 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting emotion from music videos: exploring the relative contribution of visual and auditory information to affective responses
Feb 19, 2022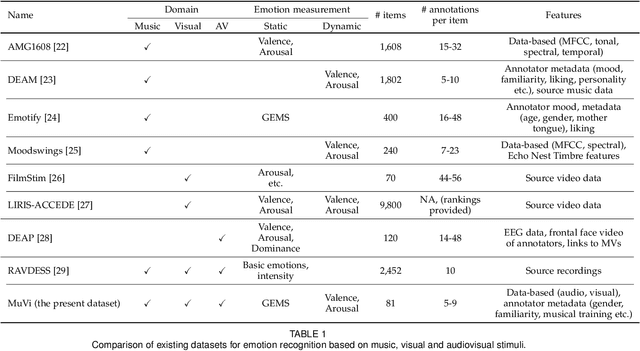

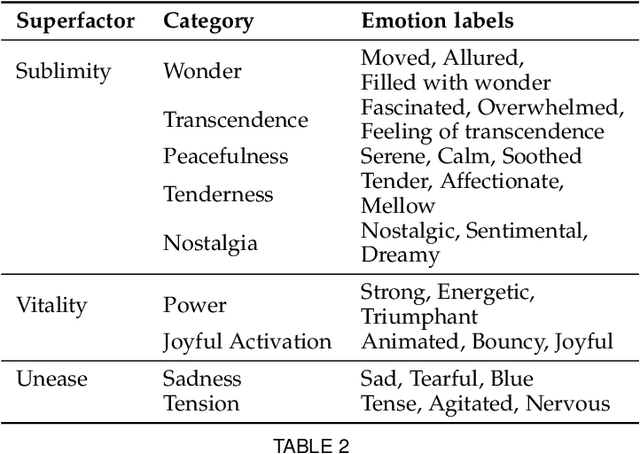
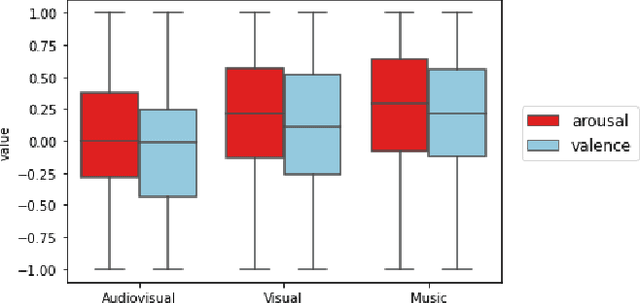
Although media content is increasingly produced, distributed, and consumed in multiple combinations of modalities, how individual modalities contribute to the perceived emotion of a media item remains poorly understood. In this paper we present MusicVideos (MuVi), a novel dataset for affective multimedia content analysis to study how the auditory and visual modalities contribute to the perceived emotion of media. The data were collected by presenting music videos to participants in three conditions: music, visual, and audiovisual. Participants annotated the music videos for valence and arousal over time, as well as the overall emotion conveyed. We present detailed descriptive statistics for key measures in the dataset and the results of feature importance analyses for each condition. Finally, we propose a novel transfer learning architecture to train Predictive models Augmented with Isolated modality Ratings (PAIR) and demonstrate the potential of isolated modality ratings for enhancing multimodal emotion recognition. Our results suggest that perceptions of arousal are influenced primarily by auditory information, while perceptions of valence are more subjective and can be influenced by both visual and auditory information. The dataset is made publicly available.
A dataset and classification model for Malay, Hindi, Tamil and Chinese music
Sep 15, 2020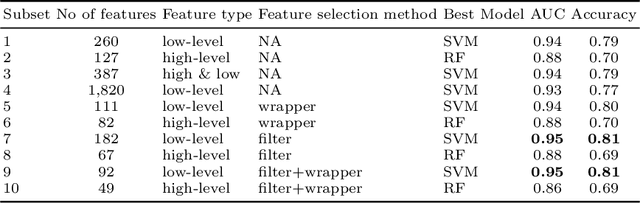
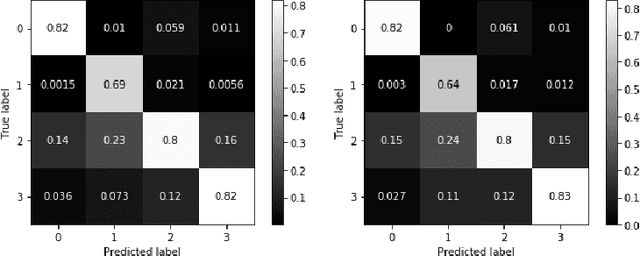
In this paper we present a new dataset, with musical excepts from the three main ethnic groups in Singapore: Chinese, Malay and Indian (both Hindi and Tamil). We use this new dataset to train different classification models to distinguish the origin of the music in terms of these ethnic groups. The classification models were optimized by exploring the use of different musical features as the input. Both high level features, i.e., musically meaningful features, as well as low level features, i.e., spectrogram based features, were extracted from the audio files so as to optimize the performance of the different classification models.
