 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Automatic Music Transcription
Mar 30, 2022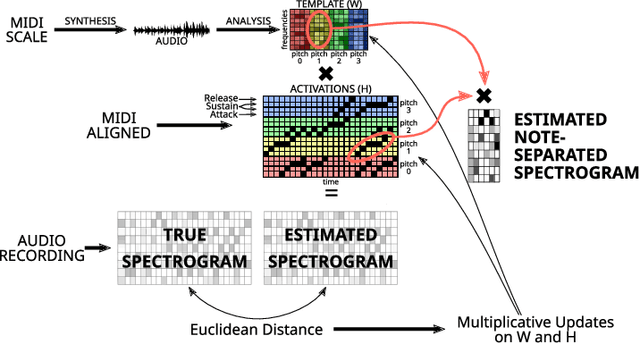
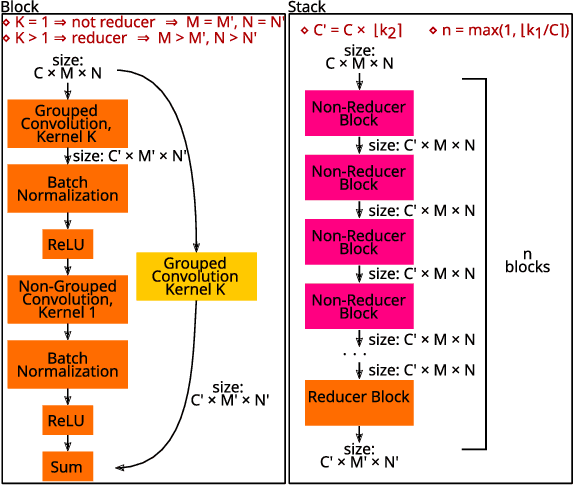
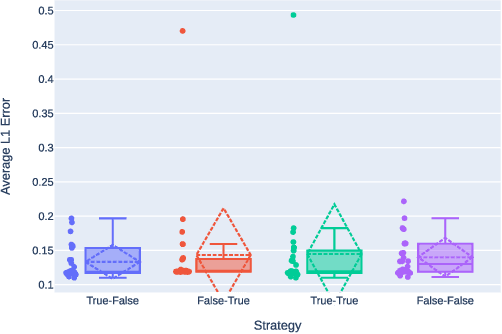
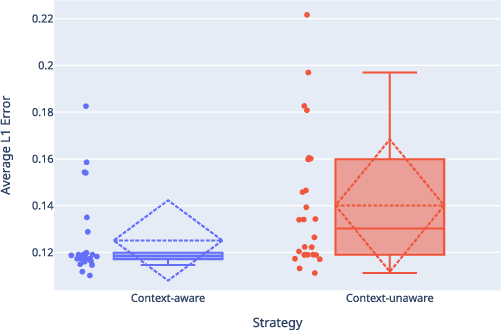
This paper presents an Automatic Music Transcription system that incorporates context-related information. Motivated by the state-of-art psychological research, we propose a methodology boosting the accuracy of AMT systems by modeling the adaptations that performers apply to successfully convey their interpretation in any acoustical context. In this work, we show that exploiting the knowledge of the source acoustical context allows reducing the error related to the inference of MIDI velocity. The proposed model structure first extracts the interpretation features and then applies the modeled performer adaptations. Interestingly, such a methodology is extensible in a straightforward way since only slight efforts are required to train completely context-aware AMT models.
A Perceptual Measure for Evaluating the Resynthesis of Automatic Music Transcriptions
Mar 07, 2022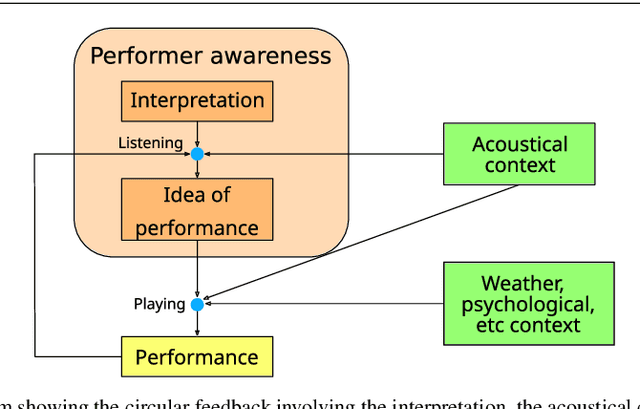
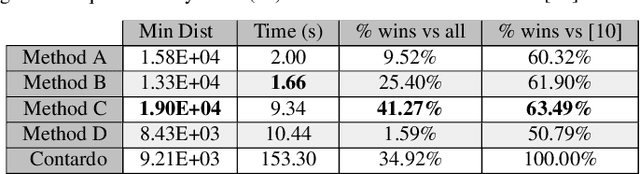
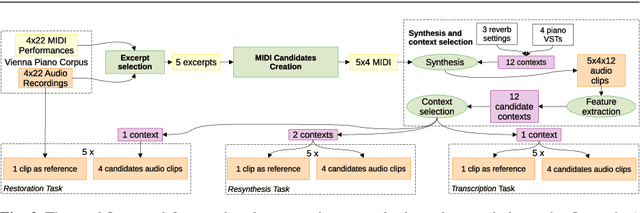

This study focuses on the perception of music performances when contextual factors, such as room acoustics and instrument, change. We propose to distinguish the concept of "performance" from the one of "interpretation", which expresses the "artistic intention". Towards assessing this distinction, we carried out an experimental evaluation where 91 subjects were invited to listen to various audio recordings created by resynthesizing MIDI data obtained through Automatic Music Transcription (AMT) systems and a sensorized acoustic piano. During the resynthesis, we simulated different contexts and asked listeners to evaluate how much the interpretation changes when the context changes. Results show that: (1) MIDI format alone is not able to completely grasp the artistic intention of a music performance; (2) usual objective evaluation measures based on MIDI data present low correlations with the average subjective evaluation. To bridge this gap, we propose a novel measure which is meaningfully correlated with the outcome of the tests. In addition, we investigate multimodal machine learning by providing a new score-informed AMT method and propose an approximation algorithm for the $p$-dispersion problem.
