 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTernary MobileNets via Per-Layer Hybrid Filter Banks
Paper and Code
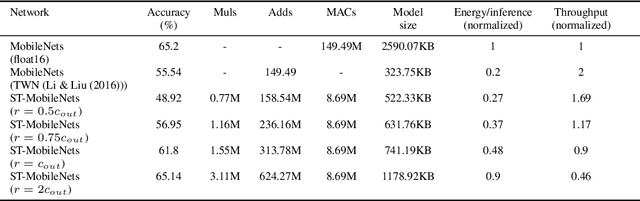
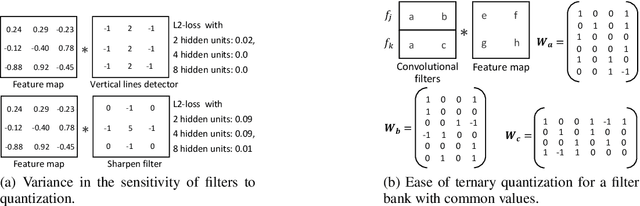
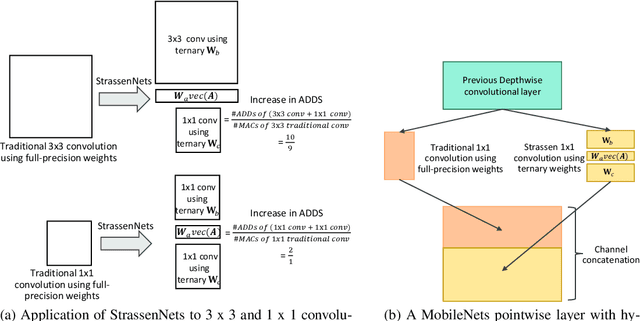
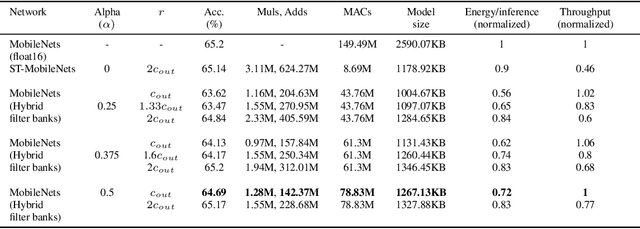
MobileNets family of computer vision neural networks have fueled tremendous progress in the design and organization of resource-efficient architectures in recent years. New applications with stringent real-time requirements on highly constrained devices require further compression of MobileNets-like already compute-efficient networks. Model quantization is a widely used technique to compress and accelerate neural network inference and prior works have quantized MobileNets to 4-6 bits albeit with a modest to significant drop in accuracy. While quantization to sub-byte values (i.e. precision less than or equal to 8 bits) has been valuable, even further quantization of MobileNets to binary or ternary values is necessary to realize significant energy savings and possibly runtime speedups on specialized hardware, such as ASICs and FPGAs. Under the key observation that convolutional filters at each layer of a deep neural network may respond differently to ternary quantization, we propose a novel quantization method that generates per-layer hybrid filter banks consisting of full-precision and ternary weight filters for MobileNets. The layer-wise hybrid filter banks essentially combine the strengths of full-precision and ternary weight filters to derive a compact, energy-efficient architecture for MobileNets. Using this proposed quantization method, we quantized a substantial portion of weight filters of MobileNets to ternary values resulting in 27.98% savings in energy, and a 51.07% reduction in the model size, while achieving comparable accuracy and no degradation in throughput on specialized hardware in comparison to the baseline full-precision MobileNets.