 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Efficient Mixture-of-Agent Scheduling via Adaptive Aggregation and Inference Concurrency
Jun 02, 2026Mixture-of-Agents (MoA) systems improve reasoning accuracy by routing each query to multiple expert LLMs and aggregating their outputs. Efficiently executing this workload on limited GPU resources has bottlenecks. Skill-based routing creates skewed expert demand, and combining instruction-tuned LLMs with long-reasoning models results in extreme variability in generation lengths. Consequently, traditional scheduling strategies suffer from significant GPU idling and throughput collapse due to load imbalances. We present MOSAIC, a scheduling framework to accelerate MoA workloads. First, we formulate an Integer Linear Program (ILP) based scheduler that jointly optimizes expert placement and per-worker prompt assignment from offline-profiled costs, replicating reasoning experts across workers while pinning lightweight ones. Second, MOSAIC uses confidence-aware adaptive aggregation, leveraging inter-expert agreement to bypass the heavy final aggregator LLM for consensus queries. In our 4-GPU system, MOSAIC achieves up to 2.5x expert-stage, 4.23x aggregator-stage and 1.7~2.3x end-to-end speedups over the baseline scheduler, while matching accuracy within 0.1pp.
Characterizing State Space Model (SSM) and SSM-Transformer Hybrid Language Model Performance with Long Context Length
Jul 16, 2025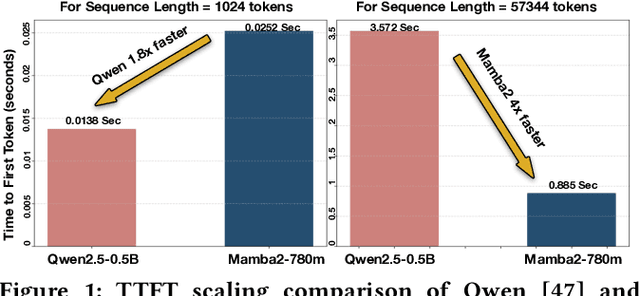

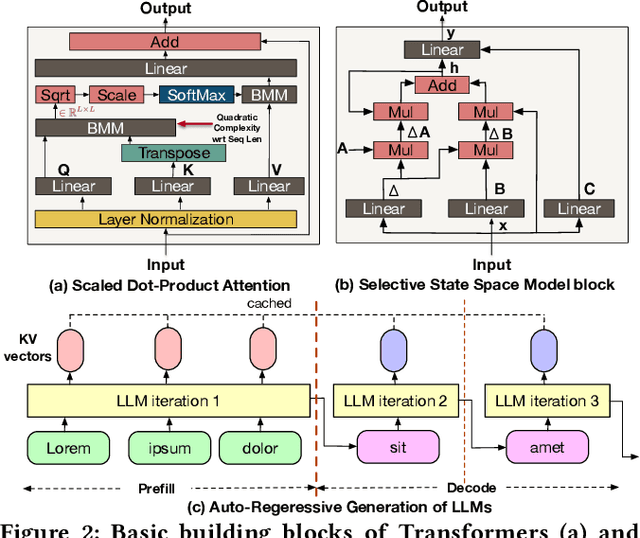
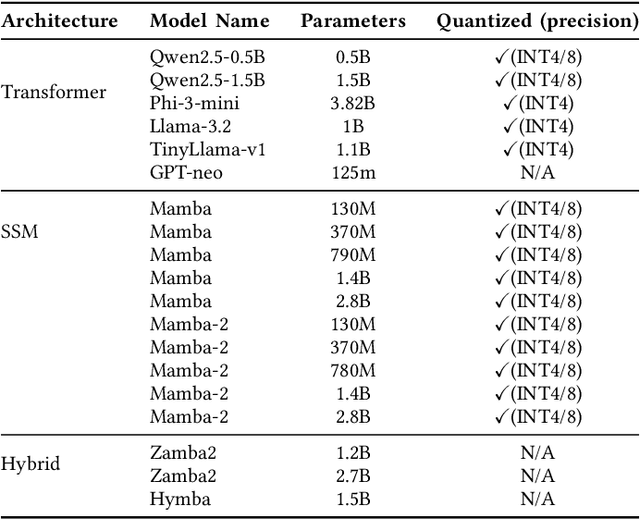
The demand for machine intelligence capable of processing continuous, long-context inputs on local devices is growing rapidly. However, the quadratic complexity and memory requirements of traditional Transformer architectures make them inefficient and often unusable for these tasks. This has spurred a paradigm shift towards new architectures like State Space Models (SSMs) and hybrids, which promise near-linear scaling. While most current research focuses on the accuracy and theoretical throughput of these models, a systematic performance characterization on practical consumer hardware is critically needed to guide system-level optimization and unlock new applications. To address this gap, we present a comprehensive, comparative benchmarking of carefully selected Transformer, SSM, and hybrid models specifically for long-context inference on consumer and embedded GPUs. Our analysis reveals that SSMs are not only viable but superior for this domain, capable of processing sequences up to 220K tokens on a 24GB consumer GPU-approximately 4x longer than comparable Transformers. While Transformers may be up to 1.8x faster at short sequences, SSMs demonstrate a dramatic performance inversion, becoming up to 4x faster at very long contexts (~57K tokens). Our operator-level analysis reveals that custom, hardware-aware SSM kernels dominate the inference runtime, accounting for over 55% of latency on edge platforms, identifying them as a primary target for future hardware acceleration. We also provide detailed, device-specific characterization results to guide system co-design for the edge. To foster further research, we will open-source our characterization framework.
