 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHWGesture -- A dataset for multimodal understanding of clinical gestures
Sep 09, 2025Hand gesture understanding is essential for several applications in human-computer interaction, including automatic clinical assessment of hand dexterity. While deep learning has advanced static gesture recognition, dynamic gesture understanding remains challenging due to complex spatiotemporal variations. Moreover, existing datasets often lack multimodal and multi-view diversity, precise ground-truth tracking, and an action quality component embedded within gestures. This paper introduces EHWGesture, a multimodal video dataset for gesture understanding featuring five clinically relevant gestures. It includes over 1,100 recordings (6 hours), captured from 25 healthy subjects using two high-resolution RGB-Depth cameras and an event camera. A motion capture system provides precise ground-truth hand landmark tracking, and all devices are spatially calibrated and synchronized to ensure cross-modal alignment. Moreover, to embed an action quality task within gesture understanding, collected recordings are organized in classes of execution speed that mirror clinical evaluations of hand dexterity. Baseline experiments highlight the dataset's potential for gesture classification, gesture trigger detection, and action quality assessment. Thus, EHWGesture can serve as a comprehensive benchmark for advancing multimodal clinical gesture understanding.
Low-complexity acoustic scene classification in DCASE 2022 Challenge
Jun 08, 2022

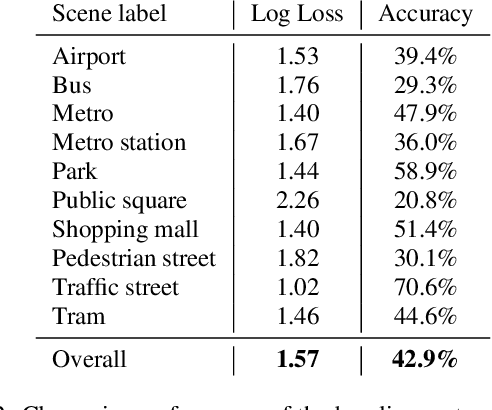
This paper analyzes the outcome of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task is a continuation from the previous years. In this edition, the requirement for low-complexity solutions were modified including: a limit of 128 K on the number of parameters, including the zero-valued ones, imposed INT8 numerical format, and a limit of 30 million multiply-accumulate operations at inference time. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46512 parameters, and 29.23 million multiply-and-accumulate operations, well under the set limits of 128K and 30 million, respectively. The baseline system has a 42.9% accuracy and a log-loss of 1.575 on the development data consisting of audio from 9 different devices. An analysis of the submitted systems will be provided after the challenge deadline.
PhiNets: a scalable backbone for low-power AI at the edge
Oct 01, 2021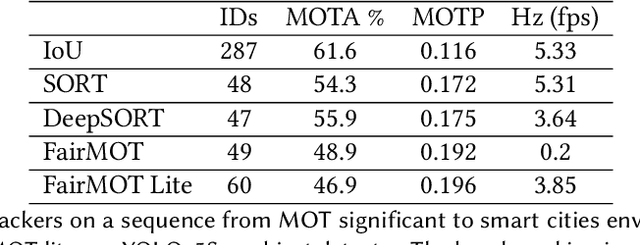
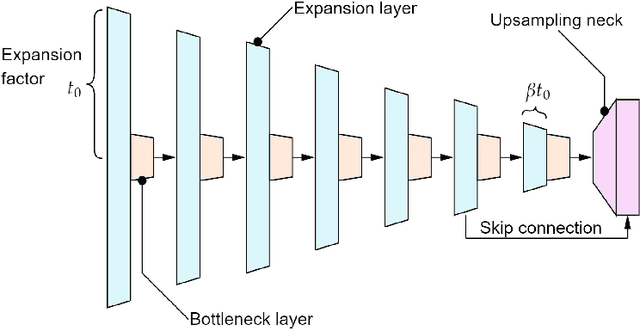
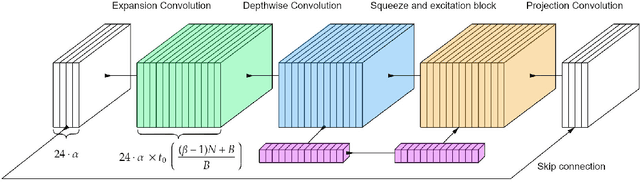

In the Internet of Things era, where we see many interconnected and heterogeneous mobile and fixed smart devices, distributing the intelligence from the cloud to the edge has become a necessity. Due to limited computational and communication capabilities, low memory and limited energy budget, bringing artificial intelligence algorithms to peripheral devices, such as the end-nodes of a sensor network, is a challenging task and requires the design of innovative methods. In this work, we present PhiNets, a new scalable backbone optimized for deep-learning-based image processing on resource-constrained platforms. PhiNets are based on inverted residual blocks specifically designed to decouple the computational cost, working memory, and parameter memory, thus exploiting all the available resources. With a YoloV2 detection head and Simple Online and Realtime Tracking, the proposed architecture has achieved the state-of-the-art results in (i) detection on the COCO and VOC2012 benchmarks, and (ii) tracking on the MOT15 benchmark. PhiNets reduce the parameter count of 87% to 93% with respect to previous state-of-the-art models (EfficientNetv1, MobileNetv2) and achieve better performance with lower computational cost. Moreover, we demonstrate our approach on a prototype node based on a STM32H743 microcontroller (MCU) with 2MB of internal Flash and 1MB of RAM and achieve power requirements in the order of 10 mW. The code for the PhiNets is publicly available on GitHub.