 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurocomputational Mechanisms of Syntactic Transfer in Bilingual Sentence Production
Jan 26, 2026We discuss the benefits of incorporating into the study of bilingual production errors and their traditionally documented timing signatures (e.g., event-related potentials) certain types of oscillatory signatures, which can offer new implementational-level constraints for theories of bilingualism. We argue that a recent neural model of language, ROSE, can offer a neurocomputational account of syntactic transfer in bilingual production, capturing some of its formal properties and the scope of morphosyntactic sequencing failure modes. We take as a case study cross-linguistic influence (CLI) and attendant theories of functional inhibition/competition, and present these as being driven by specific oscillatory failure modes during L2 sentence planning. We argue that modeling CLI in this way not only offers the kind of linking hypothesis ROSE was built to encourage, but also licenses the exploration of more spatiotemporally complex biomarkers of language dysfunction than more commonly discussed neural signatures.
Turkish Native Language Identification
Aug 04, 2023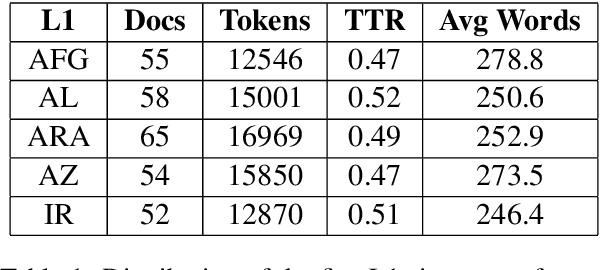
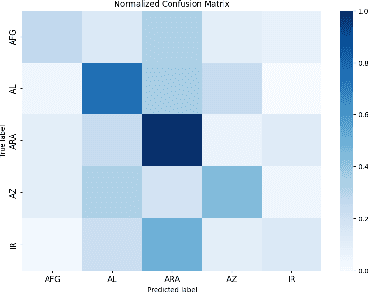
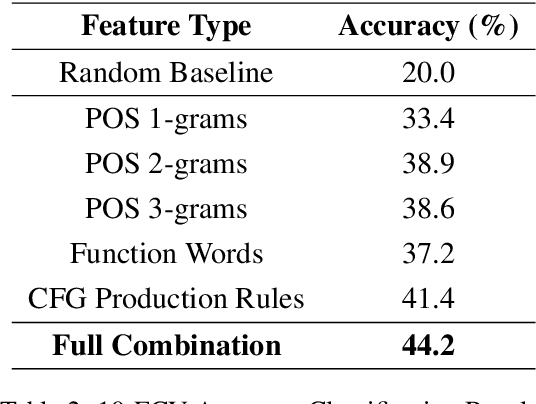
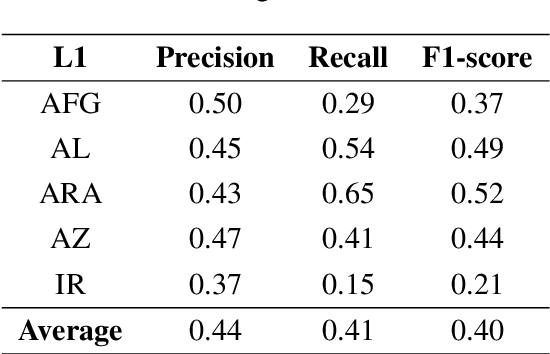
In this paper, we present the first application of Native Language Identification (NLI) for the Turkish language. NLI involves predicting the writer's first language by analysing their writing in different languages. While most NLI research has focused on English, our study extends its scope to Turkish. We used the recently constructed Turkish Learner Corpus and employed a combination of three syntactic features (CFG production rules, part-of-speech n-grams, and function words) with L2 texts to demonstrate their effectiveness in this task.
Exploring Hybrid Linguistic Features for Turkish Text Readability
Jun 25, 2023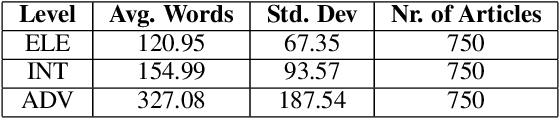
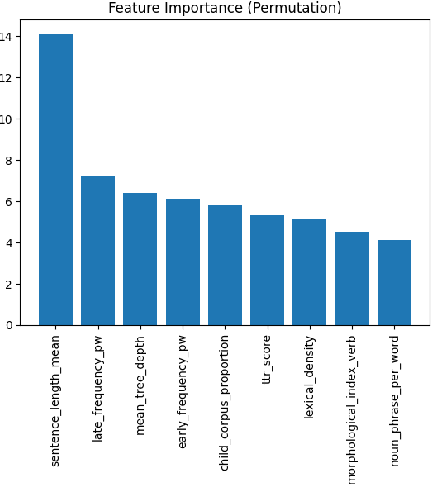
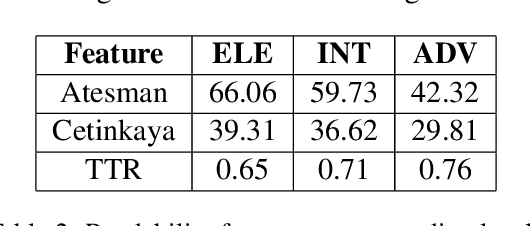
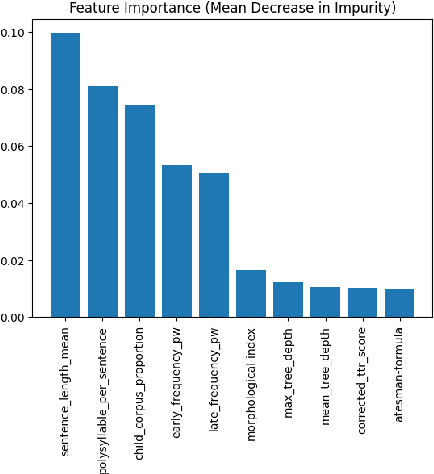
This paper presents the first comprehensive study on automatic readability assessment of Turkish texts. We combine state-of-the-art neural network models with linguistic features at lexical, morphosyntactic, syntactic and discourse levels to develop an advanced readability tool. We evaluate the effectiveness of traditional readability formulas compared to modern automated methods and identify key linguistic features that determine the readability of Turkish texts.
