Devices
Jun 18, 2019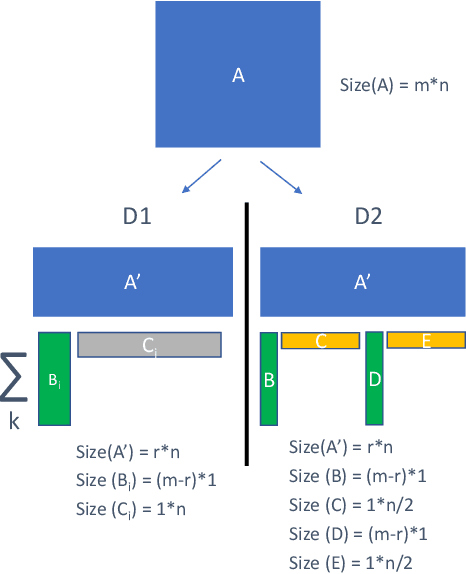
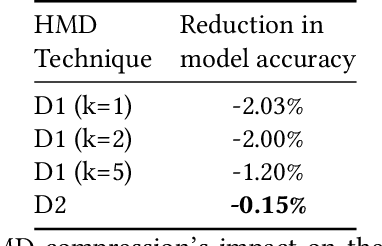
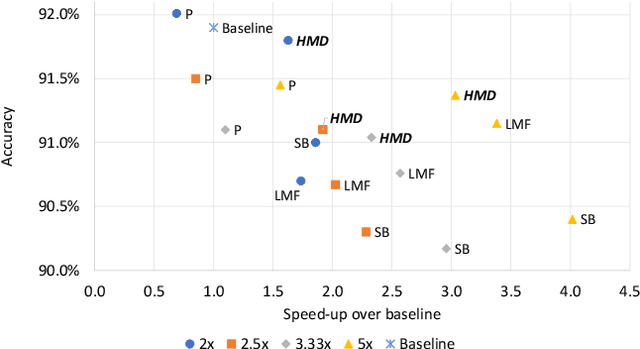
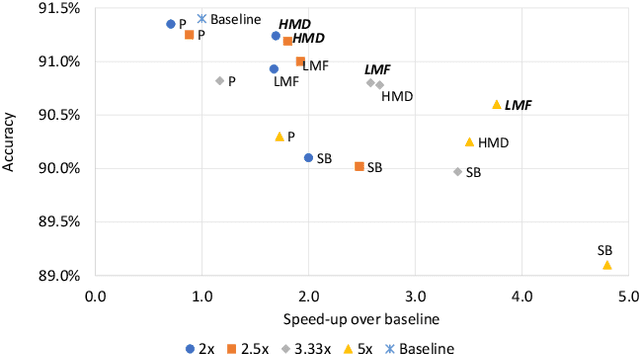
Recurrent neural networks can be large and compute-intensive, yet many applications that benefit from RNNs run on small devices with very limited compute and storage capabilities while still having run-time constraints. As a result, there is a need for compression techniques that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper explores a new compressed RNN cell implementation called Hybrid Matrix Decomposition (HMD) that achieves this dual objective. This scheme divides the weight matrix into two parts - an unconstrained upper half and a lower half composed of rank-1 blocks. This results in output features where the upper sub-vector has "richer" features while the lower-sub vector has "constrained" features". HMD can compress RNNs by a factor of 2-4x while having a faster run-time than pruning and retaining more model accuracy than matrix factorization. We evaluate this technique on 3 benchmarks.
Efficient Winograd or Cook-Toom Convolution Kernel Implementation on Widely Used Mobile CPUs
Mar 04, 2019

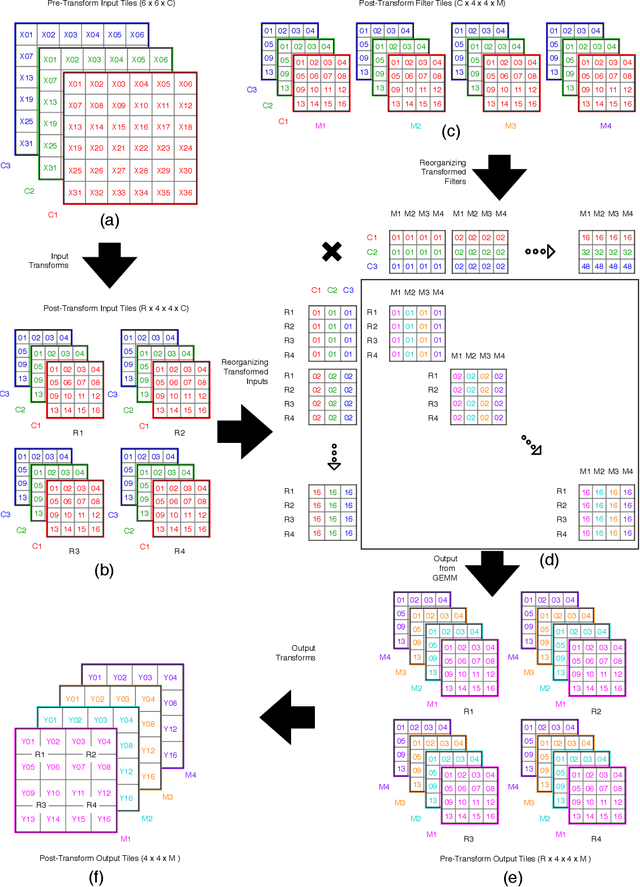
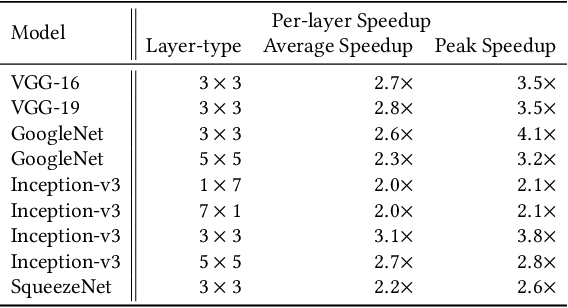
The Winograd or Cook-Toom class of algorithms help to reduce the overall compute complexity of many modern deep convolutional neural networks (CNNs). Although there has been a lot of research done on model and algorithmic optimization of CNN, little attention has been paid to the efficient implementation of these algorithms on embedded CPUs, which usually have very limited memory and low power budget. This paper aims to fill this gap and focuses on the efficient implementation of Winograd or Cook-Toom based convolution on modern Arm Cortex-A CPUs, widely used in mobile devices today. Specifically, we demonstrate a reduction in inference latency by using a set of optimization strategies that improve the utilization of computational resources, and by effectively leveraging the ARMv8-A NEON SIMD instruction set. We evaluated our proposed region-wise multi-channel implementations on Arm Cortex-A73 platform using several representative CNNs. The results show significant performance improvements in full network, up to 60%, over existing im2row/im2col based optimization techniques