 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay (Cross) Attention to the Melody: Curriculum Masking for Single-Encoder Melodic Harmonization
Jan 22, 2026Melodic harmonization, the task of generating harmonic accompaniments for a given melody, remains a central challenge in computational music generation. Recent single encoder transformer approaches have framed harmonization as a masked sequence modeling problem, but existing training curricula inspired by discrete diffusion often result in weak (cross) attention between melody and harmony. This leads to limited exploitation of melodic cues, particularly in out-of-domain contexts. In this work, we introduce a training curriculum, FF (full-to-full), which keeps all harmony tokens masked for several training steps before progressively unmasking entire sequences during training to strengthen melody-harmony interactions. We systematically evaluate this approach against prior curricula across multiple experimental axes, including temporal quantization (quarter vs. sixteenth note), bar-level vs. time-signature conditioning, melody representation (full range vs. pitch class), and inference-time unmasking strategies. Models are trained on the HookTheory dataset and evaluated both in-domain and on a curated collection of jazz standards, using a comprehensive set of metrics that assess chord progression structure, harmony-melody alignment, and rhythmic coherence. Results demonstrate that the proposed FF curriculum consistently outperforms baselines in nearly all metrics, with particularly strong gains in out-of-domain evaluations where harmonic adaptability to novel melodic queues is crucial. We further find that quarter-note quantization, intertwining of bar tokens, and pitch-class melody representations are advantageous in the FF setting. Our findings highlight the importance of training curricula in enabling effective melody conditioning and suggest that full-to-full unmasking offers a robust strategy for single encoder harmonization.
Incorporating Structure and Chord Constraints in Symbolic Transformer-based Melodic Harmonization
Dec 08, 2025Transformer architectures offer significant advantages regarding the generation of symbolic music; their capabilities for incorporating user preferences toward what they generate is being studied under many aspects. This paper studies the inclusion of predefined chord constraints in melodic harmonization, i.e., where a desired chord at a specific location is provided along with the melody as inputs and the autoregressive transformer model needs to incorporate the chord in the harmonization that it generates. The peculiarities of involving such constraints is discussed and an algorithm is proposed for tackling this task. This algorithm is called B* and it combines aspects of beam search and A* along with backtracking to force pretrained transformers to satisfy the chord constraints, at the correct onset position within the correct bar. The algorithm is brute-force and has exponential complexity in the worst case; however, this paper is a first attempt to highlight the difficulties of the problem and proposes an algorithm that offers many possibilities for improvements since it accommodates the involvement of heuristics.
Conditional Drums Generation using Compound Word Representations
Feb 21, 2022
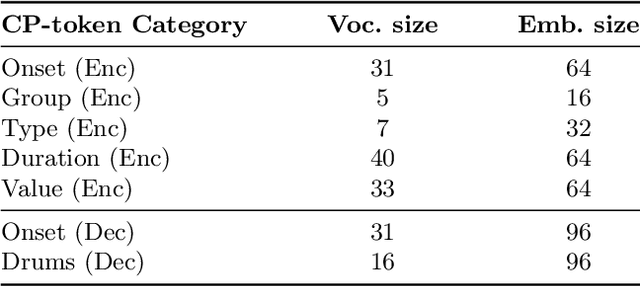
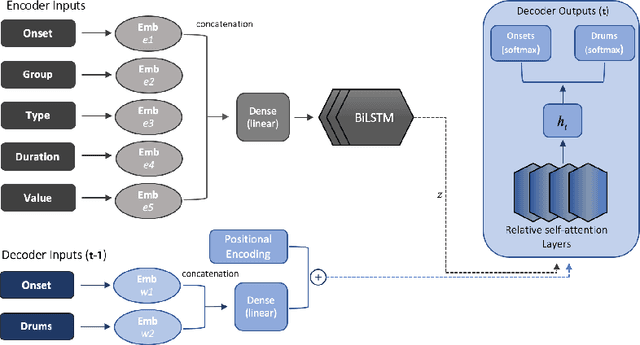
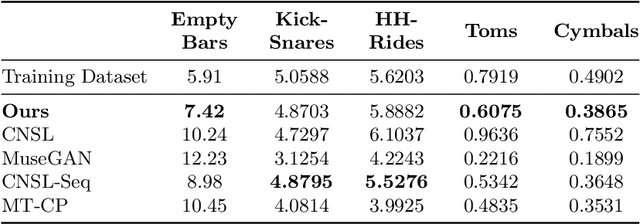
The field of automatic music composition has seen great progress in recent years, specifically with the invention of transformer-based architectures. When using any deep learning model which considers music as a sequence of events with multiple complex dependencies, the selection of a proper data representation is crucial. In this paper, we tackle the task of conditional drums generation using a novel data encoding scheme inspired by the Compound Word representation, a tokenization process of sequential data. Therefore, we present a sequence-to-sequence architecture where a Bidirectional Long short-term memory (BiLSTM) Encoder receives information about the conditioning parameters (i.e., accompanying tracks and musical attributes), while a Transformer-based Decoder with relative global attention produces the generated drum sequences. We conducted experiments to thoroughly compare the effectiveness of our method to several baselines. Quantitative evaluation shows that our model is able to generate drums sequences that have similar statistical distributions and characteristics to the training corpus. These features include syncopation, compression ratio, and symmetry among others. We also verified, through a listening test, that generated drum sequences sound pleasant, natural and coherent while they "groove" with the given accompaniment.
