 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Music Recognition in Manuscripts from the Ricordi Archive
Aug 14, 2024



The Ricordi archive, a prestigious collection of significant musical manuscripts from renowned opera composers such as Donizetti, Verdi and Puccini, has been digitized. This process has allowed us to automatically extract samples that represent various musical elements depicted on the manuscripts, including notes, staves, clefs, erasures, and composer's annotations, among others. To distinguish between digitization noise and actual music elements, a subset of these images was meticulously grouped and labeled by multiple individuals into several classes. After assessing the consistency of the annotations, we trained multiple neural network-based classifiers to differentiate between the identified music elements. The primary objective of this study was to evaluate the reliability of these classifiers, with the ultimate goal of using them for the automatic categorization of the remaining unannotated data set. The dataset, complemented by manual annotations, models, and source code used in these experiments are publicly accessible for replication purposes.
A Systematic Evaluation of Adversarial Attacks against Speech Emotion Recognition Models
Apr 29, 2024Speech emotion recognition (SER) is constantly gaining attention in recent years due to its potential applications in diverse fields and thanks to the possibility offered by deep learning technologies. However, recent studies have shown that deep learning models can be vulnerable to adversarial attacks. In this paper, we systematically assess this problem by examining the impact of various adversarial white-box and black-box attacks on different languages and genders within the context of SER. We first propose a suitable methodology for audio data processing, feature extraction, and CNN-LSTM architecture. The observed outcomes highlighted the significant vulnerability of CNN-LSTM models to adversarial examples (AEs). In fact, all the considered adversarial attacks are able to significantly reduce the performance of the constructed models. Furthermore, when assessing the efficacy of the attacks, minor differences were noted between the languages analyzed as well as between male and female speech. In summary, this work contributes to the understanding of the robustness of CNN-LSTM models, particularly in SER scenarios, and the impact of AEs. Interestingly, our findings serve as a baseline for a) developing more robust algorithms for SER, b) designing more effective attacks, c) investigating possible defenses, d) improved understanding of the vocal differences between different languages and genders, and e) overall, enhancing our comprehension of the SER task.
Deep Feature Learning for Medical Acoustics
Aug 05, 2022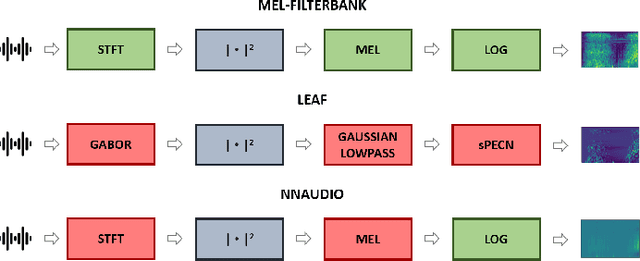

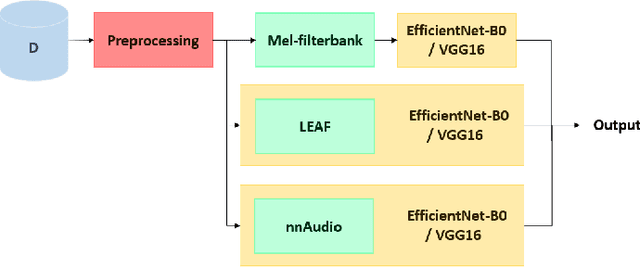
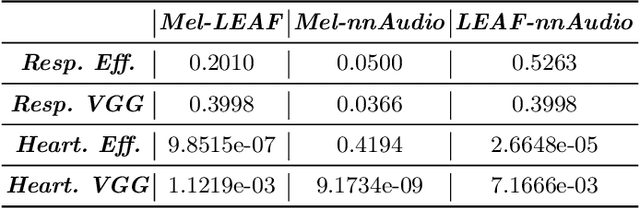
The purpose of this paper is to compare different learnable frontends in medical acoustics tasks. A framework has been implemented to classify human respiratory sounds and heartbeats in two categories, i.e. healthy or affected by pathologies. After obtaining two suitable datasets, we proceeded to classify the sounds using two learnable state-of-art frontends -- LEAF and nnAudio -- plus a non-learnable baseline frontend, i.e. Mel-filterbanks. The computed features are then fed into two different CNN models, namely VGG16 and EfficientNet. The frontends are carefully benchmarked in terms of the number of parameters, computational resources, and effectiveness. This work demonstrates how the integration of learnable frontends in neural audio classification systems may improve performance, especially in the field of medical acoustics. However, the usage of such frameworks makes the needed amount of data even larger. Consequently, they are useful if the amount of data available for training is adequately large to assist the feature learning process.