Singing Voice Conversion with Disentangled Representations of Singer and Vocal Technique Using Variational Autoencoders
Jan 28, 2020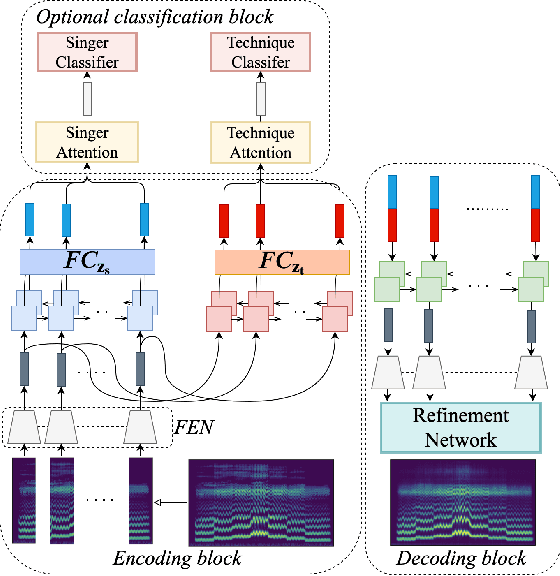

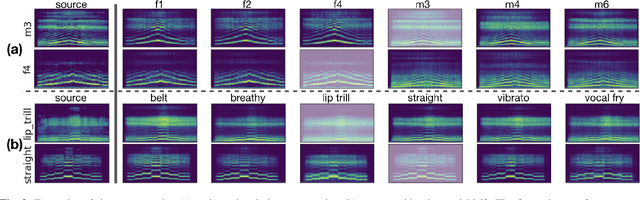
We propose a flexible framework that deals with both singer conversion and singers vocal technique conversion. The proposed model is trained on non-parallel corpora, accommodates many-to-many conversion, and leverages recent advances of variational autoencoders. It employs separate encoders to learn disentangled latent representations of singer identity and vocal technique separately, with a joint decoder for reconstruction. Conversion is carried out by simple vector arithmetic in the learned latent spaces. Both a quantitative analysis as well as a visualization of the converted spectrograms show that our model is able to disentangle singer identity and vocal technique and successfully perform conversion of these attributes. To the best of our knowledge, this is the first work to jointly tackle conversion of singer identity and vocal technique based on a deep learning approach.
