 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Training: Teaching Models Plausible and Actionable Explanations
Jan 22, 2026We propose a novel training regime termed counterfactual training that leverages counterfactual explanations to increase the explanatory capacity of models. Counterfactual explanations have emerged as a popular post-hoc explanation method for opaque machine learning models: they inform how factual inputs would need to change in order for a model to produce some desired output. To be useful in real-world decision-making systems, counterfactuals should be plausible with respect to the underlying data and actionable with respect to the feature mutability constraints. Much existing research has therefore focused on developing post-hoc methods to generate counterfactuals that meet these desiderata. In this work, we instead hold models directly accountable for the desired end goal: counterfactual training employs counterfactuals during the training phase to minimize the divergence between learned representations and plausible, actionable explanations. We demonstrate empirically and theoretically that our proposed method facilitates training models that deliver inherently desirable counterfactual explanations and additionally exhibit improved adversarial robustness.
Red Teaming for Large Language Models At Scale: Tackling Hallucinations on Mathematics Tasks
Dec 30, 2023We consider the problem of red teaming LLMs on elementary calculations and algebraic tasks to evaluate how various prompting techniques affect the quality of outputs. We present a framework to procedurally generate numerical questions and puzzles, and compare the results with and without the application of several red teaming techniques. Our findings suggest that even though structured reasoning and providing worked-out examples slow down the deterioration of the quality of answers, the gpt-3.5-turbo and gpt-4 models are not well suited for elementary calculations and reasoning tasks, also when being red teamed.
Endogenous Macrodynamics in Algorithmic Recourse
Aug 16, 2023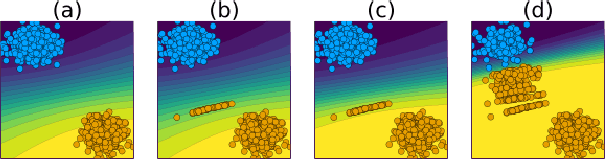
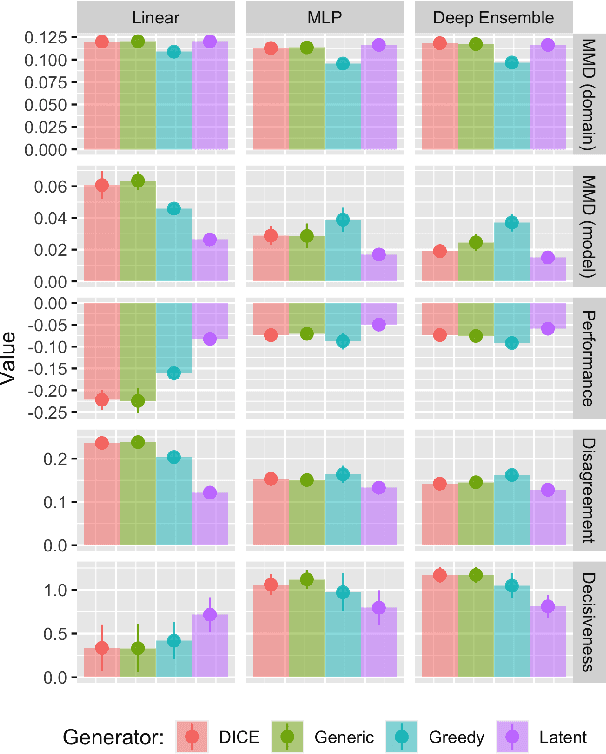
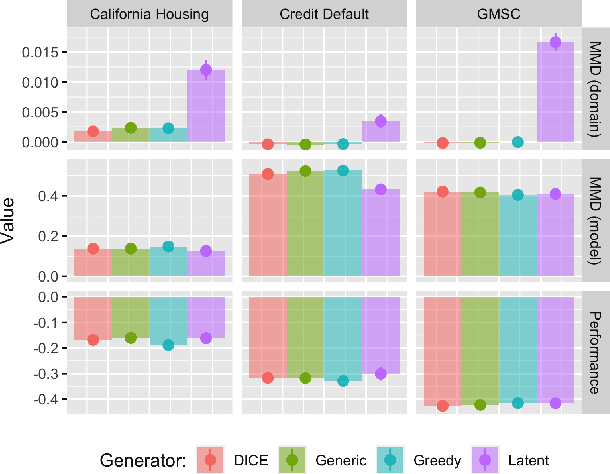
Existing work on Counterfactual Explanations (CE) and Algorithmic Recourse (AR) has largely focused on single individuals in a static environment: given some estimated model, the goal is to find valid counterfactuals for an individual instance that fulfill various desiderata. The ability of such counterfactuals to handle dynamics like data and model drift remains a largely unexplored research challenge. There has also been surprisingly little work on the related question of how the actual implementation of recourse by one individual may affect other individuals. Through this work, we aim to close that gap. We first show that many of the existing methodologies can be collectively described by a generalized framework. We then argue that the existing framework does not account for a hidden external cost of recourse, that only reveals itself when studying the endogenous dynamics of recourse at the group level. Through simulation experiments involving various state-of the-art counterfactual generators and several benchmark datasets, we generate large numbers of counterfactuals and study the resulting domain and model shifts. We find that the induced shifts are substantial enough to likely impede the applicability of Algorithmic Recourse in some situations. Fortunately, we find various strategies to mitigate these concerns. Our simulation framework for studying recourse dynamics is fast and opensourced.
* 12 pages, 11 figures. Originally published at the 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE holds the copyright