 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandgun detection using combined human pose and weapon appearance
Oct 26, 2020


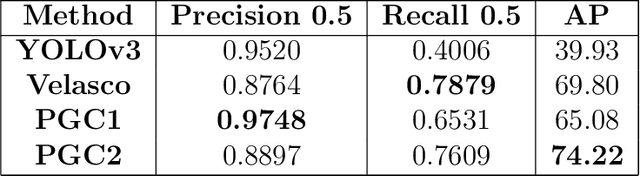
CCTV surveillance systems are essential nowadays to prevent and mitigate security threats or dangerous situations such as mass shootings or terrorist attacks, in which early detection is crucial. These solutions are manually supervised by a security operator, which has significant limitations. Novel deep learning-based methods have allowed to develop automatic and real time weapon detectors with promising results. However, these approaches are based on visual weapon appearance only and no additional contextual information is exploited. For handguns, body pose may be a useful cue, especially in cases where the gun is barely visible and also as a way to reduce false positives. In this work, a novel method is proposed to combine in a single architecture both weapon appearance and 2D human pose information. First, pose keypoints are estimated to extract hand regions and generate binary pose images, which are the model inputs. Then, each input is processed with a different subnetwork to extract two feature maps. Finally, this information is combined to produce the hand region prediction (handgun vs no-handgun). A new dataset composed of samples collected from different sources has been used to evaluate model performance under different situations. Moreover, the robustness of the model to different brightness and weapon size conditions (simulating conditions in which appearance is degraded by low light and distance to the camera) have also been tested. Results obtained show that the combined model improves overall performance substantially with respect to appearance alone as used by other popular methods such as YOLOv3.
AI Pipeline - bringing AI to you. End-to-end integration of data, algorithms and deployment tools
Jan 15, 2019



Next generation of embedded Information and Communication Technology (ICT) systems are interconnected collaborative intelligent systems able to perform autonomous tasks. Training and deployment of such systems on Edge devices however require a fine-grained integration of data and tools to achieve high accuracy and overcome functional and non-functional requirements. In this work, we present a modular AI pipeline as an integrating framework to bring data, algorithms and deployment tools together. By these means, we are able to interconnect the different entities or stages of particular systems and provide an end-to-end development of AI products. We demonstrate the effectiveness of the AI pipeline by solving an Automatic Speech Recognition challenge and we show that all the steps leading to an end-to-end development for Key-word Spotting tasks: importing, partitioning and pre-processing of speech data, training of different neural network architectures and their deployment on heterogeneous embedded platforms.