Audio-to-Score Alignment Using Deep Automatic Music Transcription
Jul 27, 2021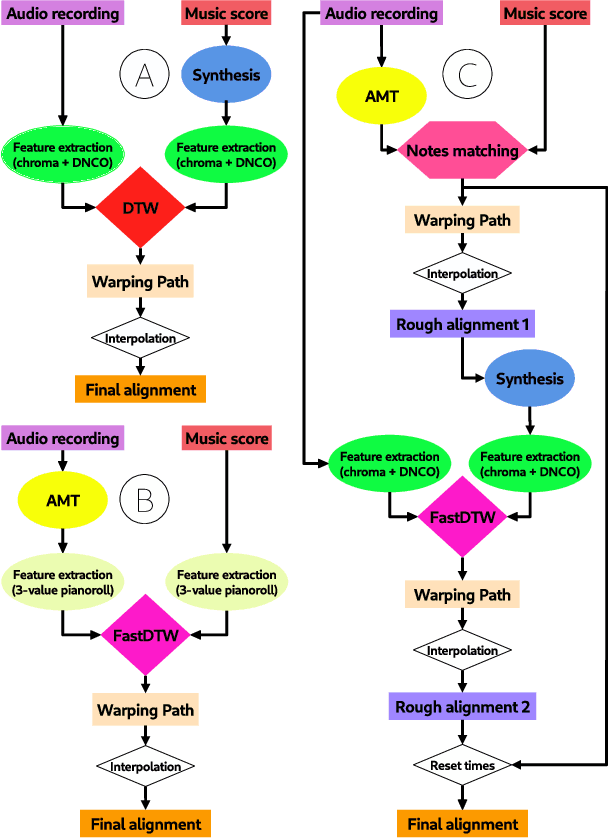


Audio-to-score alignment (A2SA) is a multimodal task consisting in the alignment of audio signals to music scores. Recent literature confirms the benefits of Automatic Music Transcription (AMT) for A2SA at the frame-level. In this work, we aim to elaborate on the exploitation of AMT Deep Learning (DL) models for achieving alignment at the note-level. We propose a method which benefits from HMM-based score-to-score alignment and AMT, showing a remarkable advancement beyond the state-of-the-art. We design a systematic procedure to take advantage of large datasets which do not offer an aligned score. Finally, we perform a thorough comparison and extensive tests on multiple datasets.
SofaMyRoom: a fast and multiplatform "shoebox" room simulator for binaural room impulse response dataset generation
Jun 24, 2021
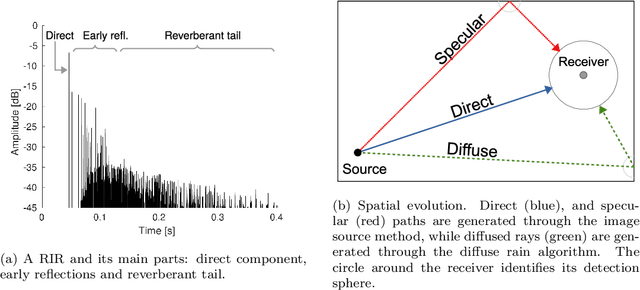
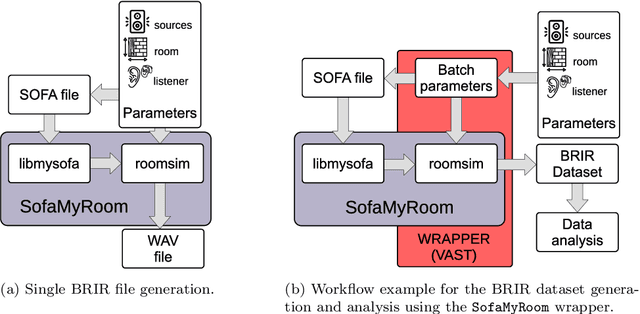
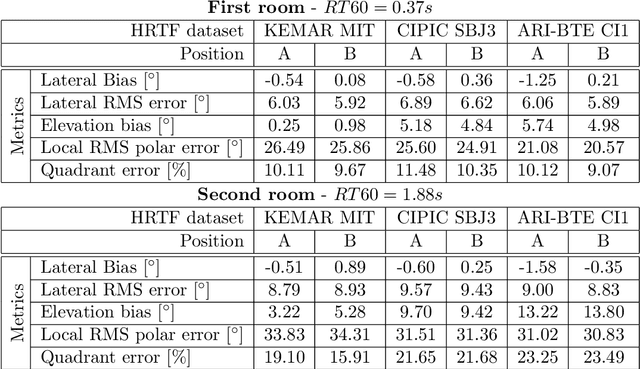
This paper introduces a shoebox room simulator able to systematically generate synthetic datasets of binaural room impulse responses (BRIRs) given an arbitrary set of head-related transfer functions (HRTFs). The evaluation of machine hearing algorithms frequently requires BRIR datasets in order to simulate the acoustics of any environment. However, currently available solutions typically consider only HRTFs measured on dummy heads, which poorly characterize the high variability in spatial sound perception. Our solution allows to integrate a room impulse response (RIR) simulator with different HRTF sets represented in Spatially Oriented Format for Acoustics (SOFA). The source code and the compiled binaries for different operating systems allow to both advanced and non-expert users to benefit from our toolbox, see https://github.com/spatialaudiotools/sofamyroom/ .