 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGSM-Pro: A Simple Strategy for Robust Multilingual Mathematical Reasoning Evaluation
Jan 29, 2026Large language models have made substantial progress in mathematical reasoning. However, benchmark development for multilingual evaluation has lagged behind English in both difficulty and recency. Recently, GSM-Symbolic showed a strong evidence of high variance when models are evaluated on different instantiations of the same question; however, the evaluation was conducted only in English. In this paper, we introduce MGSM-Pro, an extension of MGSM dataset with GSM-Symbolic approach. Our dataset provides five instantiations per MGSM question by varying names, digits and irrelevant context. Evaluations across nine languages reveal that many low-resource languages suffer large performance drops when tested on digit instantiations different from those in the original test set. We further find that some proprietary models, notably Gemini 2.5 Flash and GPT-4.1, are less robust to digit instantiation, whereas Claude 4.0 Sonnet is more robust. Among open models, GPT-OSS 120B and DeepSeek V3 show stronger robustness. Based on these findings, we recommend evaluating each problem using at least five digit-varying instantiations to obtain a more robust and realistic assessment of math reasoning.
Exploring Cultural Nuances in Emotion Perception Across 15 African Languages
Mar 25, 2025Understanding how emotions are expressed across languages is vital for building culturally-aware and inclusive NLP systems. However, emotion expression in African languages is understudied, limiting the development of effective emotion detection tools in these languages. In this work, we present a cross-linguistic analysis of emotion expression in 15 African languages. We examine four key dimensions of emotion representation: text length, sentiment polarity, emotion co-occurrence, and intensity variations. Our findings reveal diverse language-specific patterns in emotional expression -- with Somali texts typically longer, while others like IsiZulu and Algerian Arabic show more concise emotional expression. We observe a higher prevalence of negative sentiment in several Nigerian languages compared to lower negativity in languages like IsiXhosa. Further, emotion co-occurrence analysis demonstrates strong cross-linguistic associations between specific emotion pairs (anger-disgust, sadness-fear), suggesting universal psychological connections. Intensity distributions show multimodal patterns with significant variations between language families; Bantu languages display similar yet distinct profiles, while Afroasiatic languages and Nigerian Pidgin demonstrate wider intensity ranges. These findings highlight the need for language-specific approaches to emotion detection while identifying opportunities for transfer learning across related languages.
SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
Evaluating the Capabilities of Large Language Models for Multi-label Emotion Understanding
Dec 17, 2024Large Language Models (LLMs) show promising learning and reasoning abilities. Compared to other NLP tasks, multilingual and multi-label emotion evaluation tasks are under-explored in LLMs. In this paper, we present EthioEmo, a multi-label emotion classification dataset for four Ethiopian languages, namely, Amharic (amh), Afan Oromo (orm), Somali (som), and Tigrinya (tir). We perform extensive experiments with an additional English multi-label emotion dataset from SemEval 2018 Task 1. Our evaluation includes encoder-only, encoder-decoder, and decoder-only language models. We compare zero and few-shot approaches of LLMs to fine-tuning smaller language models. The results show that accurate multi-label emotion classification is still insufficient even for high-resource languages such as English, and there is a large gap between the performance of high-resource and low-resource languages. The results also show varying performance levels depending on the language and model type. EthioEmo is available publicly to further improve the understanding of emotions in language models and how people convey emotions through various languages.
ProverbEval: Exploring LLM Evaluation Challenges for Low-resource Language Understanding
Nov 07, 2024



With the rapid development of evaluation datasets to assess LLMs understanding across a wide range of subjects and domains, identifying a suitable language understanding benchmark has become increasingly challenging. In this work, we explore LLM evaluation challenges for low-resource language understanding and introduce ProverbEval, LLM evaluation benchmark for low-resource languages based on proverbs to focus on low-resource language understanding in culture-specific scenarios. We benchmark various LLMs and explore factors that create variability in the benchmarking process. We observed performance variances of up to 50%, depending on the order in which answer choices were presented in multiple-choice tasks. Native language proverb descriptions significantly improve tasks such as proverb generation, contributing to improved outcomes. Additionally, monolingual evaluations consistently outperformed their cross-lingual counterparts. We argue special attention must be given to the order of choices, choice of prompt language, task variability, and generation tasks when creating LLM evaluation benchmarks.
EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Mar 26, 2024



Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
Enhancing Amharic-LLaMA: Integrating Task Specific and Generative Datasets
Feb 12, 2024Large language models (LLMs) have received a lot of attention in natural language processing (NLP) research because of their exceptional performance in understanding and generating human languages. However, low-resource languages are left behind due to the unavailability of resources. In this work, we focus on enhancing the LLaMA-2-Amharic model by integrating task-specific and generative datasets to improve language model performance for Amharic. We compile an Amharic instruction fine-tuning dataset and fine-tuned LLaMA-2-Amharic model. The fine-tuned model shows promising results in different NLP tasks. We open-source our dataset creation pipeline, instruction datasets, trained models, and evaluation outputs to promote language-specific studies on these models.
Natural Language Processing in Ethiopian Languages: Current State, Challenges, and Opportunities
Mar 25, 2023



This survey delves into the current state of natural language processing (NLP) for four Ethiopian languages: Amharic, Afaan Oromo, Tigrinya, and Wolaytta. Through this paper, we identify key challenges and opportunities for NLP research in Ethiopia. Furthermore, we provide a centralized repository on GitHub that contains publicly available resources for various NLP tasks in these languages. This repository can be updated periodically with contributions from other researchers. Our objective is to identify research gaps and disseminate the information to NLP researchers interested in Ethiopian languages and encourage future research in this domain.
The Effect of Normalization for Bi-directional Amharic-English Neural Machine Translation
Oct 27, 2022

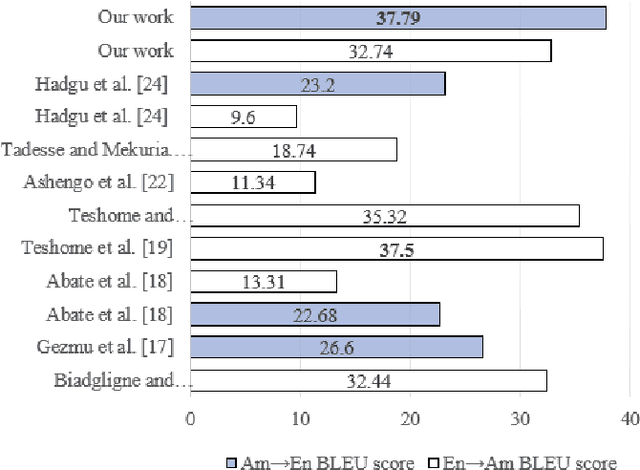

Machine translation (MT) is one of the main tasks in natural language processing whose objective is to translate texts automatically from one natural language to another. Nowadays, using deep neural networks for MT tasks has received great attention. These networks require lots of data to learn abstract representations of the input and store it in continuous vectors. This paper presents the first relatively large-scale Amharic-English parallel sentence dataset. Using these compiled data, we build bi-directional Amharic-English translation models by fine-tuning the existing Facebook M2M100 pre-trained model achieving a BLEU score of 37.79 in Amharic-English 32.74 in English-Amharic translation. Additionally, we explore the effects of Amharic homophone normalization on the machine translation task. The results show that the normalization of Amharic homophone characters increases the performance of Amharic-English machine translation in both directions.