Variational Autoencoders for Anomaly Detection in Respiratory Sounds
Aug 05, 2022


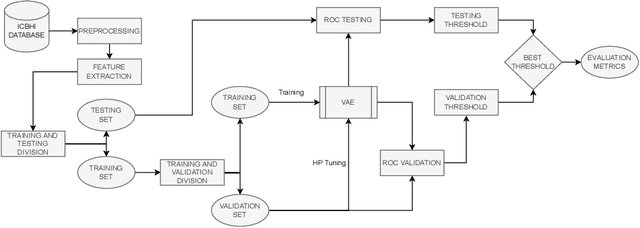
This paper proposes a weakly-supervised machine learning-based approach aiming at a tool to alert patients about possible respiratory diseases. Various types of pathologies may affect the respiratory system, potentially leading to severe diseases and, in certain cases, death. In general, effective prevention practices are considered as major actors towards the improvement of the patient's health condition. The proposed method strives to realize an easily accessible tool for the automatic diagnosis of respiratory diseases. Specifically, the method leverages Variational Autoencoder architectures permitting the usage of training pipelines of limited complexity and relatively small-sized datasets. Importantly, it offers an accuracy of 57 %, which is in line with the existing strongly-supervised approaches.
Context-aware Automatic Music Transcription
Mar 30, 2022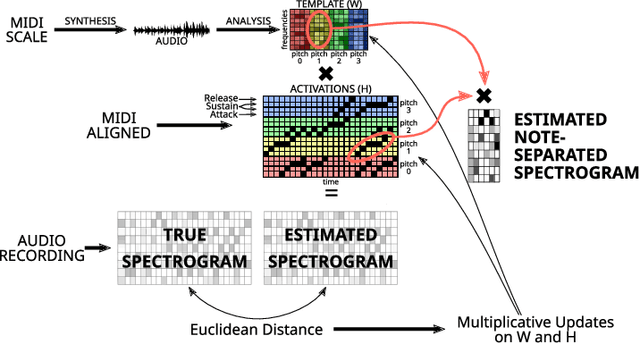
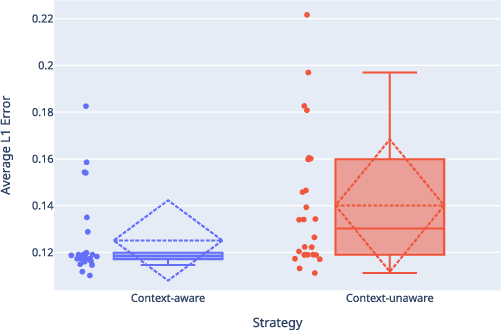
This paper presents an Automatic Music Transcription system that incorporates context-related information. Motivated by the state-of-art psychological research, we propose a methodology boosting the accuracy of AMT systems by modeling the adaptations that performers apply to successfully convey their interpretation in any acoustical context. In this work, we show that exploiting the knowledge of the source acoustical context allows reducing the error related to the inference of MIDI velocity. The proposed model structure first extracts the interpretation features and then applies the modeled performer adaptations. Interestingly, such a methodology is extensible in a straightforward way since only slight efforts are required to train completely context-aware AMT models.