nnAudio: An on-the-fly GPU Audio to Spectrogram Conversion Toolbox Using 1D Convolution Neural Networks
Dec 31, 2019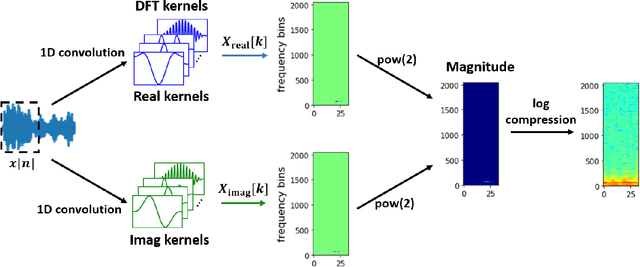


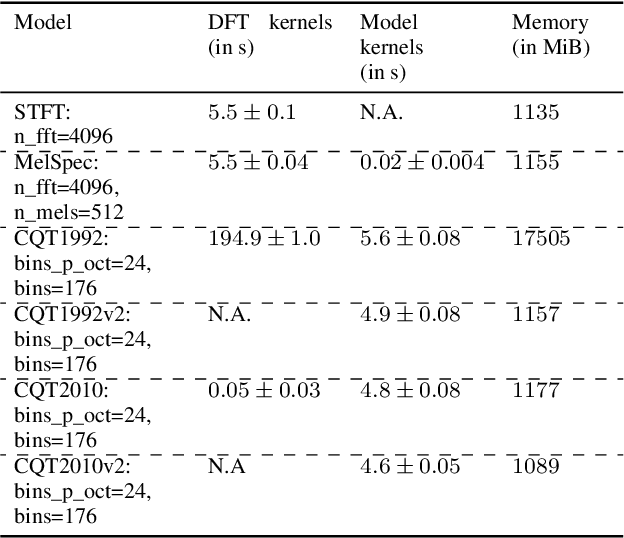
Converting time domain waveforms to frequency domain spectrograms is typically considered to be a prepossessing step done before model training. This approach, however, has several drawbacks. First, it takes a lot of hard disk space to store different frequency domain representations. This is especially true during the model development and tuning process, when exploring various types of spectrograms for optimal performance. Second, if another dataset is used, one must process all the audio clips again before the network can be retrained. In this paper, we integrate the time domain to frequency domain conversion as part of the model structure, and propose a neural network based toolbox, nnAudio, which leverages 1D convolutional neural networks to perform time domain to frequency domain conversion during feed-forward. It allows on-the-fly spectrogram generation without the need to store any spectrograms on the disk. This approach also allows back-propagation on the waveforms-to-spectrograms transformation layer, which implies that this transformation process can be made trainable, and hence further optimized by gradient descent. nnAudio reduces the waveforms-to-spectrograms conversion time for 1,770 waveforms (from the MAPS dataset) from $10.64$ seconds with librosa to only $0.001$ seconds for Short-Time Fourier Transform (STFT), $18.3$ seconds to $0.015$ seconds for Mel spectrogram, $103.4$ seconds to $0.258$ for constant-Q transform (CQT), when using GPU on our DGX work station with CPU: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz Tesla v100 32Gb GPUs. (Only 1 GPU is being used for all the experiments.) We also further optimize the existing CQT algorithm, so that the CQT spectrogram can be obtained without aliasing in a much faster computation time (from $0.258$ seconds to only $0.001$ seconds).
Learning Disentangled Representations of Timbre and Pitch for Musical Instrument Sounds Using Gaussian Mixture Variational Autoencoders
Jun 29, 2019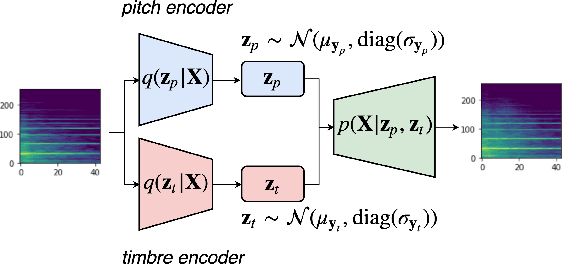
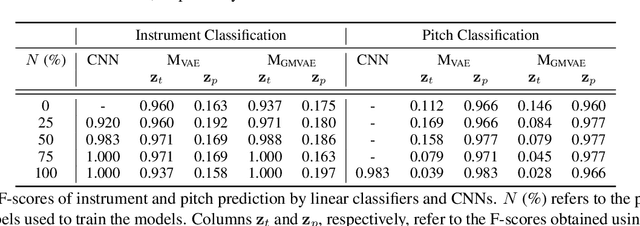

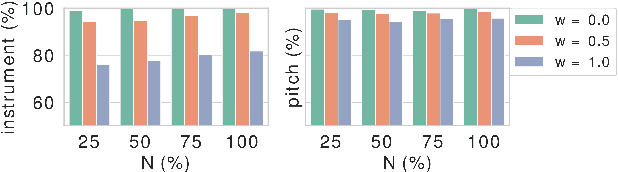
In this paper, we learn disentangled representations of timbre and pitch for musical instrument sounds. We adapt a framework based on variational autoencoders with Gaussian mixture latent distributions. Specifically, we use two separate encoders to learn distinct latent spaces for timbre and pitch, which form Gaussian mixture components representing instrument identity and pitch, respectively. For reconstruction, latent variables of timbre and pitch are sampled from corresponding mixture components, and are concatenated as the input to a decoder. We show the model efficacy by latent space visualization, and a quantitative analysis indicates the discriminability of these spaces, even with a limited number of instrument labels for training. The model allows for controllable synthesis of selected instrument sounds by sampling from the latent spaces. To evaluate this, we trained instrument and pitch classifiers using original labeled data. These classifiers achieve high accuracy when tested on our synthesized sounds, which verifies the model performance of controllable realistic timbre and pitch synthesis. Our model also enables timbre transfer between multiple instruments, with a single autoencoder architecture, which is evaluated by measuring the shift in posterior of instrument classification. Our in depth evaluation confirms the model ability to successfully disentangle timbre and pitch.
