 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Learning for Personalized Keyword Spotting on Ultra-Low-Power Audio Sensors
Aug 22, 2024This paper proposes a self-learning framework to incrementally train (fine-tune) a personalized Keyword Spotting (KWS) model after the deployment on ultra-low power smart audio sensors. We address the fundamental problem of the absence of labeled training data by assigning pseudo-labels to the new recorded audio frames based on a similarity score with respect to few user recordings. By experimenting with multiple KWS models with a number of parameters up to 0.5M on two public datasets, we show an accuracy improvement of up to +19.2% and +16.0% vs. the initial models pretrained on a large set of generic keywords. The labeling task is demonstrated on a sensor system composed of a low-power microphone and an energy-efficient Microcontroller (MCU). By efficiently exploiting the heterogeneous processing engines of the MCU, the always-on labeling task runs in real-time with an average power cost of up to 8.2 mW. On the same platform, we estimate an energy cost for on-device training 10x lower than the labeling energy if sampling a new utterance every 5 s or 16.4 s with a DS-CNN-S or a DS-CNN-M model. Our empirical result paves the way to self-adaptive personalized KWS sensors at the extreme edge.
Accelerating RNN-based Speech Enhancement on a Multi-Core MCU with Mixed FP16-INT8 Post-Training Quantization
Oct 14, 2022



This paper presents an optimized methodology to design and deploy Speech Enhancement (SE) algorithms based on Recurrent Neural Networks (RNNs) on a state-of-the-art MicroController Unit (MCU), with 1+8 general-purpose RISC-V cores. To achieve low-latency execution, we propose an optimized software pipeline interleaving parallel computation of LSTM or GRU recurrent blocks, featuring vectorized 8-bit integer (INT8) and 16-bit floating-point (FP16) compute units, with manually-managed memory transfers of model parameters. To ensure minimal accuracy degradation with respect to the full-precision models, we propose a novel FP16-INT8 Mixed-Precision Post-Training Quantization (PTQ) scheme that compresses the recurrent layers to 8-bit while the bit precision of remaining layers is kept to FP16. Experiments are conducted on multiple LSTM and GRU based SE models trained on the Valentini dataset, featuring up to 1.24M parameters. Thanks to the proposed approaches, we speed-up the computation by up to 4x with respect to the lossless FP16 baselines. Differently from a uniform 8-bit quantization that degrades the PESQ score by 0.3 on average, the Mixed-Precision PTQ scheme leads to a low-degradation of only 0.06, while achieving a 1.4-1.7x memory saving. Thanks to this compression, we cut the power cost of the external memory by fitting the large models on the limited on-chip non-volatile memory and we gain a MCU power saving of up to 2.5x by reducing the supply voltage from 0.8V to 0.65V while still matching the real-time constraints. Our design results 10x more energy efficient than state-of-the-art SE solutions deployed on single-core MCUs that make use of smaller models and quantization-aware training.