A Perceptual Measure for Evaluating the Resynthesis of Automatic Music Transcriptions
Mar 07, 2022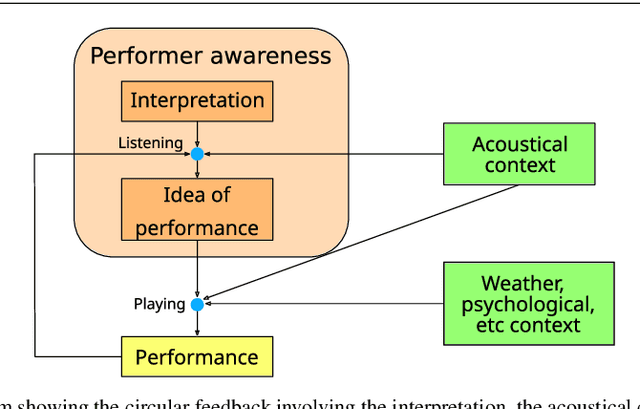
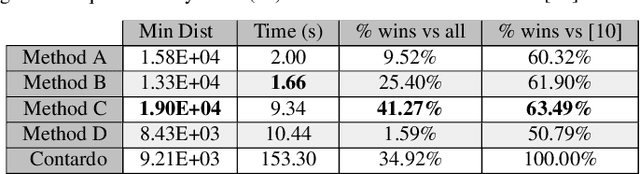
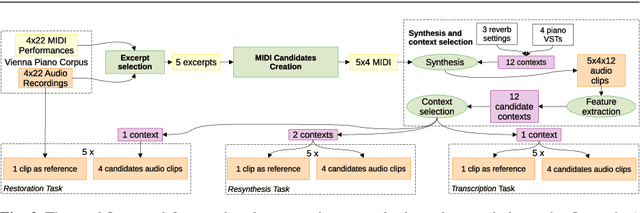

This study focuses on the perception of music performances when contextual factors, such as room acoustics and instrument, change. We propose to distinguish the concept of "performance" from the one of "interpretation", which expresses the "artistic intention". Towards assessing this distinction, we carried out an experimental evaluation where 91 subjects were invited to listen to various audio recordings created by resynthesizing MIDI data obtained through Automatic Music Transcription (AMT) systems and a sensorized acoustic piano. During the resynthesis, we simulated different contexts and asked listeners to evaluate how much the interpretation changes when the context changes. Results show that: (1) MIDI format alone is not able to completely grasp the artistic intention of a music performance; (2) usual objective evaluation measures based on MIDI data present low correlations with the average subjective evaluation. To bridge this gap, we propose a novel measure which is meaningfully correlated with the outcome of the tests. In addition, we investigate multimodal machine learning by providing a new score-informed AMT method and propose an approximation algorithm for the $p$-dispersion problem.
Interpreting deep urban sound classification using Layer-wise Relevance Propagation
Nov 19, 2021

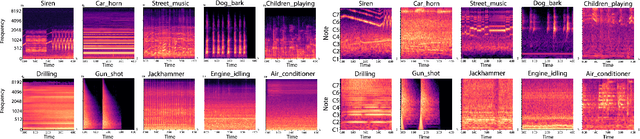
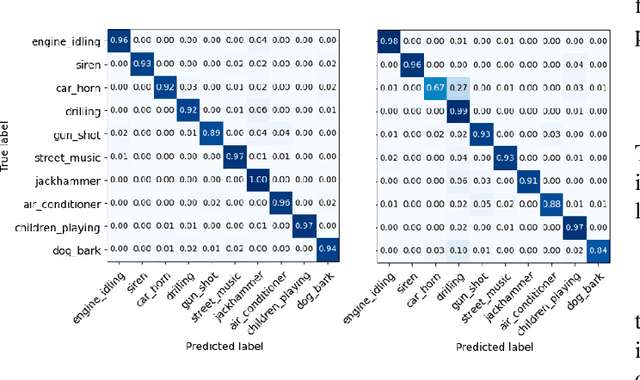
After constructing a deep neural network for urban sound classification, this work focuses on the sensitive application of assisting drivers suffering from hearing loss. As such, clear etiology justifying and interpreting model predictions comprise a strong requirement. To this end, we used two different representations of audio signals, i.e. Mel and constant-Q spectrograms, while the decisions made by the deep neural network are explained via layer-wise relevance propagation. At the same time, frequency content assigned with high relevance in both feature sets, indicates extremely discriminative information characterizing the present classification task. Overall, we present an explainable AI framework for understanding deep urban sound classification.