Predicting emotion from music videos: exploring the relative contribution of visual and auditory information to affective responses
Feb 19, 2022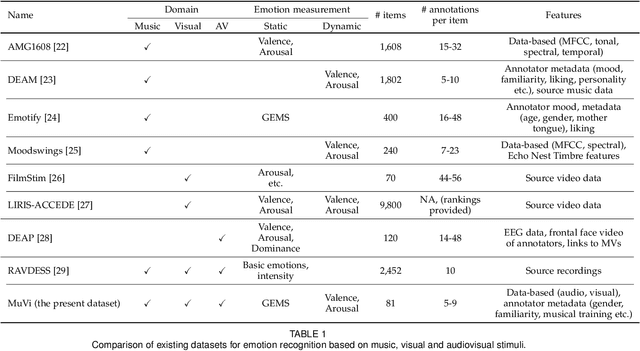

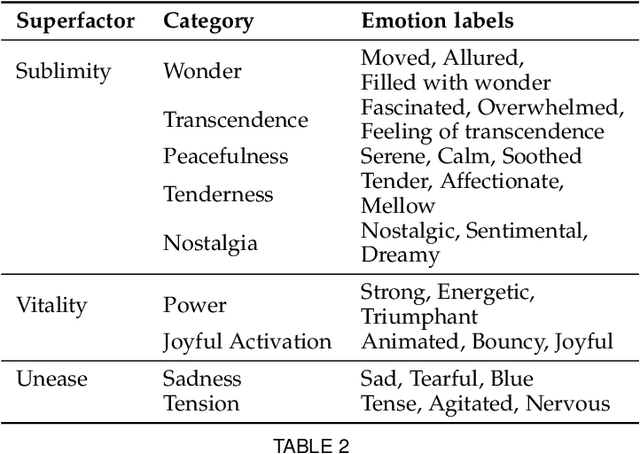
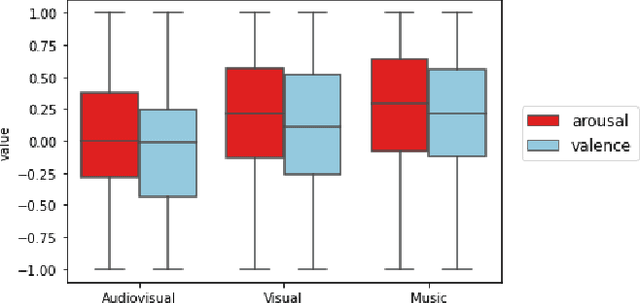
Although media content is increasingly produced, distributed, and consumed in multiple combinations of modalities, how individual modalities contribute to the perceived emotion of a media item remains poorly understood. In this paper we present MusicVideos (MuVi), a novel dataset for affective multimedia content analysis to study how the auditory and visual modalities contribute to the perceived emotion of media. The data were collected by presenting music videos to participants in three conditions: music, visual, and audiovisual. Participants annotated the music videos for valence and arousal over time, as well as the overall emotion conveyed. We present detailed descriptive statistics for key measures in the dataset and the results of feature importance analyses for each condition. Finally, we propose a novel transfer learning architecture to train Predictive models Augmented with Isolated modality Ratings (PAIR) and demonstrate the potential of isolated modality ratings for enhancing multimodal emotion recognition. Our results suggest that perceptions of arousal are influenced primarily by auditory information, while perceptions of valence are more subjective and can be influenced by both visual and auditory information. The dataset is made publicly available.