Vega: A 10-Core SoC for IoT End-Nodes with DNN Acceleration and Cognitive Wake-Up From MRAM-Based State-Retentive Sleep Mode
Oct 18, 2021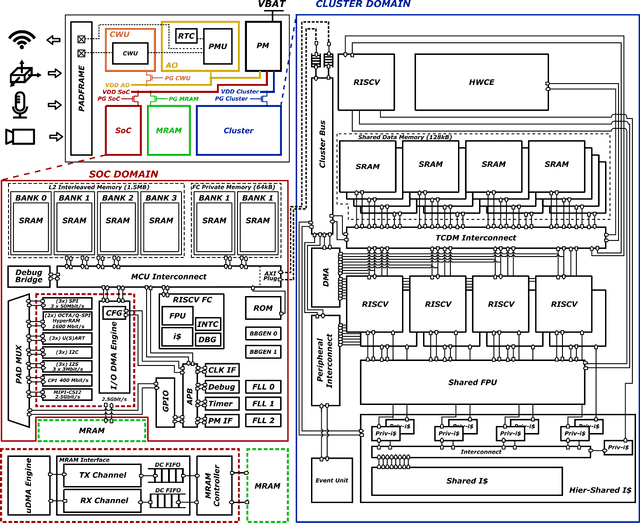
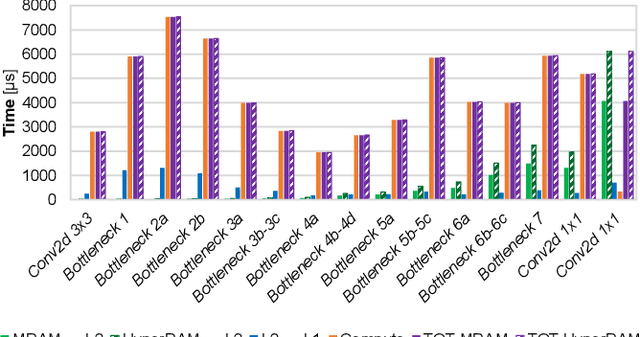
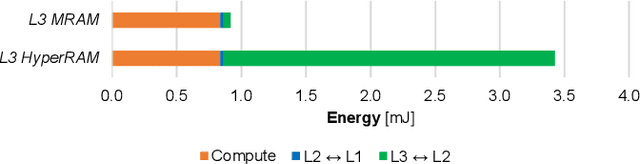
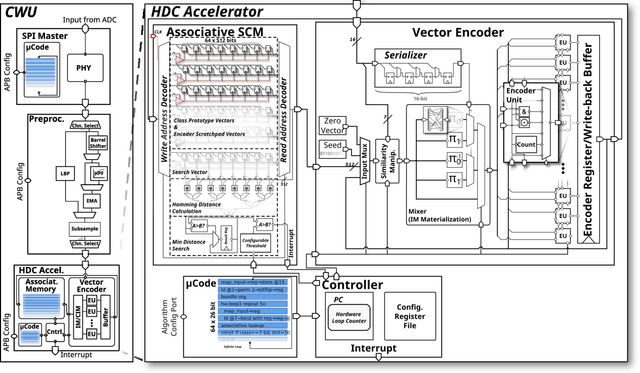
The Internet-of-Things requires end-nodes with ultra-low-power always-on capability for a long battery lifetime, as well as high performance, energy efficiency, and extreme flexibility to deal with complex and fast-evolving near-sensor analytics algorithms (NSAAs). We present Vega, an IoT end-node SoC capable of scaling from a 1.7 $\mathrm{\mu}$W fully retentive cognitive sleep mode up to 32.2 GOPS (@ 49.4 mW) peak performance on NSAAs, including mobile DNN inference, exploiting 1.6 MB of state-retentive SRAM, and 4 MB of non-volatile MRAM. To meet the performance and flexibility requirements of NSAAs, the SoC features 10 RISC-V cores: one core for SoC and IO management and a 9-cores cluster supporting multi-precision SIMD integer and floating-point computation. Vega achieves SoA-leading efficiency of 615 GOPS/W on 8-bit INT computation (boosted to 1.3TOPS/W for 8-bit DNN inference with hardware acceleration). On floating-point (FP) compuation, it achieves SoA-leading efficiency of 79 and 129 GFLOPS/W on 32- and 16-bit FP, respectively. Two programmable machine-learning (ML) accelerators boost energy efficiency in cognitive sleep and active states, respectively.
A 64mW DNN-based Visual Navigation Engine for Autonomous Nano-Drones
Jan 15, 2019
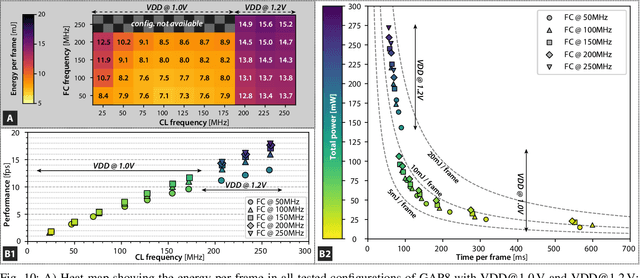
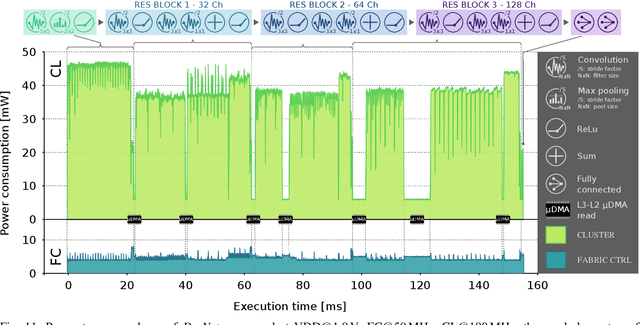

Fully-autonomous miniaturized robots (e.g., drones), with artificial intelligence (AI) based visual navigation capabilities are extremely challenging drivers of Internet-of-Things edge intelligence capabilities. Visual navigation based on AI approaches, such as deep neural networks (DNNs) are becoming pervasive for standard-size drones, but are considered out of reach for nanodrones with size of a few cm${}^\mathrm{2}$. In this work, we present the first (to the best of our knowledge) demonstration of a navigation engine for autonomous nano-drones capable of closed-loop end-to-end DNN-based visual navigation. To achieve this goal we developed a complete methodology for parallel execution of complex DNNs directly on-bard of resource-constrained milliwatt-scale nodes. Our system is based on GAP8, a novel parallel ultra-low-power computing platform, and a 27 g commercial, open-source CrazyFlie 2.0 nano-quadrotor. As part of our general methodology we discuss the software mapping techniques that enable the state-of-the-art deep convolutional neural network presented in [1] to be fully executed on-board within a strict 6 fps real-time constraint with no compromise in terms of flight results, while all processing is done with only 64 mW on average. Our navigation engine is flexible and can be used to span a wide performance range: at its peak performance corner it achieves 18 fps while still consuming on average just 3.5% of the power envelope of the deployed nano-aircraft.