Scaling Native Language Identification with Transformer Adapters
Nov 18, 2022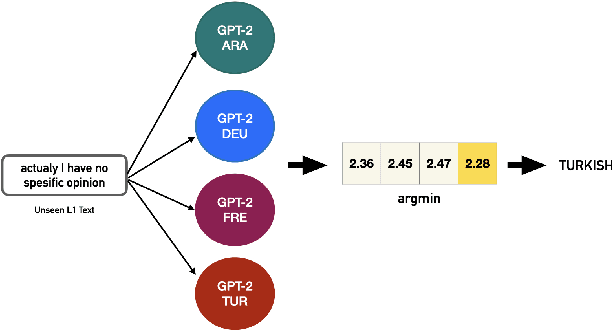
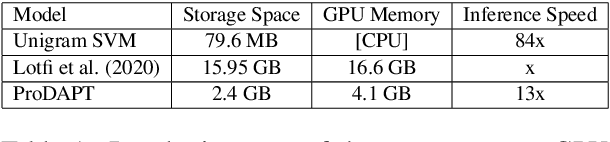
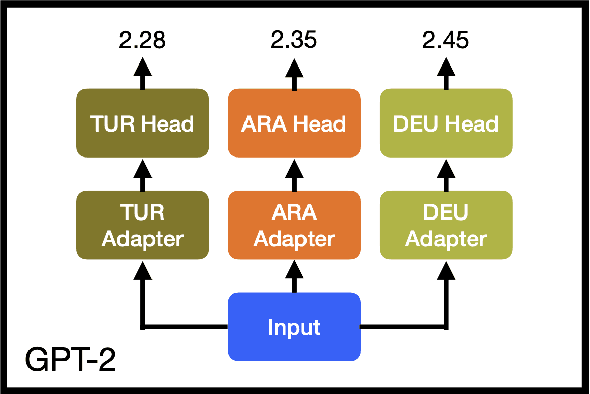
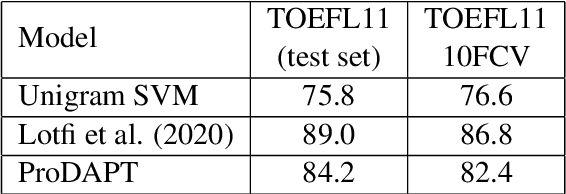
Native language identification (NLI) is the task of automatically identifying the native language (L1) of an individual based on their language production in a learned language. It is useful for a variety of purposes including marketing, security and educational applications. NLI is usually framed as a multi-label classification task, where numerous designed features are combined to achieve state-of-the-art results. Recently deep generative approach based on transformer decoders (GPT-2) outperformed its counterparts and achieved the best results on the NLI benchmark datasets. We investigate this approach to determine the practical implications compared to traditional state-of-the-art NLI systems. We introduce transformer adapters to address memory limitations and improve training/inference speed to scale NLI applications for production.
Automatic Lexical Simplification for Turkish
Jan 24, 2022
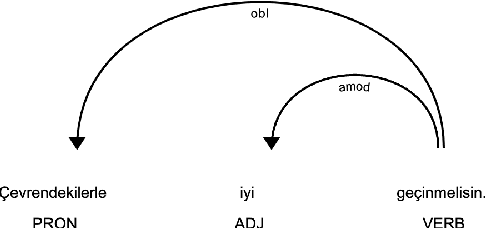
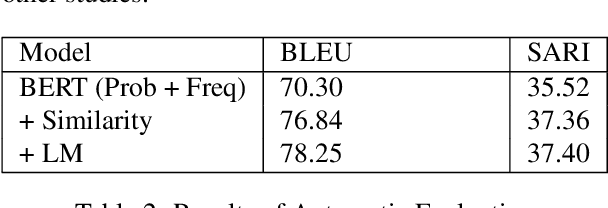
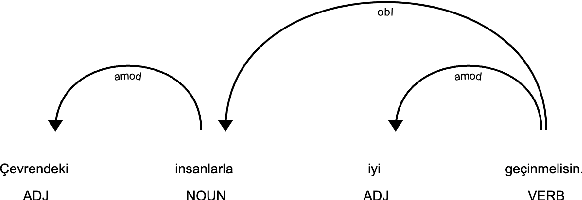
In this paper, we present the first automatic lexical simplification system for the Turkish language. Recent text simplification efforts rely on manually crafted simplified corpora and comprehensive NLP tools that can analyse the target text both in word and sentence levels. Turkish is a morphologically rich agglutinative language that requires unique considerations such as the proper handling of inflectional cases. Being a low-resource language in terms of available resources and industrial-strength tools, it makes the text simplification task harder to approach. We present a new text simplification pipeline based on pretrained representation model BERT together with morphological features to generate grammatically correct and semantically appropriate word-level simplifications.