Audio-to-Score Alignment Using Deep Automatic Music Transcription
Jul 27, 2021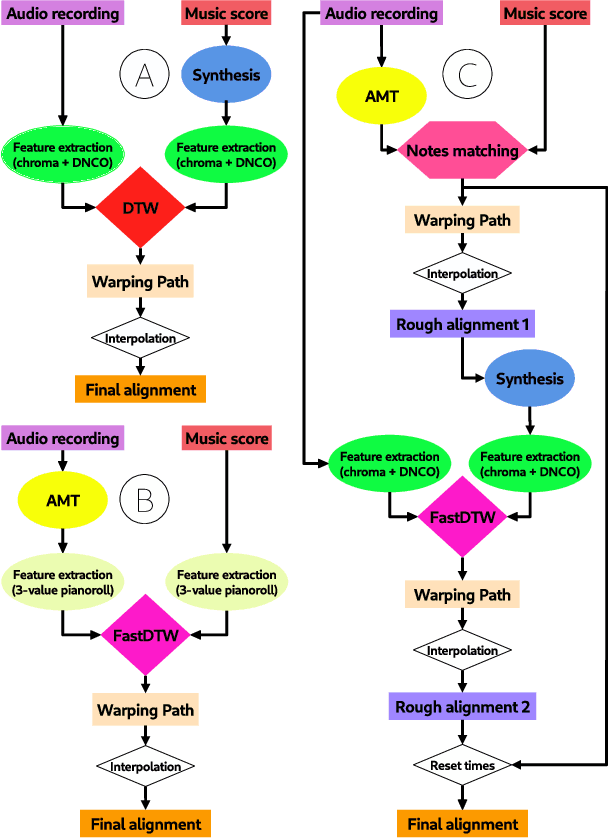
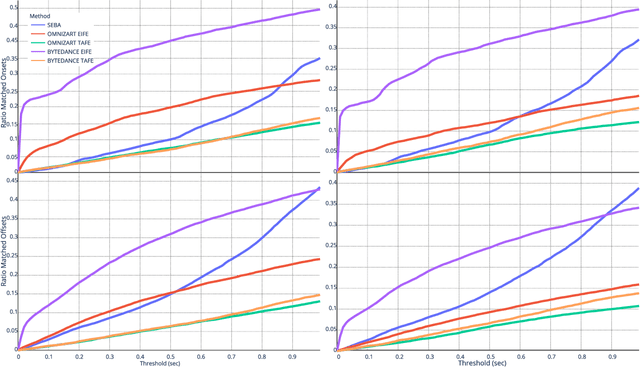


Audio-to-score alignment (A2SA) is a multimodal task consisting in the alignment of audio signals to music scores. Recent literature confirms the benefits of Automatic Music Transcription (AMT) for A2SA at the frame-level. In this work, we aim to elaborate on the exploitation of AMT Deep Learning (DL) models for achieving alignment at the note-level. We propose a method which benefits from HMM-based score-to-score alignment and AMT, showing a remarkable advancement beyond the state-of-the-art. We design a systematic procedure to take advantage of large datasets which do not offer an aligned score. Finally, we perform a thorough comparison and extensive tests on multiple datasets.
One-shot learning for acoustic identification of bird species in non-stationary environments
May 01, 2021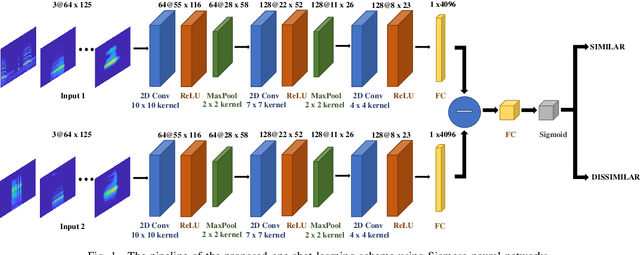

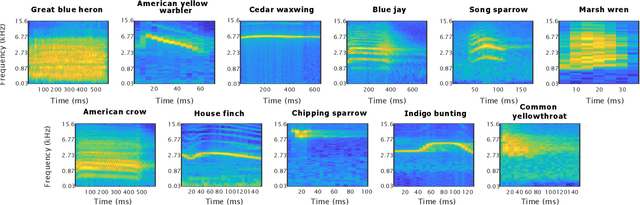
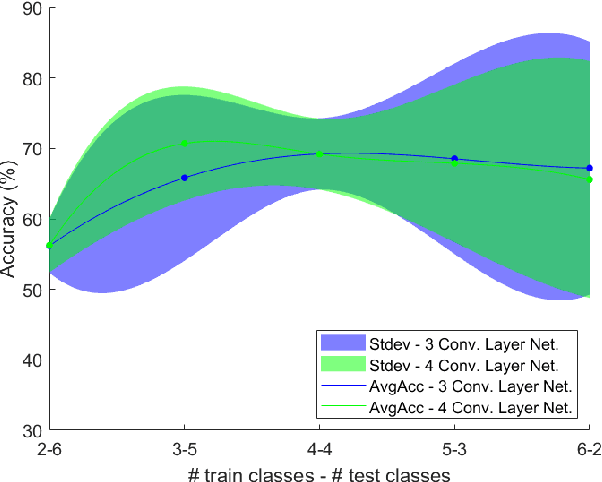
This work introduces the one-shot learning paradigm in the computational bioacoustics domain. Even though, most of the related literature assumes availability of data characterizing the entire class dictionary of the problem at hand, that is rarely true as a habitat's species composition is only known up to a certain extent. Thus, the problem needs to be addressed by methodologies able to cope with non-stationarity. To this end, we propose a framework able to detect changes in the class dictionary and incorporate new classes on the fly. We design an one-shot learning architecture composed of a Siamese Neural Network operating in the logMel spectrogram space. We extensively examine the proposed approach on two datasets of various bird species using suitable figures of merit. Interestingly, such a learning scheme exhibits state of the art performance, while taking into account extreme non-stationarity cases.
