 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Sybil: Explaining Deep Lung Cancer Risk Prediction Through Generative Interventional Attributions
Jan 30, 2026Lung cancer remains the leading cause of cancer mortality, driving the development of automated screening tools to alleviate radiologist workload. Standing at the frontier of this effort is Sybil, a deep learning model capable of predicting future risk solely from computed tomography (CT) with high precision. However, despite extensive clinical validation, current assessments rely purely on observational metrics. This correlation-based approach overlooks the model's actual reasoning mechanism, necessitating a shift to causal verification to ensure robust decision-making before clinical deployment. We propose S(H)NAP, a model-agnostic auditing framework that constructs generative interventional attributions validated by expert radiologists. By leveraging realistic 3D diffusion bridge modeling to systematically modify anatomical features, our approach isolates object-specific causal contributions to the risk score. Providing the first interventional audit of Sybil, we demonstrate that while the model often exhibits behavior akin to an expert radiologist, differentiating malignant pulmonary nodules from benign ones, it suffers from critical failure modes, including dangerous sensitivity to clinically unjustified artifacts and a distinct radial bias.
Red Teaming for Large Language Models At Scale: Tackling Hallucinations on Mathematics Tasks
Dec 30, 2023We consider the problem of red teaming LLMs on elementary calculations and algebraic tasks to evaluate how various prompting techniques affect the quality of outputs. We present a framework to procedurally generate numerical questions and puzzles, and compare the results with and without the application of several red teaming techniques. Our findings suggest that even though structured reasoning and providing worked-out examples slow down the deterioration of the quality of answers, the gpt-3.5-turbo and gpt-4 models are not well suited for elementary calculations and reasoning tasks, also when being red teamed.
Endogenous Macrodynamics in Algorithmic Recourse
Aug 16, 2023
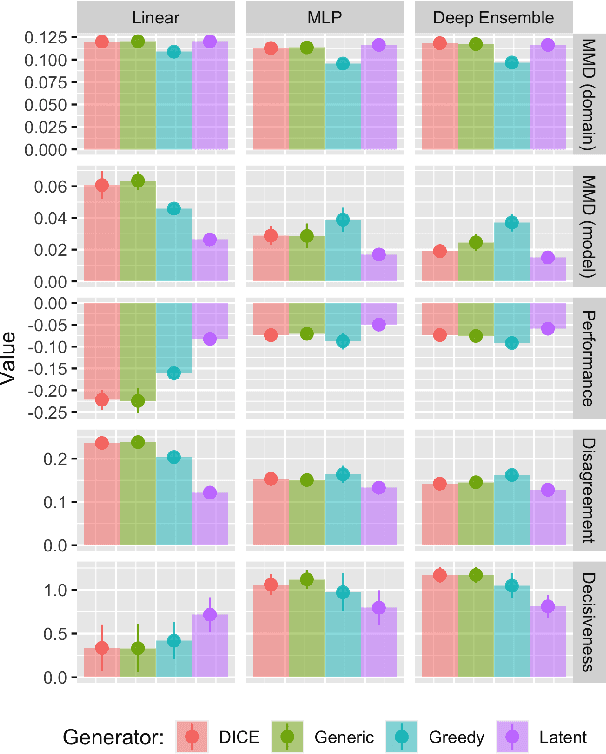
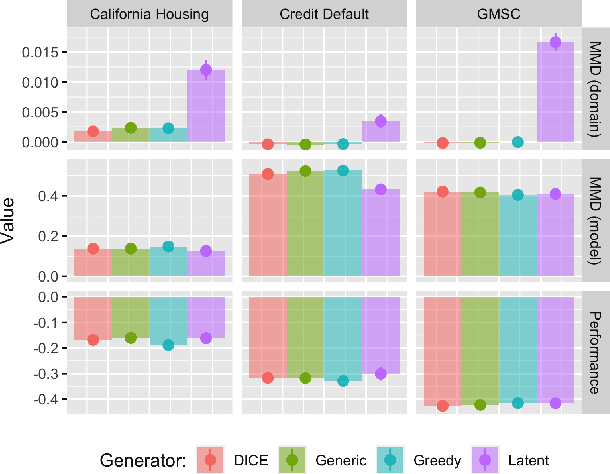
Existing work on Counterfactual Explanations (CE) and Algorithmic Recourse (AR) has largely focused on single individuals in a static environment: given some estimated model, the goal is to find valid counterfactuals for an individual instance that fulfill various desiderata. The ability of such counterfactuals to handle dynamics like data and model drift remains a largely unexplored research challenge. There has also been surprisingly little work on the related question of how the actual implementation of recourse by one individual may affect other individuals. Through this work, we aim to close that gap. We first show that many of the existing methodologies can be collectively described by a generalized framework. We then argue that the existing framework does not account for a hidden external cost of recourse, that only reveals itself when studying the endogenous dynamics of recourse at the group level. Through simulation experiments involving various state-of the-art counterfactual generators and several benchmark datasets, we generate large numbers of counterfactuals and study the resulting domain and model shifts. We find that the induced shifts are substantial enough to likely impede the applicability of Algorithmic Recourse in some situations. Fortunately, we find various strategies to mitigate these concerns. Our simulation framework for studying recourse dynamics is fast and opensourced.
* 12 pages, 11 figures. Originally published at the 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE holds the copyright