 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic ConvNets on Tiny Devices via Nested Sparsity
Mar 07, 2022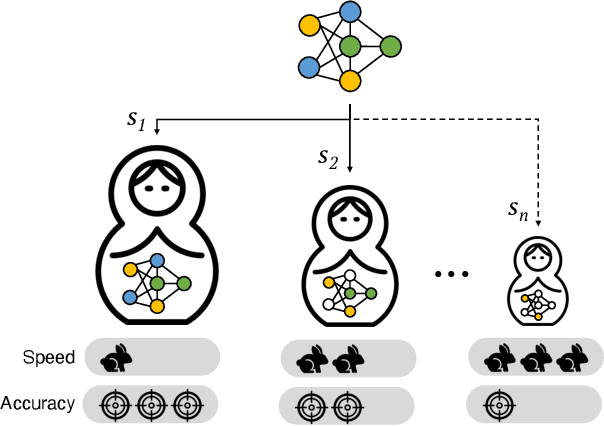
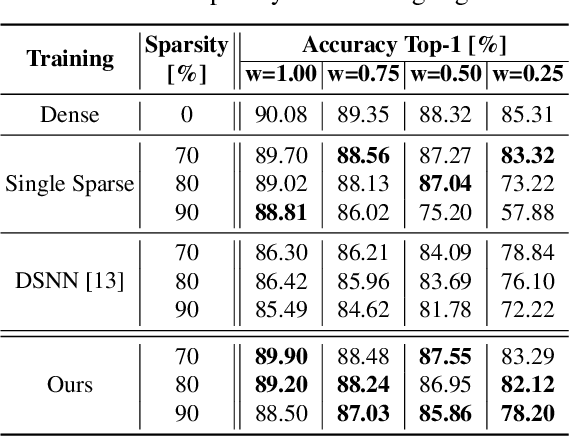
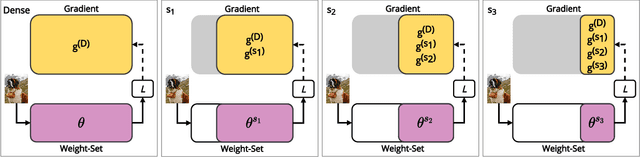

This work introduces a new training and compression pipeline to build Nested Sparse ConvNets, a class of dynamic Convolutional Neural Networks (ConvNets) suited for inference tasks deployed on resource-constrained devices at the edge of the Internet-of-Things. A Nested Sparse ConvNet consists of a single ConvNet architecture containing N sparse sub-networks with nested weights subsets, like a Matryoshka doll, and can trade accuracy for latency at run time, using the model sparsity as a dynamic knob. To attain high accuracy at training time, we propose a gradient masking technique that optimally routes the learning signals across the nested weights subsets. To minimize the storage footprint and efficiently process the obtained models at inference time, we introduce a new sparse matrix compression format with dedicated compute kernels that fruitfully exploit the characteristic of the nested weights subsets. Tested on image classification and object detection tasks on an off-the-shelf ARM-M7 Micro Controller Unit (MCU), Nested Sparse ConvNets outperform variable-latency solutions naively built assembling single sparse models trained as stand-alone instances, achieving (i) comparable accuracy, (ii) remarkable storage savings, and (iii) high performance. Moreover, when compared to state-of-the-art dynamic strategies, like dynamic pruning and layer width scaling, Nested Sparse ConvNets turn out to be Pareto optimal in the accuracy vs. latency space.
Adaptive Test-Time Augmentation for Low-Power CPU
May 13, 2021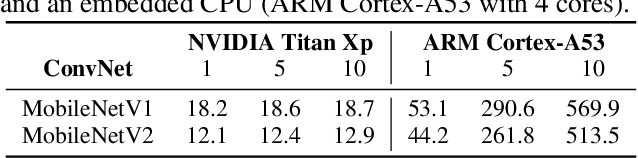
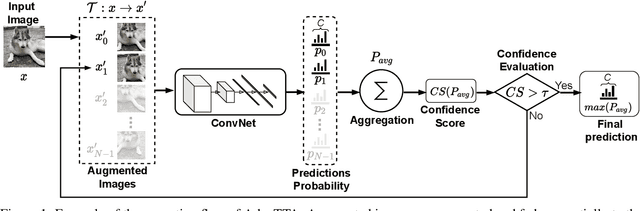