Cross-modal variational inference for bijective signal-symbol translation
Feb 10, 2020
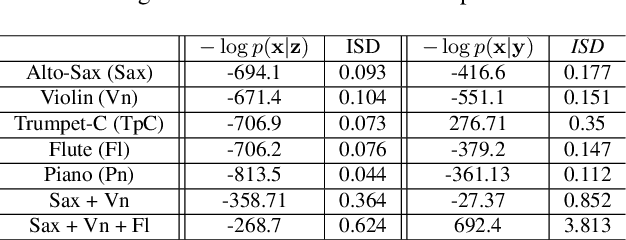
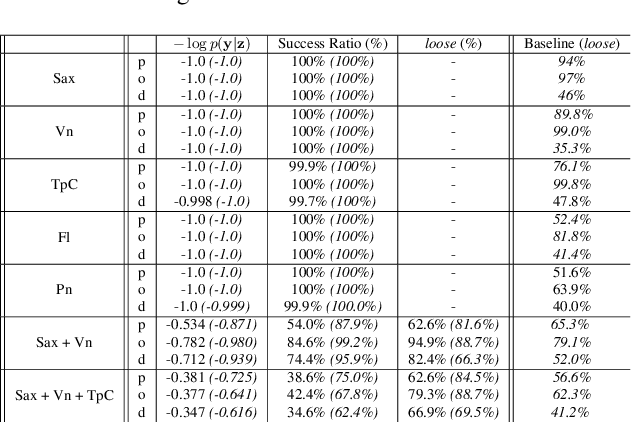

Extraction of symbolic information from signals is an active field of research enabling numerous applications especially in the Musical Information Retrieval domain. This complex task, that is also related to other topics such as pitch extraction or instrument recognition, is a demanding subject that gave birth to numerous approaches, mostly based on advanced signal processing-based algorithms. However, these techniques are often non-generic, allowing the extraction of definite physical properties of the signal (pitch, octave), but not allowing arbitrary vocabularies or more general annotations. On top of that, these techniques are one-sided, meaning that they can extract symbolic data from an audio signal, but cannot perform the reverse process and make symbol-to-signal generation. In this paper, we propose an bijective approach for signal/symbol translation by turning this problem into a density estimation task over signal and symbolic domains, considered both as related random variables. We estimate this joint distribution with two different variational auto-encoders, one for each domain, whose inner representations are forced to match with an additive constraint, allowing both models to learn and generate separately while allowing signal-to-symbol and symbol-to-signal inference. In this article, we test our models on pitch, octave and dynamics symbols, which comprise a fundamental step towards music transcription and label-constrained audio generation. In addition to its versatility, this system is rather light during training and generation while allowing several interesting creative uses that we outline at the end of the article.