DeepliteRT: Computer Vision at the Edge
Sep 19, 2023
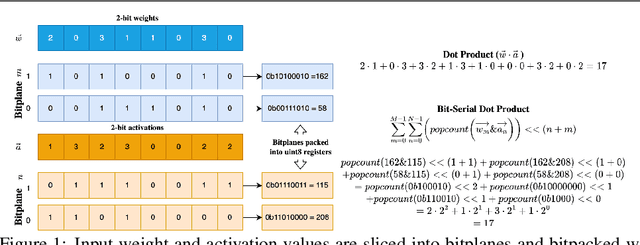
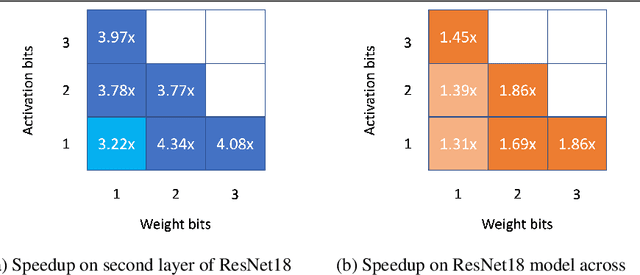
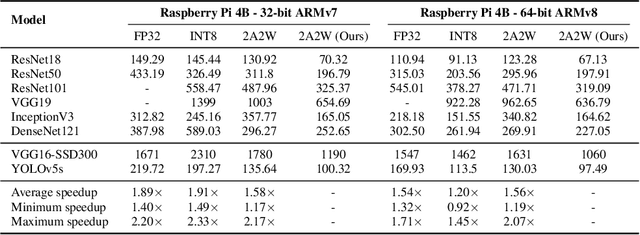
The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
YOLOBench: Benchmarking Efficient Object Detectors on Embedded Systems
Jul 26, 2023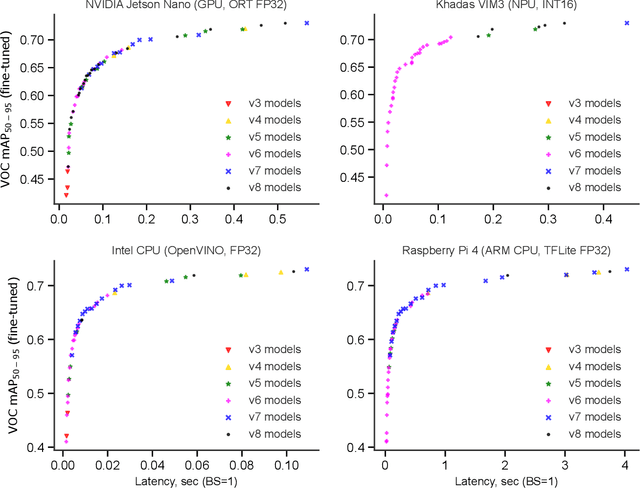
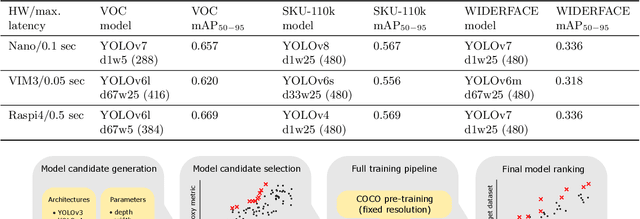
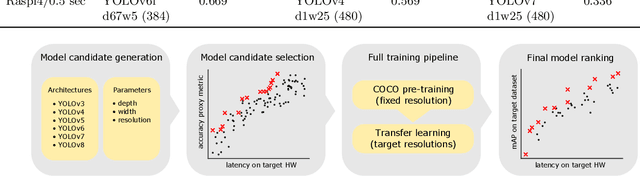
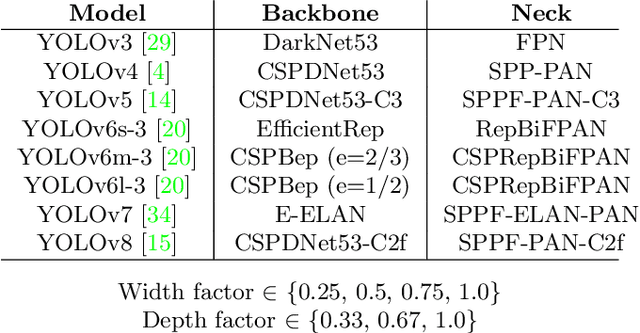
We present YOLOBench, a benchmark comprised of 550+ YOLO-based object detection models on 4 different datasets and 4 different embedded hardware platforms (x86 CPU, ARM CPU, Nvidia GPU, NPU). We collect accuracy and latency numbers for a variety of YOLO-based one-stage detectors at different model scales by performing a fair, controlled comparison of these detectors with a fixed training environment (code and training hyperparameters). Pareto-optimality analysis of the collected data reveals that, if modern detection heads and training techniques are incorporated into the learning process, multiple architectures of the YOLO series achieve a good accuracy-latency trade-off, including older models like YOLOv3 and YOLOv4. We also evaluate training-free accuracy estimators used in neural architecture search on YOLOBench and demonstrate that, while most state-of-the-art zero-cost accuracy estimators are outperformed by a simple baseline like MAC count, some of them can be effectively used to predict Pareto-optimal detection models. We showcase that by using a zero-cost proxy to identify a YOLO architecture competitive against a state-of-the-art YOLOv8 model on a Raspberry Pi 4 CPU. The code and data are available at https://github.com/Deeplite/deeplite-torch-zoo
DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures using Lookup Tables
Apr 18, 2023



A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.