 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Stance Detection Topic-Independent and Cross-topic Generalizable? -- A Reproduction Study
Oct 14, 2021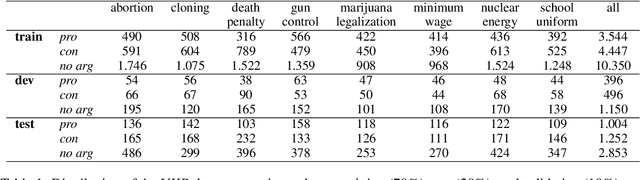
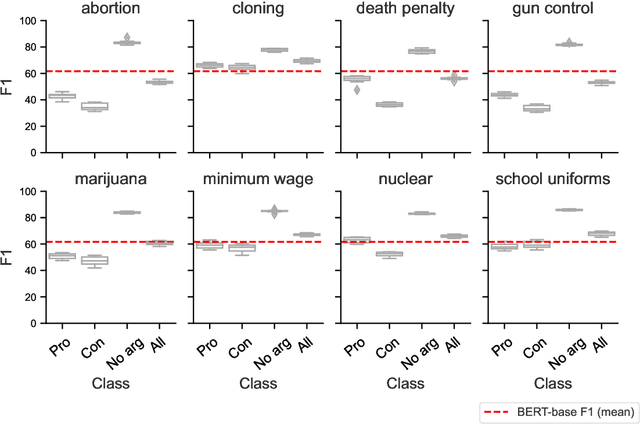
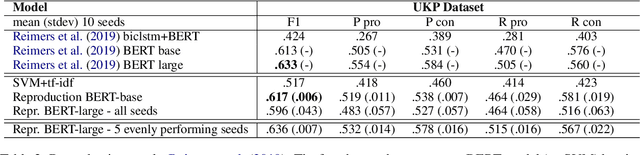

Cross-topic stance detection is the task to automatically detect stances (pro, against, or neutral) on unseen topics. We successfully reproduce state-of-the-art cross-topic stance detection work (Reimers et. al., 2019), and systematically analyze its reproducibility. Our attention then turns to the cross-topic aspect of this work, and the specificity of topics in terms of vocabulary and socio-cultural context. We ask: To what extent is stance detection topic-independent and generalizable across topics? We compare the model's performance on various unseen topics, and find topic (e.g. abortion, cloning), class (e.g. pro, con), and their interaction affecting the model's performance. We conclude that investigating performance on different topics, and addressing topic-specific vocabulary and context, is a future avenue for cross-topic stance detection.
Provenance for Linguistic Corpora Through Nanopublications
Jun 11, 2020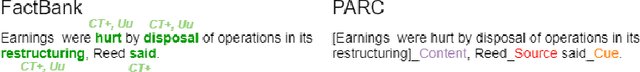
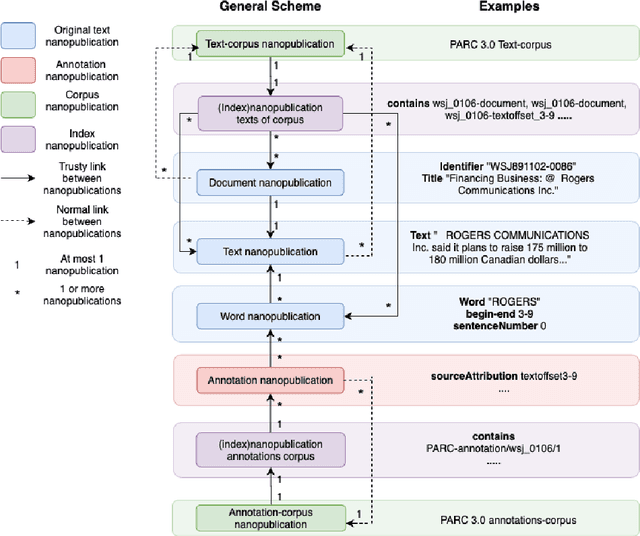
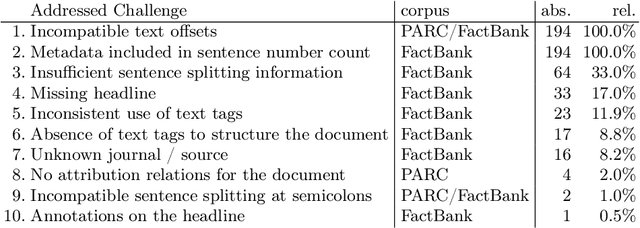
Research in Computational Linguistics is dependent on text corpora for training and testing new tools and methodologies. While there exists a plethora of annotated linguistic information, these corpora are often not interoperable without significant manual work. Moreover, these annotations might have adapted and might have evolved into different versions, making it challenging for researchers to know the data's provenance and merge it with other annotated corpora. In other words, these variations affect the interoperability between existing corpora. This paper addresses this issue with a case study on event annotated corpora and by creating a new, more interoperable representation of this data in the form of nanopublications. We demonstrate how linguistic annotations from separate corpora can be merged through a similar format to thereby make annotation content simultaneously accessible. The process for developing the nanopublications is described, and SPARQL queries are performed to extract interesting content from the new representations. The queries show that information of multiple corpora can now be retrieved more easily and effectively with the automated interoperability of the information of different corpora in a uniform data format.
Pragmatic factors in image description: the case of negations
Jun 27, 2016
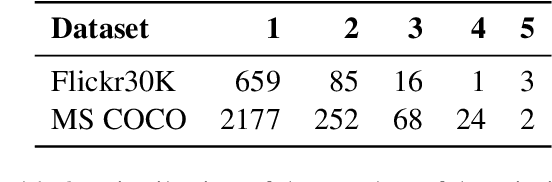

We provide a qualitative analysis of the descriptions containing negations (no, not, n't, nobody, etc) in the Flickr30K corpus, and a categorization of negation uses. Based on this analysis, we provide a set of requirements that an image description system should have in order to generate negation sentences. As a pilot experiment, we used our categorization to manually annotate sentences containing negations in the Flickr30K corpus, with an agreement score of K=0.67. With this paper, we hope to open up a broader discussion of subjective language in image descriptions.