 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Feature Learning for Medical Acoustics
Aug 05, 2022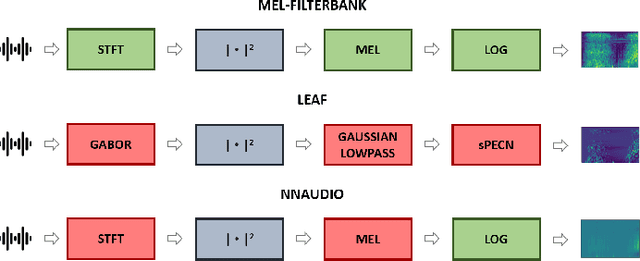

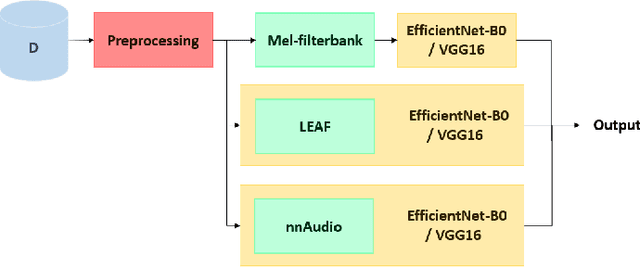
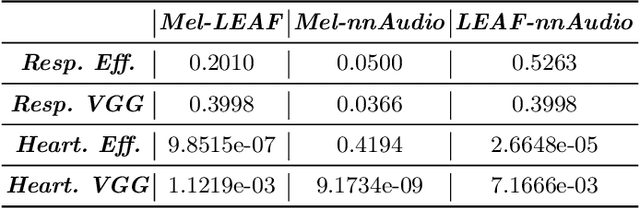
The purpose of this paper is to compare different learnable frontends in medical acoustics tasks. A framework has been implemented to classify human respiratory sounds and heartbeats in two categories, i.e. healthy or affected by pathologies. After obtaining two suitable datasets, we proceeded to classify the sounds using two learnable state-of-art frontends -- LEAF and nnAudio -- plus a non-learnable baseline frontend, i.e. Mel-filterbanks. The computed features are then fed into two different CNN models, namely VGG16 and EfficientNet. The frontends are carefully benchmarked in terms of the number of parameters, computational resources, and effectiveness. This work demonstrates how the integration of learnable frontends in neural audio classification systems may improve performance, especially in the field of medical acoustics. However, the usage of such frameworks makes the needed amount of data even larger. Consequently, they are useful if the amount of data available for training is adequately large to assist the feature learning process.