Hocalarim: Mining Turkish Student Reviews
Sep 06, 2021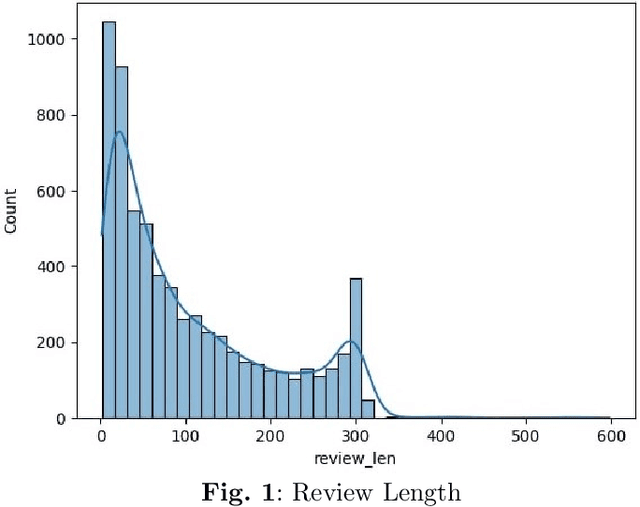
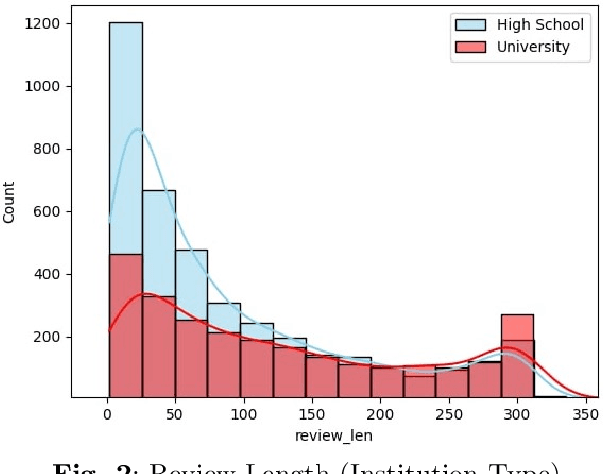
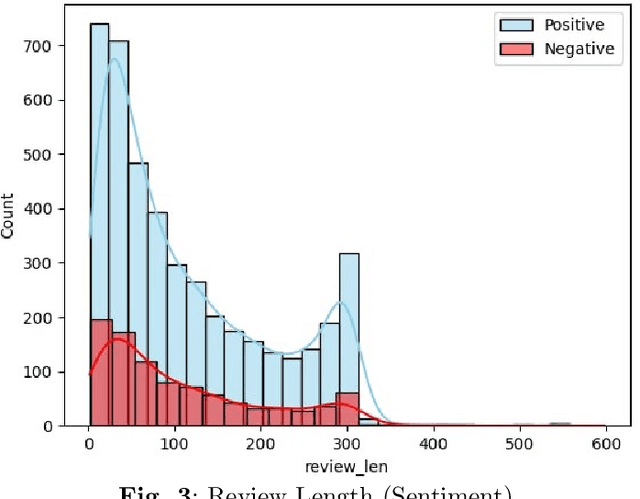
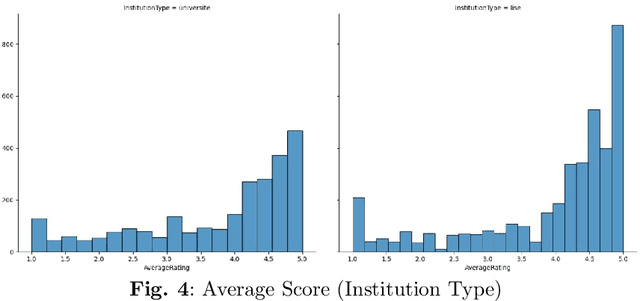
We introduce Hocalarim (MyProfessors), the largest student review dataset available for the Turkish language. It consists of over 5000 professor reviews left online by students, with different aspects of education rated on a scale of 1 to 5 stars. We investigate the properties of the dataset and present its statistics. We examine the impact of students' institution type on their ratings and the correlation of students' bias to give positive or negative feedback.