From Context to Concept: Exploring Semantic Relationships in Music with Word2Vec
Nov 29, 2018

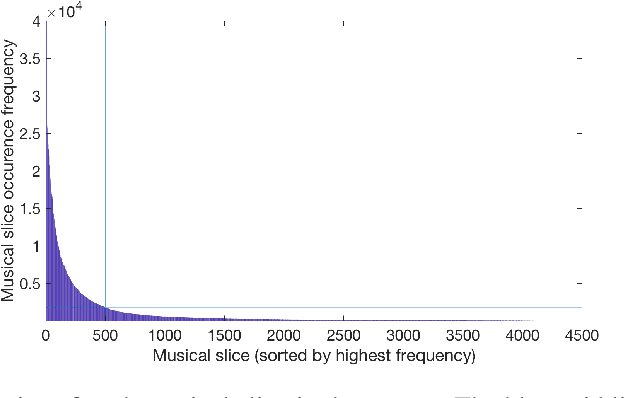
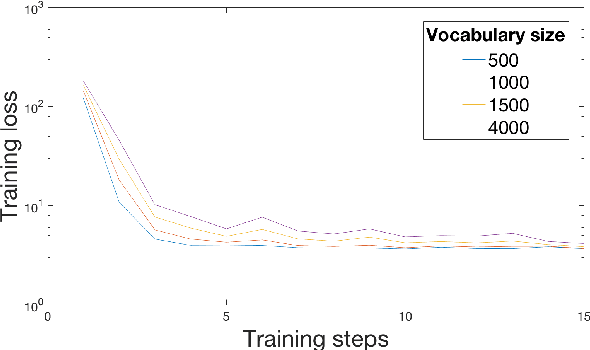
We explore the potential of a popular distributional semantics vector space model, word2vec, for capturing meaningful relationships in ecological (complex polyphonic) music. More precisely, the skip-gram version of word2vec is used to model slices of music from a large corpus spanning eight musical genres. In this newly learned vector space, a metric based on cosine distance is able to distinguish between functional chord relationships, as well as harmonic associations in the music. Evidence, based on cosine distance between chord-pair vectors, suggests that an implicit circle-of-fifths exists in the vector space. In addition, a comparison between pieces in different keys reveals that key relationships are represented in word2vec space. These results suggest that the newly learned embedded vector representation does in fact capture tonal and harmonic characteristics of music, without receiving explicit information about the musical content of the constituent slices. In order to investigate whether proximity in the discovered space of embeddings is indicative of `semantically-related' slices, we explore a music generation task, by automatically replacing existing slices from a given piece of music with new slices. We propose an algorithm to find substitute slices based on spatial proximity and the pitch class distribution inferred in the chosen subspace. The results indicate that the size of the subspace used has a significant effect on whether slices belonging to the same key are selected. In sum, the proposed word2vec model is able to learn music-vector embeddings that capture meaningful tonal and harmonic relationships in music, thereby providing a useful tool for exploring musical properties and comparisons across pieces, as a potential input representation for deep learning models, and as a music generation device.
