 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Significance Testing in Information Retrieval: An Empirical Analysis of Type I, Type II and Type III Errors
Jun 05, 2019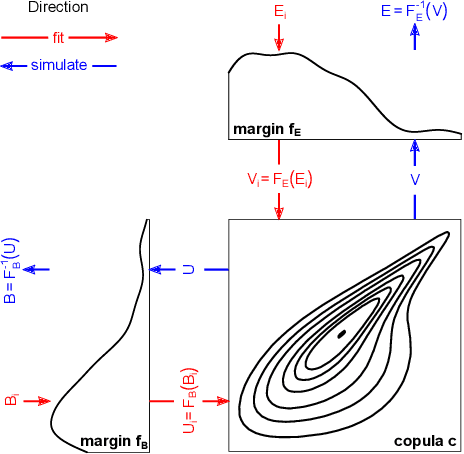
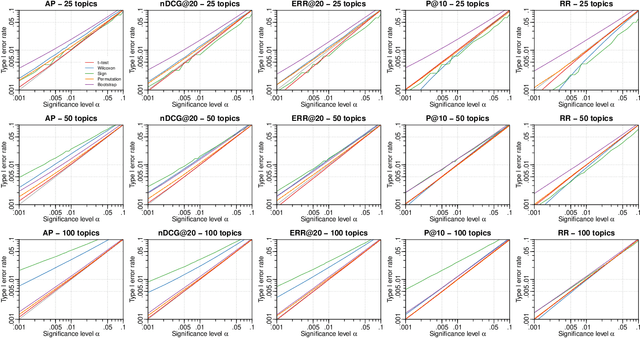

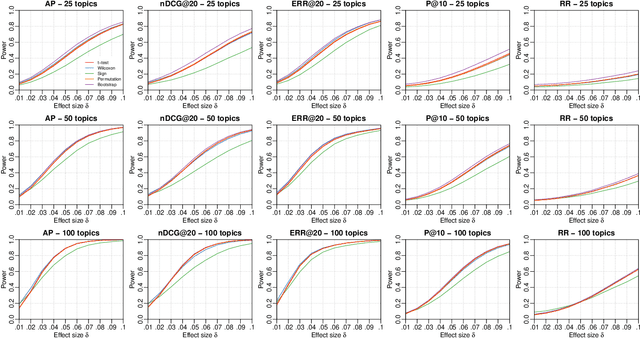
Statistical significance testing is widely accepted as a means to assess how well a difference in effectiveness reflects an actual difference between systems, as opposed to random noise because of the selection of topics. According to recent surveys on SIGIR, CIKM, ECIR and TOIS papers, the t-test is the most popular choice among IR researchers. However, previous work has suggested computer intensive tests like the bootstrap or the permutation test, based mainly on theoretical arguments. On empirical grounds, others have suggested non-parametric alternatives such as the Wilcoxon test. Indeed, the question of which tests we should use has accompanied IR and related fields for decades now. Previous theoretical studies on this matter were limited in that we know that test assumptions are not met in IR experiments, and empirical studies were limited in that we do not have the necessary control over the null hypotheses to compute actual Type I and Type II error rates under realistic conditions. Therefore, not only is it unclear which test to use, but also how much trust we should put in them. In contrast to past studies, in this paper we employ a recent simulation methodology from TREC data to go around these limitations. Our study comprises over 500 million p-values computed for a range of tests, systems, effectiveness measures, topic set sizes and effect sizes, and for both the 2-tail and 1-tail cases. Having such a large supply of IR evaluation data with full knowledge of the null hypotheses, we are finally in a position to evaluate how well statistical significance tests really behave with IR data, and make sound recommendations for practitioners.