 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Pruning using a Lightweight Background Aware Vision Transformer
Oct 12, 2024
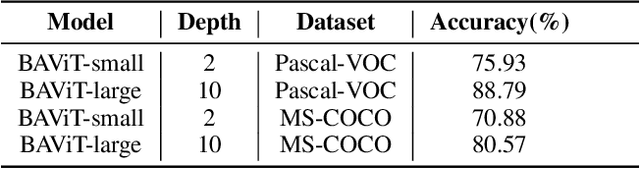

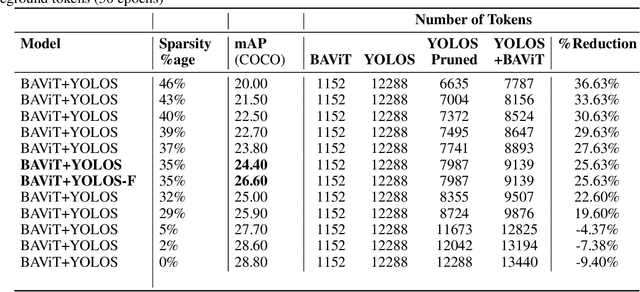
High runtime memory and high latency puts significant constraint on Vision Transformer training and inference, especially on edge devices. Token pruning reduces the number of input tokens to the ViT based on importance criteria of each token. We present a Background Aware Vision Transformer (BAViT) model, a pre-processing block to object detection models like DETR/YOLOS aimed to reduce runtime memory and increase throughput by using a novel approach to identify background tokens in the image. The background tokens can be pruned completely or partially before feeding to a ViT based object detector. We use the semantic information provided by segmentation map and/or bounding box annotation to train a few layers of ViT to classify tokens to either foreground or background. Using 2 layers and 10 layers of BAViT, background and foreground tokens can be separated with 75% and 88% accuracy on VOC dataset and 71% and 80% accuracy on COCO dataset respectively. We show a 2 layer BAViT-small model as pre-processor to YOLOS can increase the throughput by 30% - 40% with a mAP drop of 3% without any sparse fine-tuning and 2% with sparse fine-tuning. Our approach is specifically targeted for Edge AI use cases.
MCUBench: A Benchmark of Tiny Object Detectors on MCUs
Sep 27, 2024We introduce MCUBench, a benchmark featuring over 100 YOLO-based object detection models evaluated on the VOC dataset across seven different MCUs. This benchmark provides detailed data on average precision, latency, RAM, and Flash usage for various input resolutions and YOLO-based one-stage detectors. By conducting a controlled comparison with a fixed training pipeline, we collect comprehensive performance metrics. Our Pareto-optimal analysis shows that integrating modern detection heads and training techniques allows various YOLO architectures, including legacy models like YOLOv3, to achieve a highly efficient tradeoff between mean Average Precision (mAP) and latency. MCUBench serves as a valuable tool for benchmarking the MCU performance of contemporary object detectors and aids in model selection based on specific constraints.