* Accepted for publication in Neural Computing and Applications, Springer. In Press
From Bach to the Beatles: The simulation of human tonal expectation using ecologically-trained predictive models
Jul 19, 2017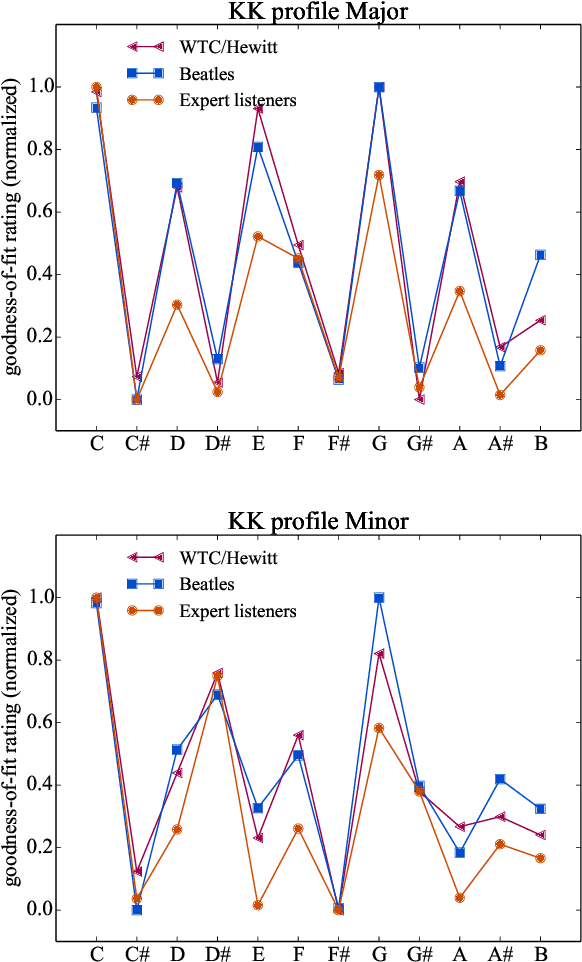

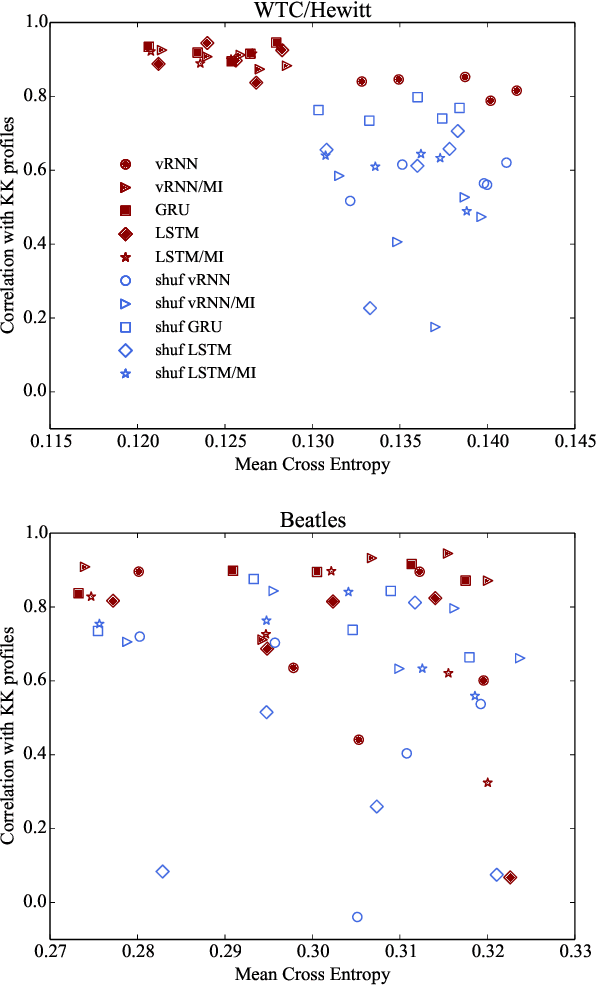
Tonal structure is in part conveyed by statistical regularities between musical events, and research has shown that computational models reflect tonal structure in music by capturing these regularities in schematic constructs like pitch histograms. Of the few studies that model the acquisition of perceptual learning from musical data, most have employed self-organizing models that learn a topology of static descriptions of musical contexts. Also, the stimuli used to train these models are often symbolic rather than acoustically faithful representations of musical material. In this work we investigate whether sequential predictive models of musical memory (specifically, recurrent neural networks), trained on audio from commercial CD recordings, induce tonal knowledge in a similar manner to listeners (as shown in behavioral studies in music perception). Our experiments indicate that various types of recurrent neural networks produce musical expectations that clearly convey tonal structure. Furthermore, the results imply that although implicit knowledge of tonal structure is a necessary condition for accurate musical expectation, the most accurate predictive models also use other cues beyond the tonal structure of the musical context.