Generating Lead Sheets with Affect: A Novel Conditional seq2seq Framework
Apr 27, 2021
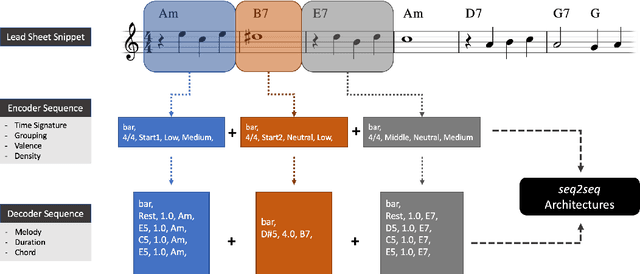
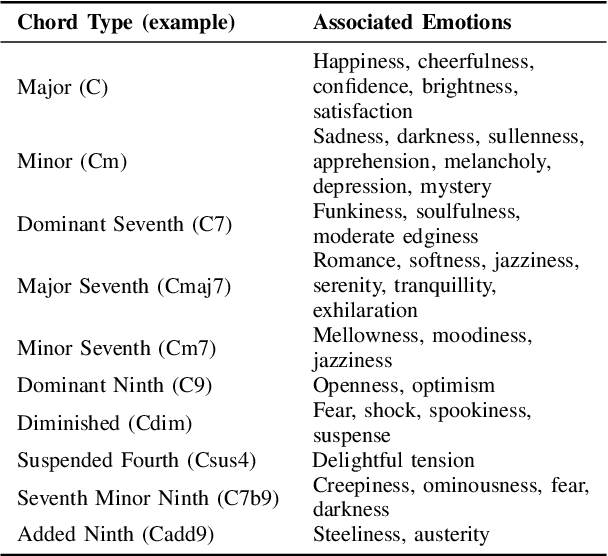
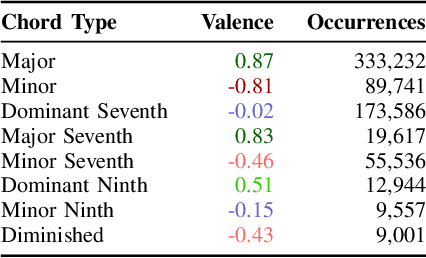
The field of automatic music composition has seen great progress in the last few years, much of which can be attributed to advances in deep neural networks. There are numerous studies that present different strategies for generating sheet music from scratch. The inclusion of high-level musical characteristics (e.g., perceived emotional qualities), however, as conditions for controlling the generation output remains a challenge. In this paper, we present a novel approach for calculating the valence (the positivity or negativity of the perceived emotion) of a chord progression within a lead sheet, using pre-defined mood tags proposed by music experts. Based on this approach, we propose a novel strategy for conditional lead sheet generation that allows us to steer the music generation in terms of valence, phrasing, and time signature. Our approach is similar to a Neural Machine Translation (NMT) problem, as we include high-level conditions in the encoder part of the sequence-to-sequence architectures used (i.e., long-short term memory networks, and a Transformer network). We conducted experiments to thoroughly analyze these two architectures. The results show that the proposed strategy is able to generate lead sheets in a controllable manner, resulting in distributions of musical attributes similar to those of the training dataset. We also verified through a subjective listening test that our approach is effective in controlling the valence of a generated chord progression.
DeepDrum: An Adaptive Conditional Neural Network
Sep 17, 2018
Considering music as a sequence of events with multiple complex dependencies, the Long Short-Term Memory (LSTM) architecture has proven very efficient in learning and reproducing musical styles. However, the generation of rhythms requires additional information regarding musical structure and accompanying instruments. In this paper we present DeepDrum, an adaptive Neural Network capable of generating drum rhythms under constraints imposed by Feed-Forward (Conditional) Layers which contain musical parameters along with given instrumentation information (e.g. bass and guitar notes). Results on generated drum sequences are presented indicating that DeepDrum is effective in producing rhythms that resemble the learned style, while at the same time conforming to given constraints that were unknown during the training process.