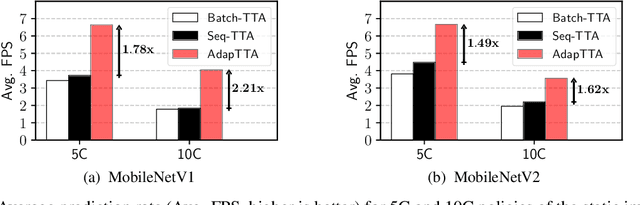
Convolutional Neural Networks (ConvNets) are trained offline using the few available data and may therefore suffer from substantial accuracy loss when ported on the field, where unseen input patterns received under unpredictable external conditions can mislead the model. Test-Time Augmentation (TTA) techniques aim to alleviate such common side effect at inference-time, first running multiple feed-forward passes on a set of altered versions of the same input sample, and then computing the main outcome through a consensus of the aggregated predictions. Unfortunately, the implementation of TTA on embedded CPUs introduces latency penalties that limit its adoption on edge applications. To tackle this issue, we propose AdapTTA, an adaptive implementation of TTA that controls the number of feed-forward passes dynamically, depending on the complexity of the input. Experimental results on state-of-the-art ConvNets for image classification deployed on a commercial ARM Cortex-A CPU demonstrate AdapTTA reaches remarkable latency savings, from 1.49X to 2.21X, and hence a higher frame rate compared to static TTA, still preserving the same accuracy gain.
TentacleNet: A Pseudo-Ensemble Template for Accurate Binary Convolutional Neural Networks
Dec 26, 2019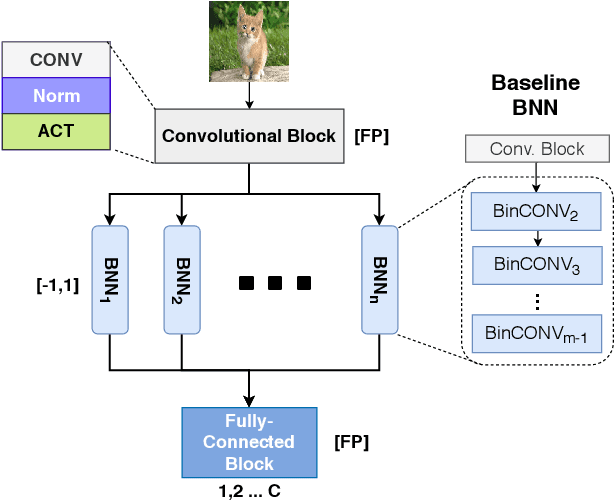
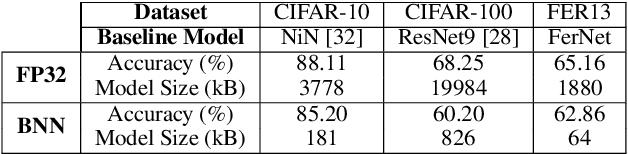
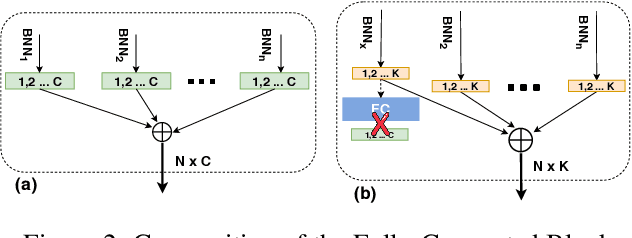
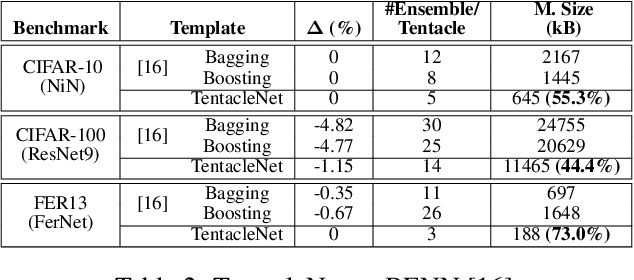
Binarization is an attractive strategy for implementing lightweight Deep Convolutional Neural Networks (CNNs). Despite the unquestionable savings offered, memory footprint above all, it may induce an excessive accuracy loss that prevents a widespread use. This work elaborates on this aspect introducing TentacleNet, a new template designed to improve the predictive performance of binarized CNNs via parallelization. Inspired by the ensemble learning theory, it consists of a compact topology that is end-to-end trainable and organized to minimize memory utilization. Experimental results collected over three realistic benchmarks show TentacleNet fills the gap left by classical binary models, ensuring substantial memory savings w.r.t. state-of-the-art binary ensemble methods.
CoopNet: Cooperative Convolutional Neural Network for Low-Power MCUs
Nov 26, 2019
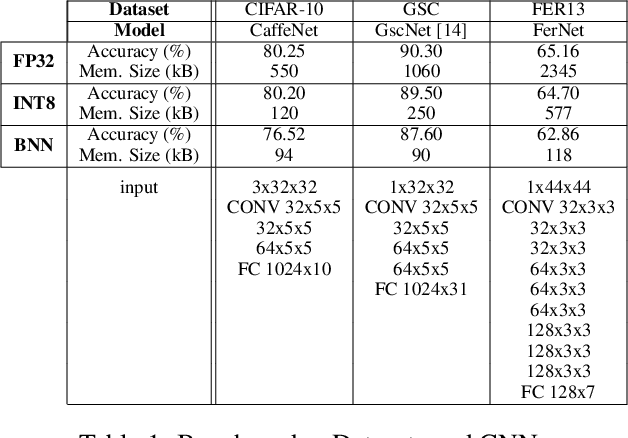


Fixed-point quantization and binarization are two reduction methods adopted to deploy Convolutional Neural Networks (CNN) on end-nodes powered by low-power micro-controller units (MCUs). While most of the existing works use them as stand-alone optimizations, this work aims at demonstrating there is margin for a joint cooperation that leads to inferential engines with lower latency and higher accuracy. Called CoopNet, the proposed heterogeneous model is conceived, implemented and tested on off-the-shelf MCUs with small on-chip memory and few computational resources. Experimental results conducted on three different CNNs using as test-bench the low-power RISC core of the Cortex-M family by ARM validate the CoopNet proposal by showing substantial improvements w.r.t. designs where quantization and binarization are applied separately.